
Web刮取无法通过Selenium/BS4获取完整的源代码数据

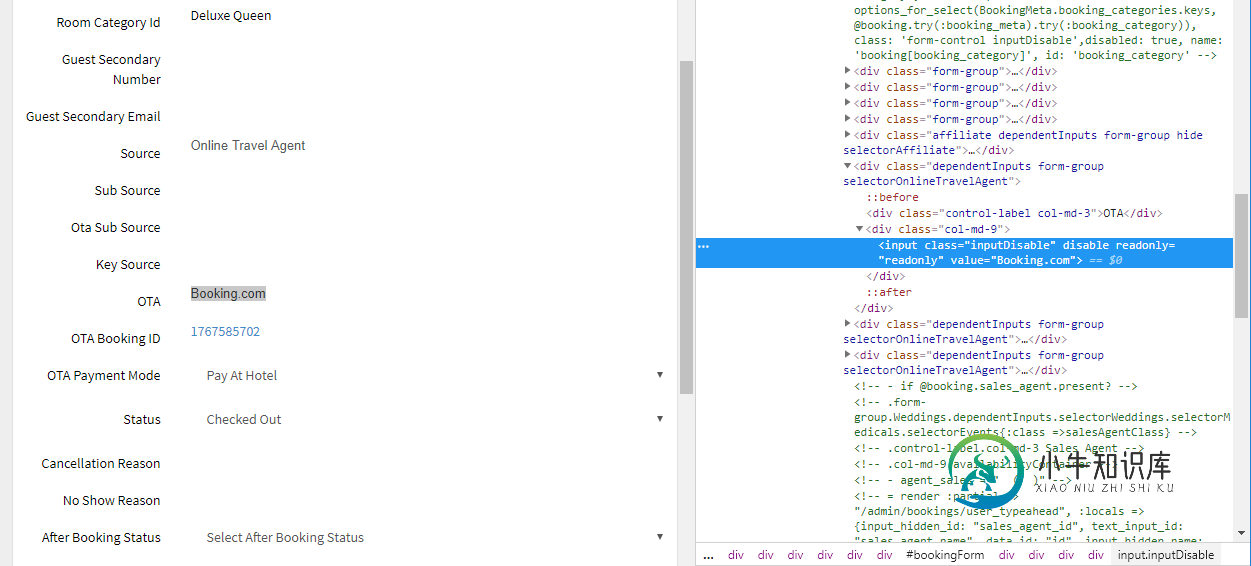
我如何从我检查的源(如图像所示)中刮取输入标记的值属性中的数据?
我试过使用BeautifulSoup和Selenium,但它们对我都不起作用。
部分代码如下:
html=driver.page_source
output=driver.find_element_by_css_selector('#bookingForm > div:nth-child(1) > div.bookingType > div:nth-child(15) > div.col-md-9 > input').get_attribute("value")
print(output)
这将返回nosuchelementexception错误。
事实上,当我尝试print(html)时,很多源代码数据似乎丢失了。我怀疑这可能是与JS相关的问题,但是Selenium--它大部分时间都在呈现JS--在这个站点上对我不起作用。知道为什么吗?
我也试过这些:
html=driver.page_source
soup=bs4.BeautifulSoup(html,'lxml')
test = soup.find("input",{"class":"inputDisable"})
print(test)
print(soup)
print(test)返回none,而print(soup)返回源,其中大部分输入标记完全丢失。
共有3个答案

from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
import urllib.request
import time
from bs4 import BeautifulSoup
from datetime import date
URL="https://yourUrl.com"
# Chrome session
driver = webdriver.Chrome("PathOfTheBrowserDriver")
driver.get(URL)
driver.implicitly_wait(100)
time.sleep(5)
soup=bs4.BeautifulSoup(driver.page_source,"html.parser")
在制作汤之前,尝试与您的代码创建一个中断,以便让请求完成它们的工作(一些迟来的请求可能包含您正在查找的内容)

尝试使用find或find_all函数。(https://www.crummy.com/software/Beautifulsoup/bs4/doc/)
from requests import get
from bs4 import BeautifulSoup
url = 'your url'
response = get(url)
html_soup = BeautifulSoup(response.text, 'html.parser')
bs = BeautifulSoup(response.text,"lxml")
test = bs.find("input",{"class":"inputDisable"})
print(test)

通过检查页面检查此网站上是否存在此元素。如果存在,那么很多时候selenium太快,页面有时无法完全加载。尝试selenium的等待功能。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
browser = webdriver.Firefox()
browser.get("url")
delay = 3 # seconds
try:
myElem = WebDriverWait(browser, delay).until(EC.presence_of_element_located((By.ID, 'IdOfMyElement')))
print "Page is ready!"
except TimeoutException:
print "Loading took too much time!"
-
问题内容: JavaScript代码将从www.example.com通过google chrome中的网址栏启动,因此我无法使用jquery。我的目标是当我在www.example.com中启动代码时,将www.example.com/page.html的完整html源代码传递给javascript中的变量。这可能吗?如果可以,怎么办?我知道要获取当前页面源,但我不确定如何做到这一点。我认为可以
-
我正试图从whoscored.com(下面的变量根链接)中删除到EPL所有球员的链接,这里是代码: 如果你进入这个页面,你会看到一个玩家列表和一个下一个按钮来显示下一个10个玩家(其中有284个在29页)我想要的输出:保存链接到每个10个玩家的配置文件,然后移动到下一个页面与下一个10个玩家直到完成
-
问题内容: 我想实现一个Java方法,该方法以URL作为输入并将整个网页(包括CSS,图像,JS(所有相关资源))存储在磁盘上。我已经使用Jsoup html解析器来获取html页面。现在,我想实现的唯一选择是使用jsoup获取页面,现在解析html内容并将相对路径转换为绝对路径,然后再次请求获取javascript,图像等并将其保存在磁盘上。我还阅读了有关HTML清洁器,htmlunit解析器的
-
我想实现一个java方法,它将URL作为输入,并将包括css、图像、js(所有相关资源)在内的整个网页存储在我的磁盘上。我已经使用Jsoup html解析器来获取html页面。现在,我想实现的唯一选项是使用jsoup获取页面,现在解析html内容,将相对路径转换为绝对路径,然后发出另一个获取javascript、图像等的请求。并将它们保存在磁盘上。我也读过html cleaner和htmlunit
-
问题内容: 我在一个网页上运行查询,然后得到结果URL。如果我右键单击查看html源代码,则可以看到JS生成的html代码。如果我仅使用urllib,则python无法获取JS代码。所以我看到了一些使用selenium的解决方案。这是我的代码: 这是我在右键单击窗口中需要的源代码,(我需要信息部分) ===========所以我的问题是===============如何获取JS生成的信息? 问题答
-
问题内容: 我在一个网页上运行查询,然后得到结果URL。如果右键单击查看html源代码,则可以看到JS生成的html代码。如果我仅使用urllib,则python无法获取JS代码。所以我看到了一些使用硒的解决方案。这是我的代码: 这是我在右键单击窗口中需要的源代码,(我需要信息部分) 问题答案: 您将需要通过使用硒功能来获取文档 这将使所有内容都进入标签内