
Kafka Streams如何用于事件源?

我了解了如何通过使用Apache Kafka作为事件代理来实现事件源。(链接到融合文章)
共有2个答案

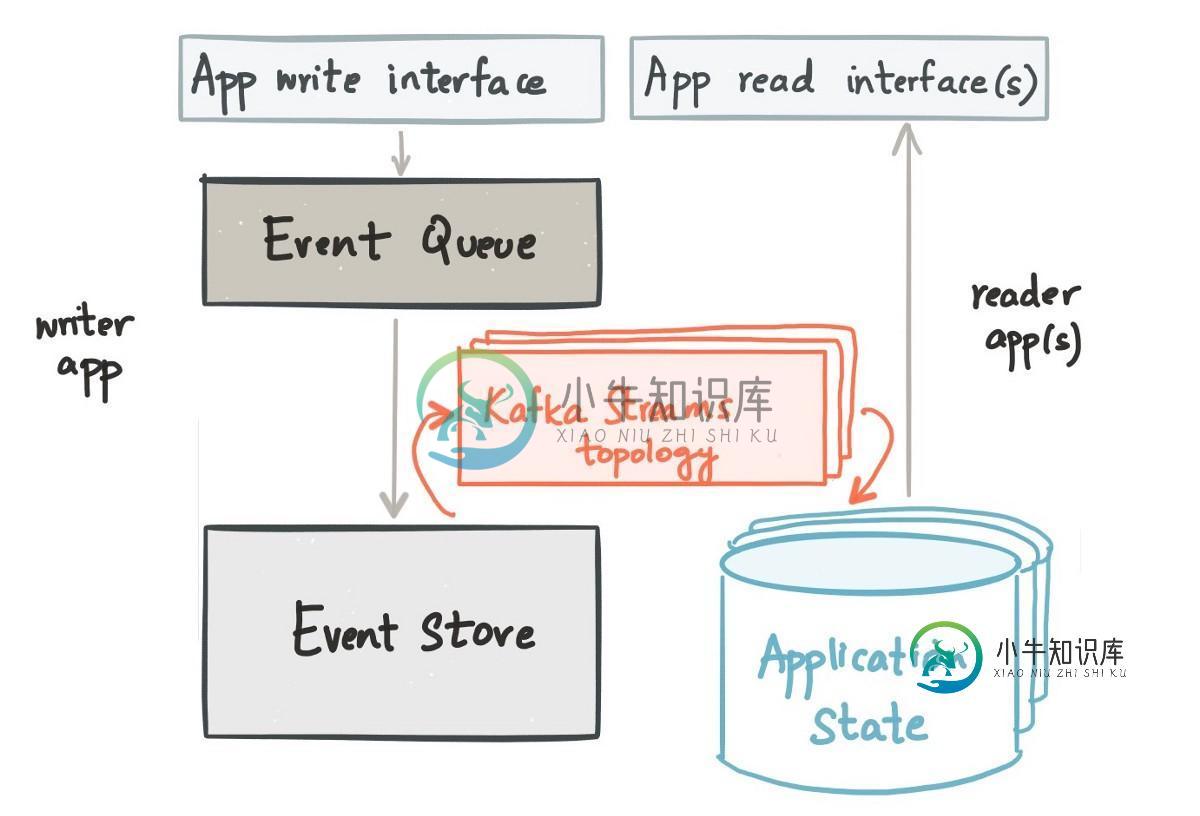
在该图中,Kafka Streams被用作从事件存储(该应用程序的写模型)到读模型(为执行查询而优化的数据视图)的投影。
应用程序的写入端很可能是一个服务,它接收命令并写入事件存储库(可以是专门为此类事件存储库设计的数据库,或者其他一些与这种模式一起使用的数据存储库,因为它满足事件存储库的契约)。事件存储的广义契约是,它允许为某个实体附加一个事件,并提供一种方法在某个时间点(通常是“时间的开始”,尽管拥有一些快照存储也并不罕见,在这种情况下,该时间点是从最新的快照派生的)之后检索给定实体的所有事件。
Kafka可用作事件存储,尤其是当相对于分区的数量而言,事件源实体很少时:否则,“检索给定实体的所有事件”操作意味着过滤掉其他实体的事件,这在某种程度上会变得非常低效。
如果不使用Kafka作为事件存储,而是使用Kafka Streams作为投影,那么您可能会有以下之一:
> < li>
(高级,例如使用类似Akka持久性的东西来管理事件存储;免责声明:我受雇于Lightbend,该公司维护Akka并提供有关Akka的商业支持和咨询),这是从发布事件的事件商店到Kafka Streams订阅的Kafka主题的投影
(低级,例如将常规DB视为事件存储的手动库)更改数据捕获(例如Debezium for MySQL/Postgres/等)将事件存储表的更新发布到Kafka Streams订阅的Kafka主题

Kafka Streams必须首先使用来自Kafka的事件,这些事件是由使用普通Kafka生产者库的其他进程“采购”的。
Kafka Streams应用程序只能扩展到其源主题中的分区数量,因为它们是基于Kafka消费者API构建的
-
一、事件埋点 您需要在研发工程师的协助下,在用户行为发生时将其记录下来,并发送给诸葛io——这个过程称作事件埋点。 如果您是产品或运营,建议您在和研发君沟通之前,尽量弄清分析目标并整理好事件埋点表,您也可以把这份入门指南推荐给研发君阅读——帮研发君在最短的时间内理解事情的全貌,会有助于事情的快速和顺利推进。 另外,在集成SDK之前,请确保您已在诸葛io中完成了账号注册并创建应用(大约需要2分钟,跟
-
我们正在从传统的单一应用程序迁移到微服务体系结构。我们使用CQRS和事件源模式以及消息代理(rabbitmq)作为通信机制。现在我们面临着一个挑战,即如何将旧数据库转换为新的体系结构,以及如何使用事件源进行这些转换?假设旧数据库没有事件,我们可以在不创建事件的情况下进行数据转换吗?在事件源模式中,旧数据库数据的起点是什么?
-
尽管Flink有一些内置的工具来处理延迟数据,比如允许延迟,但我想自己处理延迟数据。例如,我想监控延迟事件或将它们保存到数据库中。 我该怎么做?
-
我想使用Axon框架实现CQRS和ES 我有一个相当复杂的HTML表单,它代表招聘过程的六个步骤。 ES将有助于生成选定日期的历史统计信息并跟踪表单的变化。 null null 此解决方案的缺点是,由于违反约束,可能会生成一些事件,而不会生成其他事件,例如:将成功,但将由于分配未经授权的用户而失败。也许我应该在命令生成之前检查所有约束? 此解决方案的缺点是某些命令可能失败,例如:可能由于分配未经授
-
在React router中,我必须单击和onClick属性,如下所示 属性导航到关于路线 当我给超时内嵌函数调用点击,其导航到新页面,并在某个时候状态得到更新,导致显示以前的名称,直到状态更新为新名称。 是否有一种方法,只有在onClick函数中的代码执行之后,它才会导航到新路由。 您可以[在这里]获取整个代码(https://github.com/pushkalb123/basic-react