
word2vec实施过程

参考回答:
词向量其实是将词映射到一个语义空间,得到的向量。而word2vec是借用神经网络的方式实现的,考虑文本的上下文关系,有两种模型CBOW和Skip-gram,这两种模型在训练的过程中类似。Skip-gram模型是用一个词语作为输入,来预测它周围的上下文,CBOW模型是拿一个词语的上下文作为输入,来预测这个词语本身。
词向量训练的预处理步骤:
1.对输入的文本生成一个词汇表,每个词统计词频,按照词频从高到低排序,取最频繁的V个词,构成一个词汇表。每个词存在一个one-hot向量,向量的维度是V,如果该词在词汇表中出现过,则向量中词汇表中对应的位置为1,其他位置全为0。如果词汇表中不出现,则向量为全0
2.将输入文本的每个词都生成一个one-hot向量,此处注意保留每个词的原始位置,因为是上下文相关的
3.确定词向量的维数N
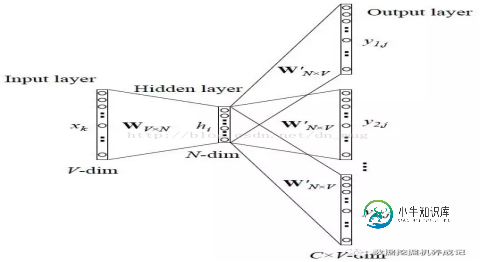
Skip-gram处理步骤:
1.确定窗口大小window,对每个词生成2*window个训练样本,(i, i-window),(i, i-window+1),...,(i, i+window-1),(i, i+window)
2.确定batch_size,注意batch_size的大小必须是2*window的整数倍,这确保每个batch包含了一个词汇对应的所有样本
3.训练算法有两种:层次Softmax和Negative Sampling
4.神经网络迭代训练一定次数,得到输入层到隐藏层的参数矩阵,矩阵中每一行的转置即是对应词的词向量
CBOW的处理步骤:
1.确定窗口大小window,对每个词生成2*window个训练样本,(i-window, i),(i-window+1, i),...,(i+window-1, i),(i+window, i)
2.确定batch_size,注意batch_size的大小必须是2*window的整数倍,这确保每个batch包含了一个词汇对应的所有样本
3.训练算法有两种:层次Softmax和Negative Sampling
4.神经网络迭代训练一定次数,得到输入层到隐藏层的参数矩阵,矩阵中每一行的转置即是对应词的词向量
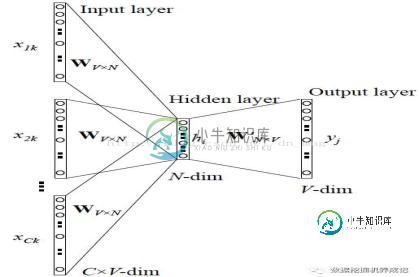
参数矩阵解释:
对输入层到隐藏层的参数包含W和b,我们需要的是W,这里的W是一个矩阵,shape=(N,V)。其中V是上文所述的词表的大小,N是需要生成的词向量的维数。N同样也是隐藏层(第一层)中的隐藏节点个数。
每次一个batch_size输入其实一个矩阵(batch_size, V),记为X,隐藏层输出为Y,公式为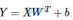 。所有的输入共享一个W,每次迭代的时候都在修改W,由于one-hot的性质,每次修改W只修改1对应的那一行。而这一行也就是词向量(转置后)
。所有的输入共享一个W,每次迭代的时候都在修改W,由于one-hot的性质,每次修改W只修改1对应的那一行。而这一行也就是词向量(转置后)
神经网络像是一个黑盒子,这其中的概念很难理解,这里给出我对词向量训练的个人理解:对于每个词s,训练数据对应的标记是另一个词t,训练其实是想找到一种映射关系,让s映射到t。但很显然我们不是希望找到一个线性函数,使得给定s一定能得到t,我们希望的是能够通过s得到一类词T,包含t。对于T中的每个t,由于在s上下文中出现的频次不同,自然能得到一个概率,频次越高说明s与t相关性越高。
对于词向量,或者说参数矩阵W,可以认为是一个将词映射到语义空间的桥梁,s与t相关性越高,则认为其在语义空间中越近,那么对应的桥梁也越靠近。如果用向量来理解的话就是向量之前的夹角越小,我们使用向量来表示这个词的信息,重要的是得到了语义信息。在实际应用中,生成一段文本,我们可以判断词与词的向量之间相似度,如果过低则就需要怀疑是否正确了。
-
本节是对前两节内容的实践。我们以“词嵌入(word2vec)”一节中的跳字模型和“近似训练”一节中的负采样为例,介绍在语料库上训练词嵌入模型的实现。我们还会介绍一些实现中的技巧,如二次采样(subsampling)。 首先导入实验所需的包或模块。 import collections import d2lzh as d2l import math from mxnet import auto
-
“进行面向对象的设计时,一项基本的考虑是:如何将发生变化的东西与保持不变的东西分隔开。” 这一点对于库来说是特别重要的。那个库的用户(客户程序员)必须能依赖自己使用的那一部分,并知道一旦新版本的库出台,自己不需要改写代码。而与此相反,库的创建者必须能自由地进行修改与改进,同时保证客户程序员代码不会受到那些变动的影响。 为达到这个目的,需遵守一定的约定或规则。例如,库程序员在修改库内的一个类时,必须
-
Word2Vec简介 Word2vec的应用不止于解析自然语句。它还可以用于基因组、代码、点赞、播放列表、社交媒体图像等其他语言或符号序列,同样能够有效识别其中存在的模式。 为什么呢?因为这些数据都是与词语相似的离散状态,而我们的目的只是求取这些状态之间的转移概率,即它们共同出现的可能性。所以gene2vec、like2vec和follower2vec都是可行的。 Word2vec的目的和功用是在
-
Word2Vec Word2Vec算法是NLP领域著名的算法之一,可以从文本数据中学习到单词的向量表示,并作为其他NLP算法的输入。 1. 算法介绍 我们使用Spark On Angel实现了基于负采样优化的SkipGram模型,能够处理高达10亿 * 1000维的超大模型。U、V矩阵存储在Angel的PS上,spark executor根据batch数据拉取对应节点以及负采样节点做梯度计算以及更
-
在信号处理领域,图像和音频信号的输入往往是表示成高维度、密集的向量形式,在图像和音频的应用系统中,如何对输入信息进行编码(Encoding)显得非常重要和关键,这将直接决定了系统的质量。然而,在自然语言处理领域中,传统的做法是将词表示成离散的符号,例如将 [cat] 表示为 [Id537],而 [dog] 表示为 [Id143]。这样做的缺点在于,没有提供足够的信息来体现词语之间的某种关联,例如尽
-
word2vec(word to vector)是一个将单词转换成向量形式的工具。可以把对文本内容的处理简化为向量空间中的向量运算,计算出向量空间上的相似度,来表示文本语义上的相似度。word2vec为计算向量词提供了一种有效的连续词袋(bag-of-words)和skip-gram架构实现。 来自维基百科对余弦距离的定义: 通过测量两个向量内积空间的夹角的余弦值来度量它们之间的相似性。0度角的余