
neo4j服务器在创建节点和关系时变得非常慢

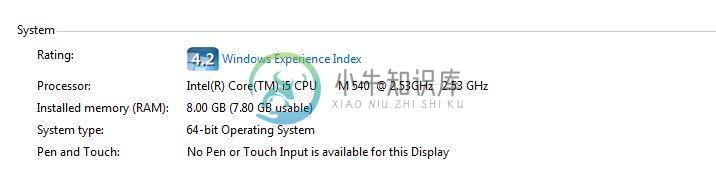
我还使用neo4j-enterprise-3.0.2,并使用BOLT连接将我的Pycharm python程序连接到数据库。我创建了许多节点和关系。我注意到,节点和关系的创建在一定时间后会大大减慢,在一定时间之后几乎不会进展。
我检查了以下
- 我对节点和属性使用了唯一的约束,以便可以使用模式索引轻松地在数据库中查找节点
- 我注意到,当所有这些事务发生时,我的RAM内存不断增加。我在dbms.memory.pagecache的neo4j配置文件中使用了不同的设置。大小(默认为2g、3g、10g)和它们都会导致我的RAM从大约4GB(没有运行python代码)增加到7GB及以上。此时节点的创建变得非常缓慢。停止程序时,RAM使用率再次下降
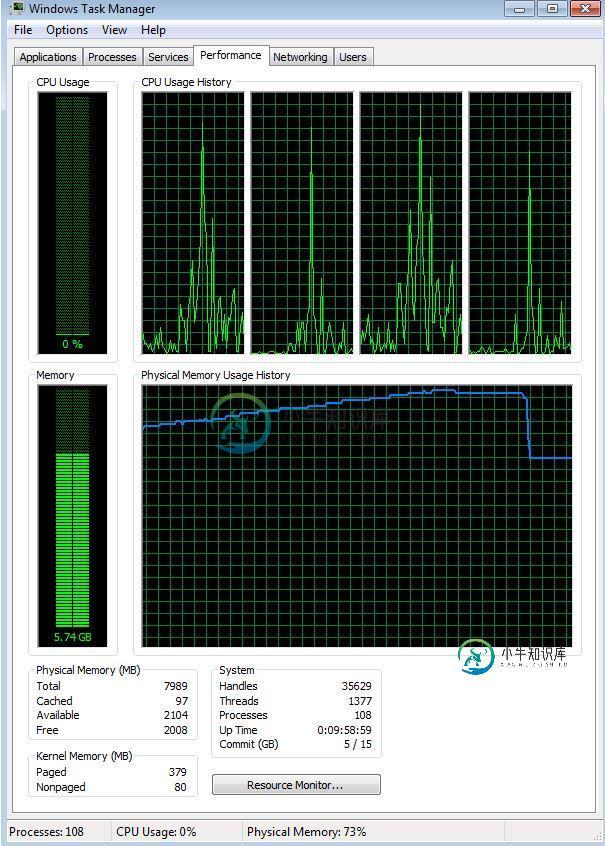
这是运行状况监视器向我显示的内容:
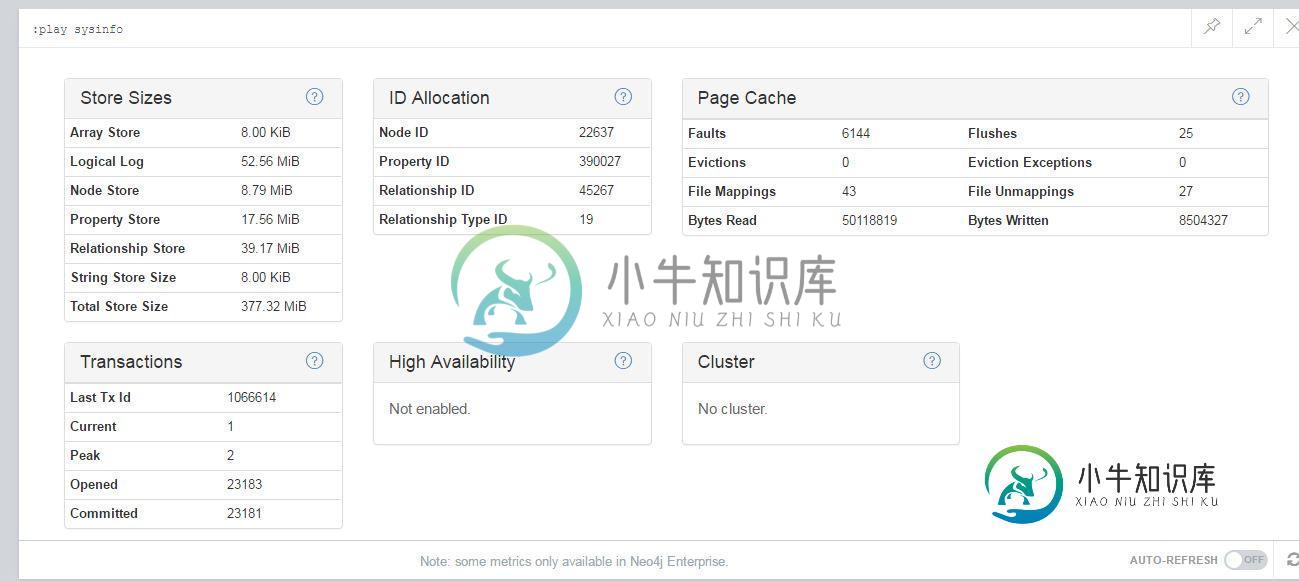
问:为什么节点和关系的创建速度变慢了这么多?这是因为图形的大小吗(但是数据集看起来很小)?它与数据库的螺栓连接和事务有关吗?是否与RAM使用量增加有关?如何防止这种情况发生?
