
活动任务在Spark UI中为负数

在使用Spark-1.6.2和pyspark时,我看到了以下内容:
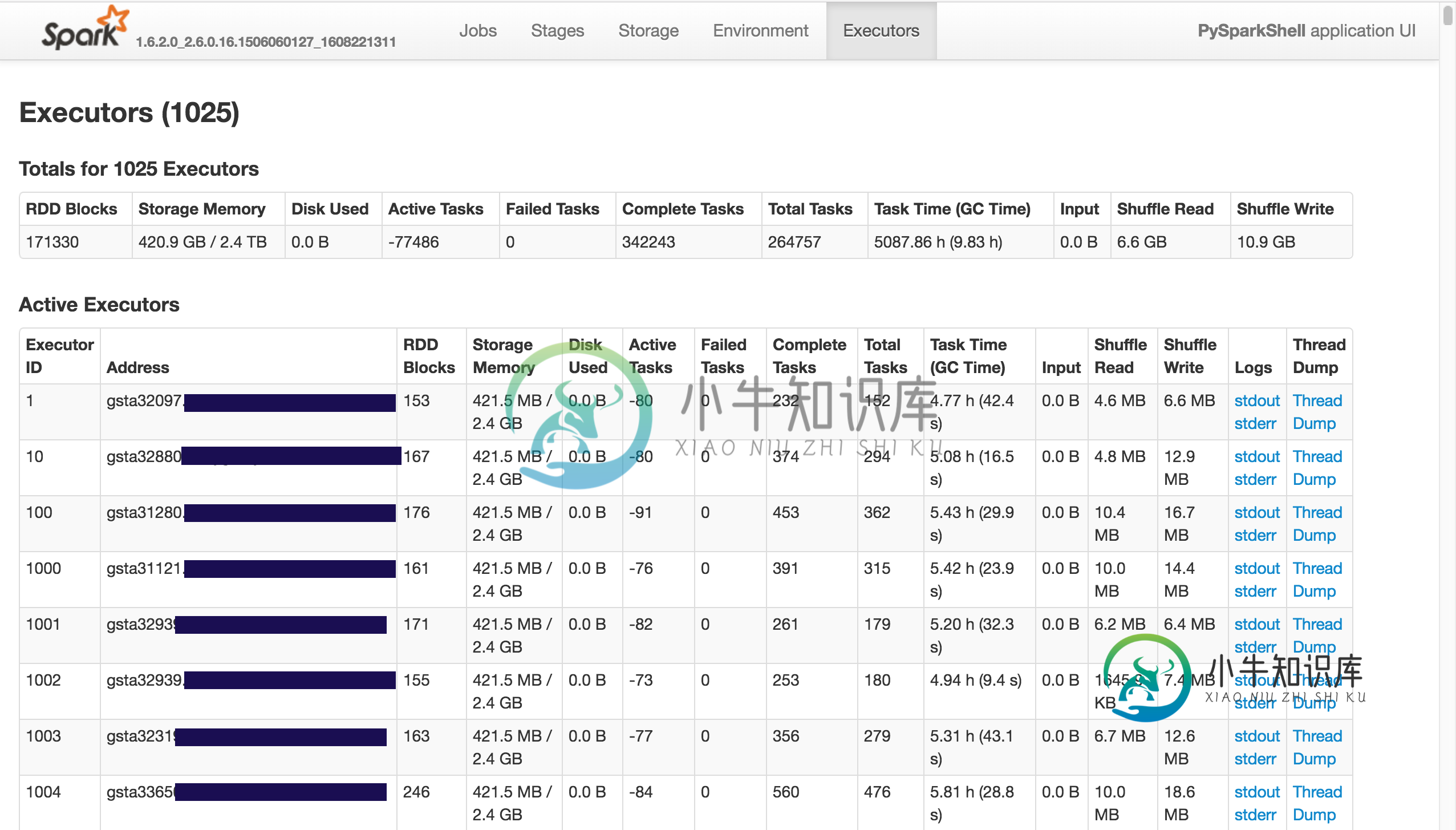
其中活动任务为负数(任务总数与已完成任务之差)。
这个错误的来源是什么?
我有很多执行者的节点。然而,似乎有一个任务似乎一直在闲置(我没有看到任何进展),而另一个相同的任务正常完成。
16/08/15 20:03:38 ERROR LiveListenerBus: Dropping SparkListenerEvent because no remaining room in event queue. This likely means one of the SparkListeners is too slow and cannot keep up with the rate at which tasks are being started by the scheduler.
16/08/15 20:07:18 WARN TaskSetManager: Lost task 20652.0 in stage 4.0 (TID 116652, myfoo.com): FetchFailed(BlockManagerId(61, mybar.com, 7337), shuffleId=0, mapId=328, reduceId=20652, message=
org.apache.spark.shuffle.FetchFailedException: java.util.concurrent.TimeoutException: Timeout waiting for task.
共有1个答案

这是一个火花问题。它发生在执行程序失败后重新启动时。同样的JIRA问题已经创建。您可以从https://issues.apache.org/jira/browse/spark-10141链接获得更多关于相同内容的详细信息。
-
据我所知,Camunda提供了两种将Java代码与服务任务集成的方法: 1.)声明一个实现JavaDelegate接口的Spring-Bean(该方法将一个DelegateExecution作为参数)。这个方法允许我存储任意多个结果变量,但我看不到定义映射process-variable->input-variable的选项。 2.)声明一个通用的Spring bean可由camunda访问,并定
-
问题内容: 我正在使用ThreadPoolExecutor在Java应用程序中执行任务。我有一个要求,我想在任何时间获取执行者队列中队列中活动任务的数量。我查看了ThreadPoolExecutor 的javadoc,发现了两个相关方法:和。 根据文档,我可以分别通过上述两种方法获得计划任务和完成任务的数量。但是我找不到能够在任何时间获取队列中活动任务数量的解决方案。我可以做类似的事情: 但是失败
-
我有一个端口上带有UDP套接字的活动。如果我按下Home按钮,活动进入后台,将调用OnPause()和OnStop()方法。现在,当我收到一些UDP数据包时,我想恢复我的活动。阅读其他帖子,我明白我必须: 将活动声明为(或) 然后,当我想恢复活动时: 这个解决方案对我不起作用。调用不会在前台显示我的活动,也不会调用。 以下标志可以完成任务,但我不想清除任务并重新启动新任务。
-
我计划了一个活动任务,但通过查看历史记录从未执行(开始),然后工作流被超时。我可以确认节奏工作者正在运行,因为其他工作流同时工作正常。 为什么活动在历史上没有开始/执行?我应该如何调查这样的问题? 我的活动超时与工作流超时相同。 这个问题来自于这个Github问题。
-
考虑以下Java伪代码: 上面的Java代码将使我的100个线程都处于繁忙状态,假设方法'process_task_and_split_to_sub_tasks()'可以将任何大任务拆分为许多较小的任务。 有没有一种方法可以在Spark中实现同样的功能,可以与其他工具相结合? null 在这种情况下,动态负载平衡是这样的:已经收到以'a'开头的行的映射器可能想进一步拆分它的行--到以'ab'、'a
-
我可以安全地停止我的主活动的onDestroy方法中的服务吗?我知道onDestroy不能保证被调用,但我也想让我的服务运行,直到应用程序被销毁。 我在想,也许在所有活动被破坏的情况下,服务也会被破坏?