
EM算法推导,jensen不等式确定的下界

参考回答:
给定的训练样本是 ,样例间独立,我们想找到每个样例隐含的类别z,能使得p(x,z)最大。p(x,z)的最大似然估计如下:
,样例间独立,我们想找到每个样例隐含的类别z,能使得p(x,z)最大。p(x,z)的最大似然估计如下:
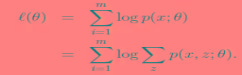
第一步是对极大似然取对数,第二步是对每个样例的每个可能类别z求联合分布概率和。但是直接求 一般比较困难,因为有隐藏变量z存在,但是一般确定了z后,求解就容易了。
一般比较困难,因为有隐藏变量z存在,但是一般确定了z后,求解就容易了。
EM是一种解决存在隐含变量优化问题的有效方法。竟然不能直接最大化 ,我们可以不断地建立
,我们可以不断地建立 的下界(E步),然后优化下界(M步)。这句话比较抽象,看下面的。
的下界(E步),然后优化下界(M步)。这句话比较抽象,看下面的。
对于每一个样例i,让表示该样例隐含变量z的某种分布, 满足的条件是
满足的条件是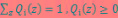 。(如果z是连续性的,那么
。(如果z是连续性的,那么 是概率密度函数,需要将求和符号换做积分符号)。比如要将班上学生聚类,假设隐藏变量z是身高,那么就是连续的高斯分布。如果按照隐藏变量是男女,那么就是伯努利分布了。
是概率密度函数,需要将求和符号换做积分符号)。比如要将班上学生聚类,假设隐藏变量z是身高,那么就是连续的高斯分布。如果按照隐藏变量是男女,那么就是伯努利分布了。
可以由前面阐述的内容得到下面的公式:

(1)到(2)比较直接,就是分子分母同乘以一个相等的函数。(2)到(3)利用了Jensen不等式,考虑到 是凹函数(二阶导数小于0),而且
是凹函数(二阶导数小于0),而且
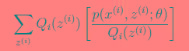
就是 的期望(回想期望公式中的Lazy Statistician规则)
的期望(回想期望公式中的Lazy Statistician规则)
设Y是随机变量X的函数 (g是连续函数),那么
(g是连续函数),那么
(1) X是离散型随机变量,它的分布律为 ,k=1,2,…。若
,k=1,2,…。若 绝对收敛,则有
绝对收敛,则有

(2) X是连续型随机变量,它的概率密度为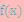 ,若
,若 绝对收敛,则有
绝对收敛,则有

对应于上述问题,Y是 ,X是
,X是 ,
,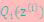 是
是 ,g是
,g是 到
到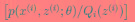 的映射。这样解释了式子(2)中的期望,再根据凹函数时的Jensen不等式:
的映射。这样解释了式子(2)中的期望,再根据凹函数时的Jensen不等式:

可以得到(3)。
这个过程可以看作是对 求了下界。对于
求了下界。对于 的选择,有多种可能,那种更好的?假设
的选择,有多种可能,那种更好的?假设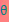 已经给定,那么
已经给定,那么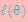 的值就决定于
的值就决定于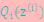 和
和 了。我们可以通过调整这两个概率使下界不断上升,以逼近
了。我们可以通过调整这两个概率使下界不断上升,以逼近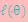 的真实值,那么什么时候算是调整好了呢?当不等式变成等式时,说明我们调整后的概率能够等价于
的真实值,那么什么时候算是调整好了呢?当不等式变成等式时,说明我们调整后的概率能够等价于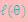 了。按照这个思路,我们要找到等式成立的条件。根据Jensen不等式,要想让等式成立,需要让随机变量变成常数值,这里得到:
了。按照这个思路,我们要找到等式成立的条件。根据Jensen不等式,要想让等式成立,需要让随机变量变成常数值,这里得到:
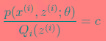
c为常数,不依赖于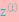 。对此式子做进一步推导,我们知道
。对此式子做进一步推导,我们知道 ,那么也就有
,那么也就有 ,(多个等式分子分母相加不变,这个认为每个样例的两个概率比值都是c),那么有下式:
,(多个等式分子分母相加不变,这个认为每个样例的两个概率比值都是c),那么有下式:
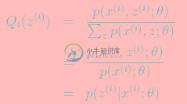
至此,我们推出了在固定其他参数 后,
后, 的计算公式就是后验概率,解决了
的计算公式就是后验概率,解决了 如何选择的问题。这一步就是E步,建立
如何选择的问题。这一步就是E步,建立 的下界。接下来的M步,就是在给定
的下界。接下来的M步,就是在给定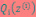 后,调整
后,调整 ,去极大化
,去极大化 的下界(在固定
的下界(在固定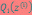 后,下界还可以调整的更大)。那么一般的EM算法的步骤如下:
后,下界还可以调整的更大)。那么一般的EM算法的步骤如下:
循环重复直到收敛{
(E步)对于每一个i,计算
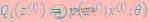
(M步)计算

