
HotSpot为什么要分为新生代和老年代?

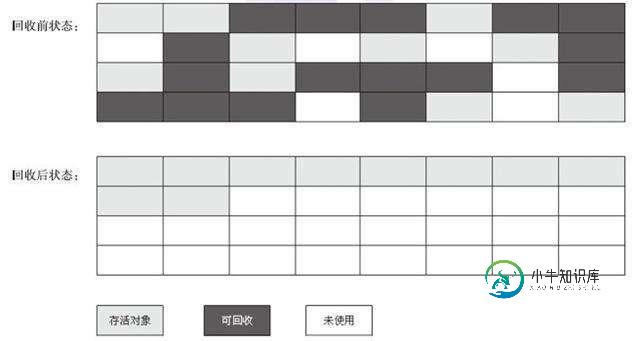
3.1 标记-清除算法
该算法分为“标记”和“清除”阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。它是最基础的收集算法,后续的算法都是对其不足进行改进得到。这种垃圾收集算法会带来两个明显的问题:
- 效率问题
- 空间问题(标记清除后会产生大量不连续的碎片)
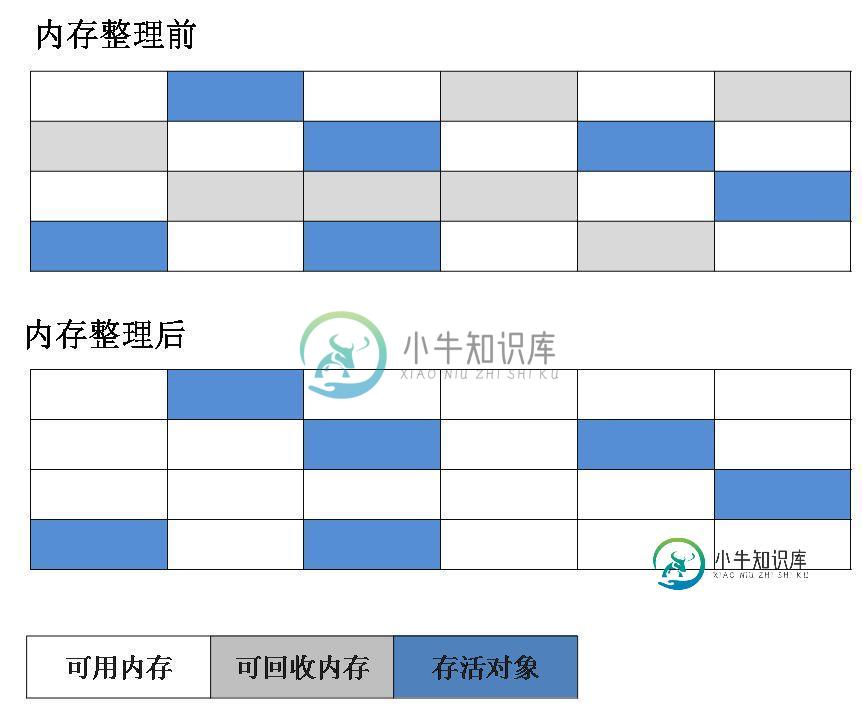
3.2 复制算法
为了解决效率问题,“复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
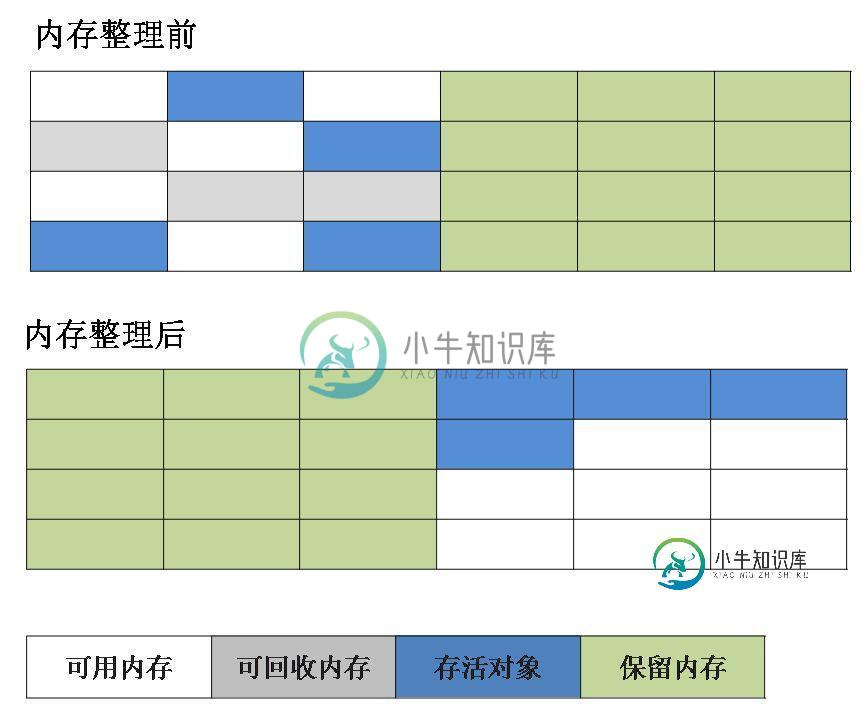
3.3 标记-整理算法
根据老年代的特点提出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存。
3.4 分代收集算法
当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将 java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
**比如在新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。
-
你能回答我一个关于JVM垃圾收集过程的问题吗? 为什么堆被分为伊甸园、幸存者空间和老一代? 当一个年轻的疏散被处理时,通过从根开始的引用访问对象,以找出无法到达的对象。可到达的对象标记为“活动”,不可到达的对象不标记,将被删除。 因此,所有对象都会被考虑,包括旧一代中分配的对象也会被访问并标记是否可以访问。 据我所知,同时回收年轻一代和老一代是非常困难的,因为这两代人位于内存中不同的连续部分。 但
-
我正在为max分配8GB内存给Java编写的应用程序。它会内存溢出。我相信年轻一代总是比默认情况下的老一代小(堆的1/4)。而Eden/幸存者1,2在年轻一代内部。我相信在Eden空间中创建了新对象。 即使老一代还没有满,但年轻一代已经完全满了,java应用程序还是会耗尽内存吗? 如果短寿命的对象比长寿命的对象多,那么可以为年轻一代分配更多内存,或者至少将堆的50%分配给年轻一代吗?或者,由于jv
-
我读了这篇文章“https://malloc.se/blog/zgc-jdk15,最后一个索引是关于
-
问题内容: 为什么要编译Python脚本?您可以直接从.py文件运行它们,并且效果很好,那么在性能上有什么优势吗? 我还注意到,我的应用程序中的某些文件被编译为.pyc,而另一些则没有,为什么? 问题答案: 它被编译为字节码,可以更快,更快速地使用。 无法编译某些文件的原因是,每次运行脚本时都会重新编译与之一起调用的主脚本。所有导入的脚本将被编译并存储在磁盘上。 Ben Blank的 重要补充:
-
我们使用G1收集器<当一个年轻的GC发生时(不是混合GC),堆的变化:[Eden:3666.0M(3666.0M)- 堆的变化为4819.1M(5346.0-526.9) 伊甸园改变了3666.0(3666.0-0.0)和幸存者-34M(20-54);为什么堆的变化不等于伊甸园和幸存者的总和(4819.1不等于(3666.0-34))?年轻的GC清除对象在老一代? gc日志: