
Oracle SQL:筛选仅相差很小时间的重复行

我有一个带有事件警报的Oracle表,由于奇怪而未知的情况,有时会重复发生警报,因此我被要求创建一个服务,该服务将从该Oracle表中删除重复的警报。
重复考虑一个警报(表中的一行)的条件是,存在另一个具有相同的PKN_EVENTNAME和RECEIVEDDATE的警报,它与前一个仅相差很小的时间(例如10秒,例如-
up或下-)。
我首先要做的是创建一个Oracle sql语句,该语句将按PKN_EVENTNAME将所有警报分组,并在每个组中将重复的警报分开(以供以后删除)。
我想我在路上,但是我被卡住了。
驴有任何帮助吗?
到目前为止,我的SQL:
select t1.ID, t1.PKN_EVENTNAME, t1.RECEIVEDDATE
from PARQUIMETERS_ALARMS t1
where
exists
(select 'x'
from PARQUIMETERS_ALARMS t2
where t1.id <> t2.id and -- Not the same row
trunc(t2.RECEIVEDDATE) = trunc(t1.RECEIVEDDATE) -- Same date
and abs(t1.RECEIVEDDATE - t2.RECEIVEDDATE) * 24 * 60 * 60 < 10) -- < 10 sec
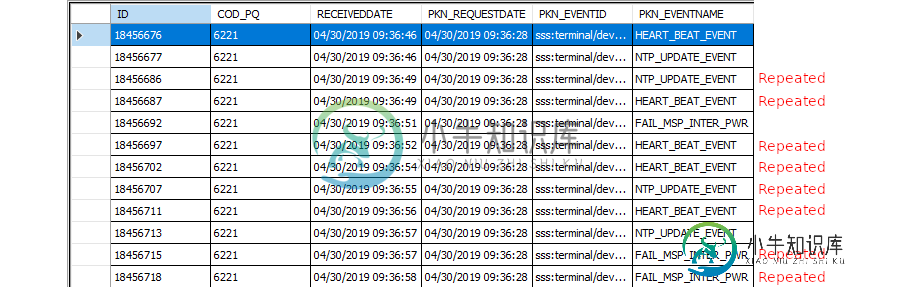
编辑1:
通过@Tejash更正,我在Visual Studio Oracle
SQL浏览器中看到了不同的结果,但是我无法理解它们。我不清楚结果是否已经是要删除的记录(重复的警报)还是什么。
问题答案:
您可以利用range分析函数的子句:
with dups as (
select t1.*
, row_number() over (
partition by PKN_EVENTNAME, RECEIVEDDATE
order by id
) as dup
from PARQUIMETERS_ALARMS t1
), nodups as (
select * from dups where dup = 1
), t as (
select nodups.ID, nodups.PKN_EVENTNAME, nodups.RECEIVEDDATE
, count(*) over (
partition by nodups.PKN_EVENTNAME
order by nodups.RECEIVEDDATE
range between interval '10' second preceding and current row
) as cnt
from nodups
)
select * from t where cnt = 1
(已更新:CTE,dups并且nodups在注释中显示的OP之后添加了重复的元组(PKN_EVENTNAME, RECEIVEDDATE)。)
说明:清除通过nodupsCTE传递的数据后,该where条件仅过滤在最近10 s中仅存在单行的行(显然是当前行)。
-
我的Oracle表有1,000个观察值,以下2个变量:(两个字段都是varchar) 我是不是漏掉了一些明显的东西? 谢谢
-
我需要过滤-21-11-20-28-12-20和预期的输出
-
我注意到以下代码在netbeans中是完全合法的: 然而eclipse对此并不满意,我必须这样初始化它: 有趣的是netbean建议不要在初始化部分指定类型参数,而是使用菱形运算符??我想知道这两种方法之间的区别。以及应该使用哪一种,这样代码就可以在不同的IDE中使用而不会有任何变化。
-
有一个矩阵a,比如: 我只想得到每行没有3个或更多数字的行,它们之间都有最大差异 此函数应仅返回第1行。
-
本文向大家介绍Powershell小技巧之复合筛选,包括了Powershell小技巧之复合筛选的使用技巧和注意事项,需要的朋友参考一下 当你分析文本日志或筛选不通类型的信息时,你通常要使用 Where-Object。这里有一个通用脚本来说明复合筛选:
-
这应该非常容易,但我无法让它工作。 我想根据两个或多个值筛选数据集。 这是否必须是一个或声明?我可以在SQL中使用?