
调试不平衡Kafkamessage_in

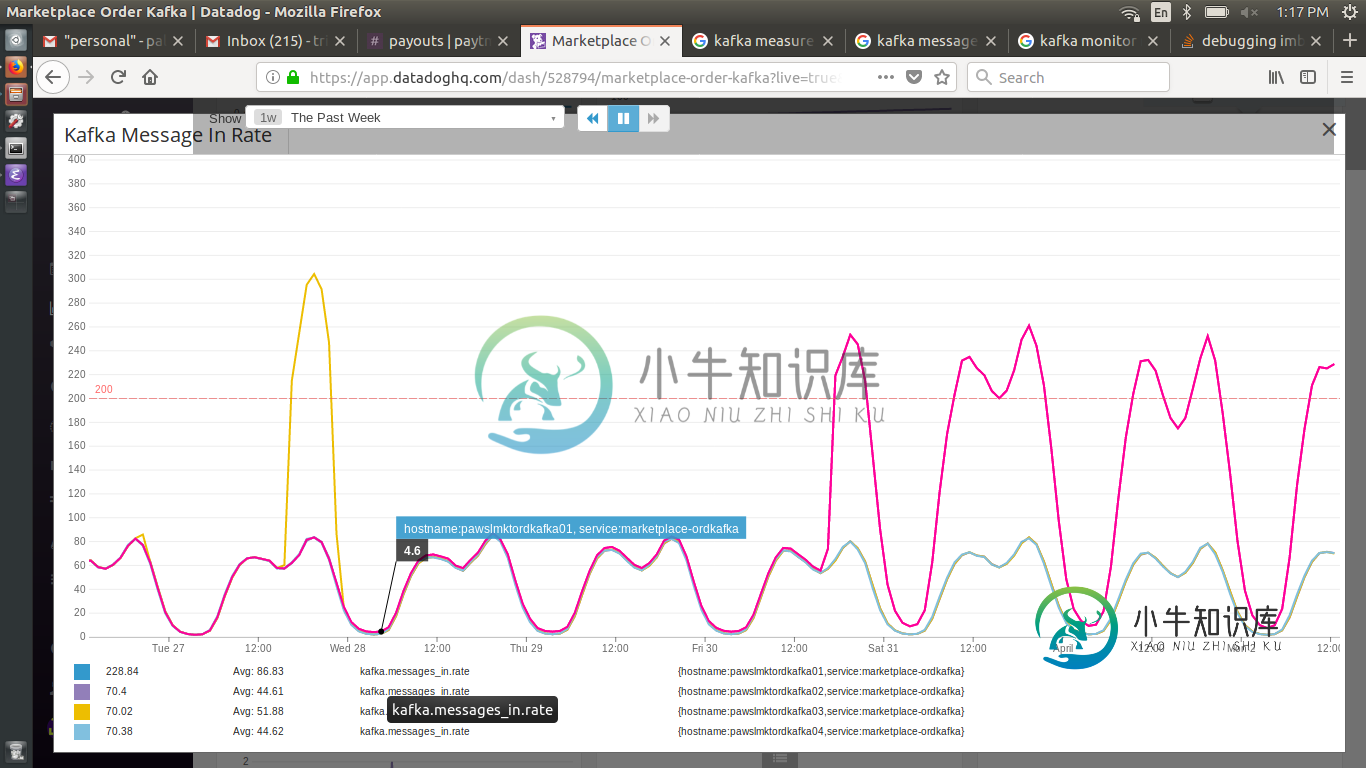
- 集群由4个节点中的每个节点上的16个引线进行平衡
- ISR在4个箱子中也保持平衡,每个箱子有32个ISR[复制系数为2]
- 所有4个盒子上的网络输入和输出几乎相等
请求任何帮助或可以查看的领域/指标来调试此异常。
对于将来正在搜索此信息的人https://mail-archives.apache.org/mod_mbox/kafka-users/201710.mbox/
共有1个答案

要调试的东西很少
- 启用代理日志跟踪
- 比较一个接收更多请求的日志和一个接收较少请求的日志,这将有足够的产生请求进行比较
- 在日志中搜索产品请求,它将为您提供分区是否按预期进行的见解,并提供有关从哪个主机接收更多请求的信息。
-
问题内容: 我有以下代码: 在这一行上: 我遇到了错误。 我究竟做错了什么? 问题答案: 括号在正则表达式中有特殊含义。您可以逃脱括号,但是 对于此问题,您实际上根本不需要正则表达式 :
-
相信维基百科文章:http://en.wikipedia.org/wiki/AVL_tree AVL树高度平衡,但一般不平衡重量,也不平衡μ;[4] 也就是说,同级节点的子节点数量可能相差很大。 但是,作为AVL树是: 自平衡二叉查找树[...]。在AVL树中,任何节点的两个子树的高度最多相差一个 我不明白AVL怎么会是重量不平衡的,因为——如果我很好地理解AVL树的定义——每个兄弟姐妹都会有大约
-
我面临的一个问题是KeyedStream在workers上是纯粹并行的,因为键的数量接近并行度 我的输入记录在0-N的范围内。当我使用keyBy时,有些工人处理零个键,有些则不止一个。这是因为在中对Key.HasCode使用murmurHash并选择通道。 我知道partitionCustom可以处理这种情况,但partitionCustom只返回数据流,而不是KeyStream。 那么我能做什么
-
应用色彩平衡调整 对于普通的色彩校正,“色彩平衡”命令更改图像的总体颜色混合。 确保在“通道”面板中选择了复合通道。只有当您查看复合通道时,此命令才可用。 执行下列操作之一: 单击“调整”面板中的“色彩平衡”图标。 选取“图层”>“新建调整图层”>“色彩平衡”。在“新建图层”对话框中单击“确定”。 注意:也可以选取“图像”>“调整”>“色彩平衡”。但是,请记住,该方法对图像图层进行直接调整并扔掉图
-
本文向大家介绍数据不平衡怎么办?相关面试题,主要包含被问及数据不平衡怎么办?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 使用正确的评估标准,当数据不平衡时可以采用精度,调用度,F1得分,MCC,AUC等评估指标。 重新采样数据集,如欠采样和过采样。欠采样通过减少冗余类的大小来平衡数据集。当数据量不足时采用过采样,尝试通过增加稀有样本的数量来平衡数据集,通过使用重复,自举,SMOTE等方
-
Kafka再平衡算法是否适用于不同主题? 假设我有5个主题,每个主题都有10个分区,同一消费者组中有20个消费者应用程序实例,每个实例都订阅了这5个主题。 Kafka会尝试在20个实例中平衡50个分区吗? 还是它只在一个主题内保持平衡,因此10个第一个实例可能(或可能)接收所有50个分区,而其他10个实例可能保持空闲? 我知道,在过去,Kafka并没有在不同的主题之间取得平衡,但现在的版本呢?