
如何在matplotlib图中添加轴偏移量?

我在同一张图上绘制了多个seaborn点图。x轴是序数,而不是数字。每个点图的序数值都相同。我想将每个图稍微移到一边,pointplot(dodge =
…)参数的方式是在单个图内的多条线内进行,但是在这种情况下,是要在彼此之上绘制多个不同图。我怎样才能做到这一点?
理想情况下,我想要一种适用于任何matplotlib图的技术,而不仅仅是专门针对海洋的技术。由于数据不是数字,因此很难为数据添加偏移量。
显示地块重叠并使其难以阅读的示例(每个地块内的闪避都可以)
import pandas as pd
import seaborn as sns
df1 = pd.DataFrame({'x':list('ffffssss'), 'y':[1,2,3,4,5,6,7,8], 'h':list('abababab')})
df2 = df1.copy()
df2['y'] = df2['y']+0.5
sns.pointplot(data=df1, x='x', y='y', hue='h', ci='sd', errwidth=2, capsize=0.05, dodge=0.1, markers='<')
sns.pointplot(data=df2, x='x', y='y', hue='h', ci='sd', errwidth=2, capsize=0.05, dodge=0.1, markers='>')
我可以使用seaborn以外的其他工具,但是自动置信度/错误栏非常方便,因此我宁愿在这里坚持使用seaborn。
问题答案:
首先回答最常见的情况。可以通过将图中的艺术家移动一定量来实现躲避。将点用作该偏移的单位可能会很有用。例如,您可能需要将情节上的标记移动5点。
可以通过在艺术家的数据转换中添加翻译来完成此转换。我在这里提出一个建议ScaledTranslation。
现在,为了保持最通用,可以编写一个函数,该函数将绘图方法,轴和数据作为输入,此外还应应用一些闪避功能,例如
draw_dodge(ax.errorbar, X, y, yerr =y/4., ax=ax, dodge=d, marker="d" )
完整的功能代码:
import matplotlib.pyplot as plt
from matplotlib import transforms
import numpy as np
import pandas as pd
def draw_dodge(*args, **kwargs):
func = args[0]
dodge = kwargs.pop("dodge", 0)
ax = kwargs.pop("ax", plt.gca())
trans = ax.transData + transforms.ScaledTranslation(dodge/72., 0,
ax.figure.dpi_scale_trans)
artist = func(*args[1:], **kwargs)
def iterate(artist):
if hasattr(artist, '__iter__'):
for obj in artist:
iterate(obj)
else:
artist.set_transform(trans)
iterate(artist)
return artist
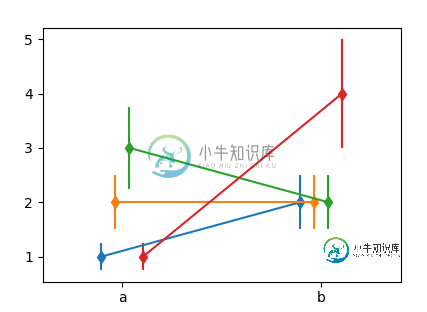
X = ["a", "b"]
Y = np.array([[1,2],[2,2],[3,2],[1,4]])
Dodge = np.arange(len(Y),dtype=float)*10
Dodge -= Dodge.mean()
fig, ax = plt.subplots()
for y,d in zip(Y,Dodge):
draw_dodge(ax.errorbar, X, y, yerr =y/4., ax=ax, dodge=d, marker="d" )
ax.margins(x=0.4)
plt.show()
