
Kafka在一段时间后停止,失去经纪人

我有4个Kafka和debezium一起运行。经过几天的良好运行后,三台kafka机器脱离网络一段时间,在< code > connect distributed . out 日志文件中,我收到了许多包含以下错误的消息:
[2020-05-04 13:27:02,526] WARN [Consumer clientId=connector-consumer-sink-warehouse-6,
groupId=connect-sink-warehouse] 133 partitions have leader brokers without a matching listener,
including [SCT010-2, SC2010-2, SC1010-0, SC1010-1, SF4010-0, SUB010-0, SUB010-1, SWP010-0,
SWP010-1, ACO010-2] (org.apache.kafka.clients.NetworkClient:1044)
我有4台Kafka机器,经纪人从0到3
192.168.240.70 - Broker 0
192.168.240.71 - Broker 1
192.168.240.72 - Broker 2
192.168.240.73 - Broker 3
动物园管理员:
<代码>192.168.240.70
关注我的服务器属性 - 除了侦听器之外,有相同的 advertised.listeners 指向安装 Kafka 的计算机的相同 IP,并且 broker.id 必须是唯一的(从 0 到 3):
broker.id=0
listeners=CONTROLLER://192.168.240.70:9091,INTERNAL://192.168.240.70:9092
advertised.listeners=CONTROLLER://192.168.240.70:9091,INTERNAL://192.168.240.70:9092
listener.security.protocol.map=CONTROLLER:PLAINTEXT,INTERNAL:PLAINTEXT
control.plane.listener.name=CONTROLLER
inter.broker.listener.name=INTERNAL
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/home/william/kafka/data/kafka/
num.partitions=3
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=1
log.retention.hours=150
log.retention.bytes=200000000000
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.240.70:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=3
kafka 主题(配置/偏移和状态)显示复制中的问题。有一些与监听器配置有关吗?
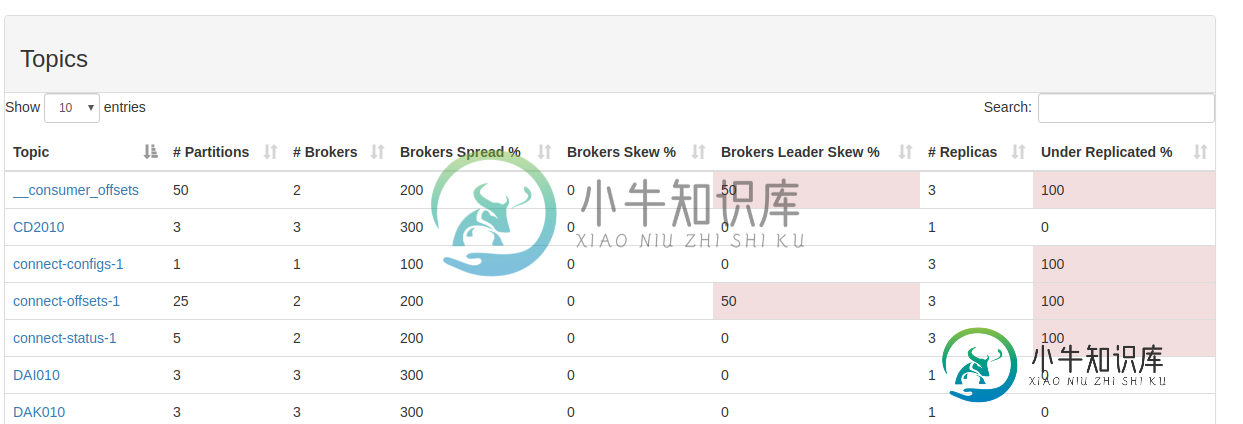
关于连接器运行状况:
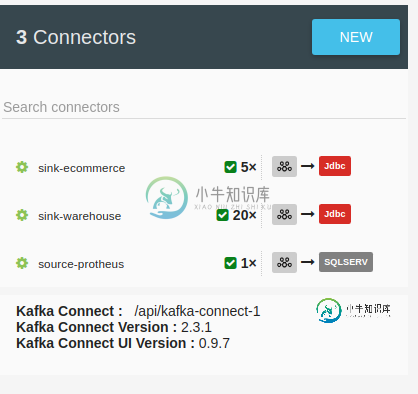
并且,在kafka连接上。只有一个经纪人出现:
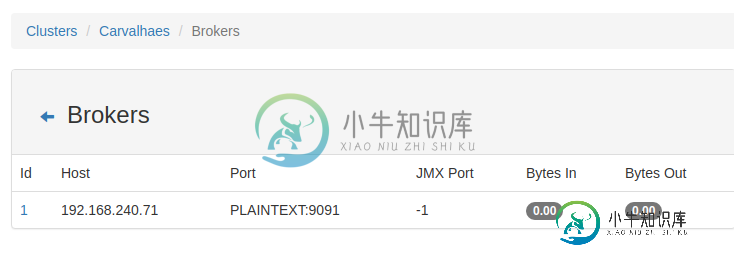
如何修复此错误?似乎与领导人选举有关,或者在长时间没有经纪人的情况下找到领导人。
共有1个答案

经过研究,我发现了问题所在。因此,为了在这里提供帮助,请遵循有关问题的概念:
