
从PDF中提取不可见行的表格

问题陈述:
我有一个PDF的结构像表格,但行是不可见的。请参阅下面的示例:
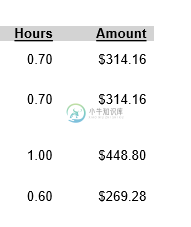
上图是我的表格在其中一个PDF页面中的样子。
我的研究
>
如何使用Python从PDF中提取表作为文本?--看了这道题,看了所有的答案。没有帮助
tabula:尝试了tabula API,但它只是提取标题而不是文本,可能是因为没有行。
我可以将整个pdf转换成文本,然后尝试用regex或数据操作来提取它。但这可能是非常乏味和耗时的。而且,随着PDF的改变,整个编码必须重新进行。
问
他们的API或Python包可以帮助我做到这一点(Windows和Python3.x)吗?
共有1个答案

您需要使用一个软件包,为您提供PDF中文本的X坐标和Y坐标。PyMuPDF或pdfminer将是我的建议。然后,您需要以编程方式确定您遇到的每个文本块在哪一行和哪列中。
-
我正在使用Apache PDFBox从PDF文件中提取页面,我找不到一种方法来提取不可选择的内容(文本或图像)。有了可从PDF文件中选择的内容,就没有问题了。 请注意,所讨论的PDF文件在复制内容方面没有任何限制,至少从我在文件的“文档限制摘要”中看到的是这样的:它们都允许“内容复制”和“内容复制以供访问”!在同一个PDF文件中,有可选择的内容,也有不可选择的其他部分。发生的情况是,提取的页面带有
-
是否可以用开放源码软件库pdfbox提取已签名PDF的可见签名(图像)? 工作流: null 像下面这样的oop风格的东西会很棒: 找到了类PDSignature和如何签署一个PDF,但没有解决方案提取一个可见的签名作为图像。
-
我有(相同的)数据保存为GIF图像文件和PDF文件,我想将其解析为超文本标记语言或XML。这些数据实际上是我大学自助餐厅的菜单。这意味着每周必须解析一个新版本的文件!一般来说,这些文件包含一些页眉和页脚文本,以及中间充满其他数据的表格。我读过一些关于stackoverflow的帖子,我也开始尝试将表格数据解析为超文本语言标记/XML: PDF格式 PDFBox||iText(Java) 谷歌文档导
-
问题内容: 是否有任何支持表识别和提取的开源库? 我的意思是: 识别表结构存在 根据内容对表格进行分类 以有用的输出格式(例如JSON / CSV等)从表中提取数据。 我浏览了有关此主题的类似问题,发现以下内容: PDFMiner解决了问题3,但似乎要求用户向PDFMiner指定每个表都存在表结构的地方(如果我错了,请纠正我) pdf-table-extract尝试解决问题1,但根据“待办事项”列
-
问题内容: 链接到pdf 当我尝试从上面的pdf中提取文本时,我混合了在evince查看器中不可见的文本和可见的文本。此外,某些所需的文本缺少查看器中未缺少的字符,例如“ FALCONS”中的“ S”和许多缺少的“ 1/2”字符。我认为这是由于来自不可见文本的干扰,因为在查看器中突出显示pdf时,可以看到不可见文本与可见文本重叠。 有没有办法删除不可见的文字?还是有其他解决方案? 码: 输出(粗体
-
链接到pdf 当我尝试从上面的pdf中提取文本时,我得到了在evince viewer中不可见的文本和可见的文本的混合。此外,一些所需的文本缺少查看器中没有缺少的字符,例如,“FALCONS”中的“S”和许多缺少的“½”字符。我认为这是由于不可见文本的干扰,因为在查看器中突出显示pdf时,可以看到不可见文本与可见文本重叠。 有没有办法去掉不可见的文字?还是有别的解决办法? 代码: 输出(粗体文本为