您可以使用这项功能ax.plot,ax.scatter但是不与任何的seaborn功能等,因为他们没有任何有用的艺术家复工用。
现在对于所讨论的情况,剩下的问题是以有用的格式获取数据。一种选择如下。
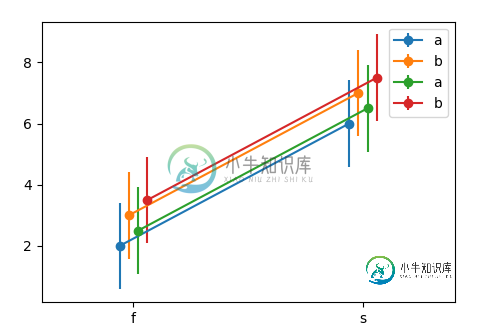
df1 = pd.DataFrame({'x':list('ffffssss'),
'y':[1,2,3,4,5,6,7,8],
'h':list('abababab')})
df2 = df1.copy()
df2['y'] = df2['y']+0.5
N = len(np.unique(df1["x"].values))*len([df1,df2])
Dodge = np.linspace(-N,N,N)/N*10
fig, ax = plt.subplots()
k = 0
for df in [df1,df2]:
for (n, grp) in df.groupby("h"):
x = grp.groupby("x").mean()
std = grp.groupby("x").std()
draw_dodge(ax.errorbar, x.index, x.values,
yerr =std.values.flatten(), ax=ax,
dodge=Dodge[k], marker="o", label=n)
k+=1
ax.legend()
ax.margins(x=0.4)
plt.show()
-
问题内容: 只是在我编辑我的作品时注意到了这种细微差别。 以前,matplotlib如下所示: 但经过最近的升级我相信,有抵消,这会回来 这样地 从我现在看到的情况来看,这有点不必要。我想知道 1在数据可视化中,这个偏移量是否是一个好的实践?如果是这样的话,我就不做了。 2如何抵消这种抵消? 我可以手动恢复限制,但是 如果我再有20块地的话就不会扩大规模了。我搜索了一下,没有找到 这方面的信息太多
-
问题内容: 我正在使用matplotlib.pyplot.scatter绘制一堆UTM坐标。我还有一张背景空气照片,我知道它与数字的范围完全吻合。当我绘制数据并设置轴时,可以正确显示散点图。如果我使用imshow绘制空中照片,它将使用像素数作为轴位置。我需要将图像(numpy数组)移动到正确的UTM位置。有任何想法吗?我对matplotlib和numpy相当陌生。 例如:我知道图像的左上角(ims
-
问题内容: 我有一个非常简单的问题。我需要在绘图上有第二个x轴,并且我希望该轴具有一定数量的tic,它们对应于第一个x轴的特定位置。 让我们尝试一个例子。在这里,我将暗物质质量绘制为膨胀系数(定义为1 /(1 + z))的函数,该膨胀系数的范围为0到1。 我想在图的顶部放置另一个x轴,以显示对应于某些膨胀系数值的z轴。那可能吗?如果是的话,我怎么能拥有xtics斧头 问题答案: 我正在从@Dhar
-
问题内容: 我在这里阅读了其他问题 作为删除当前图上轴偏移的一种方法,但是默认情况下有什么方法吗?我在matplotlibrc文件中看不到任何有帮助的东西。 问题答案: 不,没有办法。它在353行的源文件中定义: 作为默认参数值。因此默认值为。 当然,您可以修改源。
-
问题内容: 我已经成功地增加了ticklabels的字体,但是现在它们离轴太近了。我想在刻度标签和轴之间添加一点呼吸空间。 问题答案: 看起来matplotlib将这些设置视为rcParams: 在 创建任何图形 之前先进行 设置, 然后就 可以了。 我看过源代码,似乎没有其他方法可以通过编程设置它们。(tick.set_pad()看起来像是试图做正确的事,但是似乎在构建Ticks时设置了填充,此
-
问题内容: 我在用 在或中,如果我们向其添加标签,则可以轻松放置图例。但是如果是或 我知道有一个可以显示颜色范围的颜色,但是并不满意。我想要一个带有名称(标签)的 我能想到的是,向矩阵中的每个元素添加标签,然后,尝试legend(),以查看其是否有效,但是如何向元素添加标签(如值)? 就我而言,原始数据如下: 例如,1代表“草”,2代表“沙”,3代表“山” …依此类推。imshow()非常适合我的