当我们创建分布式Kafka系统时,我们将话题分布在经纪人周围,并创建领导者选举人。在我的情况下,我有4个经纪人,Zookeeper在飞行中选择他们将成为某些主题的领导者。
由于四个Kafka服务器中有三个关闭了一个多小时,动物园管理员试图联系到领导者,但联系不到。由于我的配置指出需要向三个经纪人复制相同的主题,动物园管理员无法保持主题健康。
我们有重新平衡配置:group.initial.rebalance.delay.ms=3,它每3秒尝试重新平衡一次。在一个 Kafka 代理关闭之前,我们尝试重新连接的次数有限。尝试发生了,动物园管理员无法联系到丢失的经纪人。
换言之,经纪人并没有倒闭,他们只是因为网络问题无法联系到Zookeeper,因此,一段时间后,Zookeepher的尝试被停止,一段时期后,Kafka经纪人再次可以联系到,但重新平衡的尝试被终止。
只是,简单地重启我的经纪人告诉zookeeper重新连接解决了我的问题,因为重启时,Kafka经纪人告诉zookeeper:-我在这里,等待你的指示。动物园管理员意识到失去了领袖,把一切都重新连接到正确的地方。
所以,努力提供帮助。
-
我们的集群中有带有 Ambari GUI 的 Hadoop 集群版本 2.6.4,我们有 3 台 Kafka 机器,它们是独立的机器,而 3 台 Zookeper 服务器安装在其他机器上 - master01/02/03 其中一台Kafka机器出现了一个奇怪的问题,而其他Kafka设备没有这个问题 问题是,当我们在几分钟后启动Kafka经纪人时,它会崩溃 以下是日志: 出自Kafka.呃 从日志的
-
触发spring boot REST服务后,该服务可以正常运行数小时,所有请求都可以正常工作,没有任何问题。发生的是,一段时间后,它随机地停止了。在查看日志时,我没有发现任何错误,除了应用程序已被销毁的信息。 一段时间后的日志 Maven依赖项 对于为什么spring boot REST API可能会停止有什么想法吗?我的maven依赖关系是根据演示的--而且它正在成功运行--这就是为什么服务在随
-
问题内容: 在我的组织中,我们有许多Redis工作人员来完成我们的关键任务。通常,一天一次或两次,我们的工人会停止处理队列。 该代码基本上如下所示: 如果看到的话,就代码而言,发生的事情并不多,但是每隔一段时间,队列就会开始建立,并且工作程序不会从队列中弹出任何项目。为设置超时根本没有用,因为我们假设问题出在Redis客户端连接上。 目前,我们已经建立了一些侦听器,这些侦听器会在队列建立时提醒我们
-
我有6个集装箱在码头群中运行。Kafka Zookeeper、MongoDB、A、B、C和接口。接口是来自公共的主要访问点-只有这个容器发布端口-5683。接口容器在启动期间连接到A、B和C。我使用docker组合文件docker堆栈部署,每个服务都有一个名称,用作接口的主机。一切都开始顺利,运转良好。过了一段时间(20分钟、1小时……),我无法向接口提出请求。接口接收到我的请求,但应用程序与服务
-
我注意到我的Kafka Streams应用程序在一段时间没有读取来自Kafka主题的新消息时停止工作。这是我第三次看到这种情况发生。 自5天以来,没有向主题发送任何消息。我的Kafka Streams应用程序也托管了一个spark java Web服务器,它仍然具有响应能力。然而,Kafka Streams不再阅读我向Kafka主题发出的消息。当我重新启动应用程序时,所有消息都将从代理获取。 如何
-
更新06/04这里是消费者出厂设置。它是Spring-Kafka-1.3.1。Kafka经纪人合流版 注意:容器工厂已将自动启动设置为false。这是在加载大文件时手动启动/停止使用者。 运行大约1小时后(时间不同),使用者停止使用来自其主题的消息,即使该主题有许多可用消息。Consumer方法中有一个log语句,用于停止在日志中打印。 我们如何设计Spring-Kafka消费者,使其在停止消费的