我创建了这个简单的例子来说明这个问题:
from neo4j.v1 import GraphDatabase
#BOLT driver
driver = GraphDatabase.driver("bolt://localhost")
session = driver.session()
#start with empty database
stmtDel = "MATCH (n) OPTIONAL MATCH (n)-[r]-() DELETE n,r"
session.run(stmtDel)
#Add uniqueness constraint
stmt = 'CREATE CONSTRAINT ON (d:Day) ASSERT d.name IS UNIQUE'
session.run(stmt)
# Create many nodes - run either option 1 or option 2
# # Option 1: Creates a node one by one. This is slow in execution and keeps the RAM flat (no increase)
# for i in range(1,80001):
# stmt1 = 'CREATE (d:Day) SET d.name = {name}'
# dict = {"name": str(i)}
# print(i)
# session.run(stmt1,dict)
#Option 2: Increase the speed and submit multiple transactions at the same time - e.g.1000
# This is very fast but blows up the RAM memory in no time, even with a limit on the page cache of 2GB
tx = session.begin_transaction()
for i in range(1, 80001):
stmt1 = 'CREATE (d:Day) SET d.name = {name}'
dict = {"name": str(i)}
tx.run(stmt1, dict) # append a transaction to the block
print(i)
if divmod(i,1000)[1] == 0: #every one thousand transactions submit the block and creat an new transaction block
tx.commit()
tx.close
tx = session.begin_transaction() #it seems that recycling the session keeps on growing the RAM.
共有1个答案

我首先做的是:我实际上切换回py2neo包进行批量事务处理,并且在不使我的内存过载的情况下工作正常。我相信neo4j. v1包和内存管理一定有问题。
后来:我使用了更高版本的 neo4j 软件包,但不再有问题。它一定是早期版本中的错误。
-
我希望它创建每个节点(而不是在已经存在具有相同ID的节点时创建新节点),并创建每个关系(在CSV中指定具有多个关系的节点中有多个关系from/to节点)。 实际发生的情况:它似乎创建了所有唯一的节点。它还创建了节点之间的关系,但它只为每个节点设置一个关系,而不考虑与多个其他节点进行通信的一些节点。 我很困惑,因为我的理解是,如果在数据库中还没有出现关系,它将创建关系,所以我认为它将创建CSV中指定
-
我有一个csv格式的数据集。其中一个字段是类型,类似于枚举。基于此类型,我需要在使用csv LOAD加载数据时创建不同的类型、节点和关系。您可以在csv中调用具有定义子类型的属性的超级类型的行。 我真的不知道如何在Cypher中做到这一点。我唯一的选择是将一个csv文件拆分为每种类型的csv文件,并运行不同的密码吗?
-
基于这个类似的问题,我想要一种性能最好的方法来处理这个场景。 不幸的是,IF不存在,并且EXISTS不能用于匹配或查找唯一节点。 null
-
我的问题与此非常相似:如何通过在neo4j中导入的csv文件创建唯一的节点和关系?我有一个大约250万行的textfile,其中有两列,每一列都是节点ID: 每一行表示一个关系(即250万个关系):first_column nodeid->follows->second_column nodeid。这个文件中大约有80,000个唯一节点。 null 我的主要问题是我想知道如何使这个过程更快。这是在
-
请有人给我指个正确的方向。