那么究竟怎么确保EM收敛?假定 和
和 是EM第t次和t+1次迭代后的结果。如果我们证明了
是EM第t次和t+1次迭代后的结果。如果我们证明了 ,也就是说极大似然估计单调增加,那么最终我们会到达最大似然估计的最大值。下面来证明,选定
,也就是说极大似然估计单调增加,那么最终我们会到达最大似然估计的最大值。下面来证明,选定 后,我们得到E步
后,我们得到E步
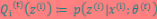
这一步保证了在给定 时,Jensen不等式中的等式成立,也就是
时,Jensen不等式中的等式成立,也就是

然后进行M步,固定 ,并将
,并将 视作变量,对上面的
视作变量,对上面的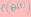 求导后,得到
求导后,得到 ,这样经过一些推导会有以下式子成立:
,这样经过一些推导会有以下式子成立:

解释第(4)步,得到 时,只是最大化
时,只是最大化 ,也就是
,也就是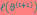 的下界,而没有使等式成立,等式成立只有是在固定
的下界,而没有使等式成立,等式成立只有是在固定 ,并按E步得到
,并按E步得到 时才能成立。
时才能成立。
况且根据我们前面得到的下式,对于所有的 和
和 都成立
都成立

第(5)步利用了M步的定义,M步就是将 调整到
调整到 ,使得下界最大化。因此(5)成立,(6)是之前的等式结果。这样就证明了
,使得下界最大化。因此(5)成立,(6)是之前的等式结果。这样就证明了 会单调增加。一种收敛方法是
会单调增加。一种收敛方法是 不再变化,还有一种就是变化幅度很小。
不再变化,还有一种就是变化幅度很小。
再次解释一下(4)、(5)、(6)。首先(4)对所有的参数都满足,而其等式成立条件只是在固定 ,并调整好Q时成立,而第(4)步只是固定Q,调整
,并调整好Q时成立,而第(4)步只是固定Q,调整 ,不能保证等式一定成立。(4)到(5)就是M步的定义,(5)到(6)是前面E步所保证等式成立条件。也就是说E步会将下界拉到与
,不能保证等式一定成立。(4)到(5)就是M步的定义,(5)到(6)是前面E步所保证等式成立条件。也就是说E步会将下界拉到与 一个特定值(这里
一个特定值(这里 )一样的高度,而此时发现下界仍然可以上升,因此经过M步后,下界又被拉升,但达不到与
)一样的高度,而此时发现下界仍然可以上升,因此经过M步后,下界又被拉升,但达不到与 另外一个特定值一样的高度,之后E步又将下界拉到与这个特定值一样的高度,重复下去,直到最大值。
另外一个特定值一样的高度,之后E步又将下界拉到与这个特定值一样的高度,重复下去,直到最大值。
如果我们定义

从前面的推导中我们知,EM可以看作是J的坐标上升法,E步固定 ,优化
,优化 ,M步固定
,M步固定 。优化
。优化
Jensen不等式表述如下:
如果f是凸函数,X是随机变量,那么: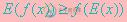 ,特别地,如果f是严格凸函数,当且
,特别地,如果f是严格凸函数,当且
仅当X是常量时,上式取等号。所以其下界是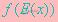 。
。
-
1. 变分推断EM算法求解LDA的思路 首先,回顾LDA的模型图如下: 变分推断EM算法希望通过“变分推断(Variational Inference)”和EM算法来得到LDA模型的文档主题分布和主题词分布。首先来看EM算法在这里的使用,我们的模型里面有隐藏变量$$theta,beta, z$$,模型的参数是$$alpha,eta$$。为了求出模型参数和对应的隐藏变量分布,EM算法需要在E步先求出
-
本文向大家介绍python em算法的实现,包括了python em算法的实现的使用技巧和注意事项,需要的朋友参考一下 以上就是python em算法的实现的详细内容,更多关于python em算法的资料请关注呐喊教程其它相关文章!
-
我们经常会从样本观察数据中,找出样本的模型参数。 最常用的方法就是极大化模型分布的对数似然函数。 但是在一些情况下,我们得到的观察数据有未观察到的隐含数据,此时我们未知的有隐含数据和模型参数,因而无法直接用极大化对数似然函数得到模型分布的参数。怎么办呢?这就是EM算法可以派上用场的地方了。 EM算法解决这个的思路是使用启发式的迭代方法,既然我们无法直接求出模型分布参数,那么我们可以先猜想隐含数据(
-
参考资料: http://blog.csdn.net/zouxy09/article/details/8537620 http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html 我的数据挖掘算法代码实现: https://github.com/linyiqun/DataMiningAlgorithm 介绍 em算法是一种迭代算法
-
本文向大家介绍Python列表推导式、字典推导式与集合推导式用法实例分析,包括了Python列表推导式、字典推导式与集合推导式用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python列表推导式、字典推导式与集合推导式用法。分享给大家供大家参考,具体如下: 推导式comprehensions(又称解析式),是Python的一种独有特性。推导式是可以从一个数据序列构建另一个新的
-
问题内容: 我有一个代码,其中单个goroutine将触发不确定数量的子goroutine,而后者又将触发更多的goroutine,依此类推。我的目标是等待所有子goroutine完成。 我不知道我将要预先触发的goroutine的总数,所以我不能使用sync.WaitGroup,理想情况下,我不必人为地限制通过channel- as- semaphore 模式运行的goroutine的总数。 简