
字典火车路线的最佳数据结构?

因此,我的任务是从本质上读取一个文件(记事本文件),该文件具有许多火车停靠站以及从一个停靠站到另一个停靠站所花费的时间。例如,它看起来像:
Stop A 15
Stop B 12
Stop C 9
现在,我需要返回并访问这些站点及其时间。我当时正在考虑读取文件并将其存储为字典。我的问题是,最好的字典是吗?还是有其他一些Python工具会被证明更有用?任何想法将不胜感激!
问题答案:
我会反驳说-直截了当的命令并不是最好的选择。
假设您有100个站点,并且有多条非字母和非数字的路线。想想巴黎地铁:
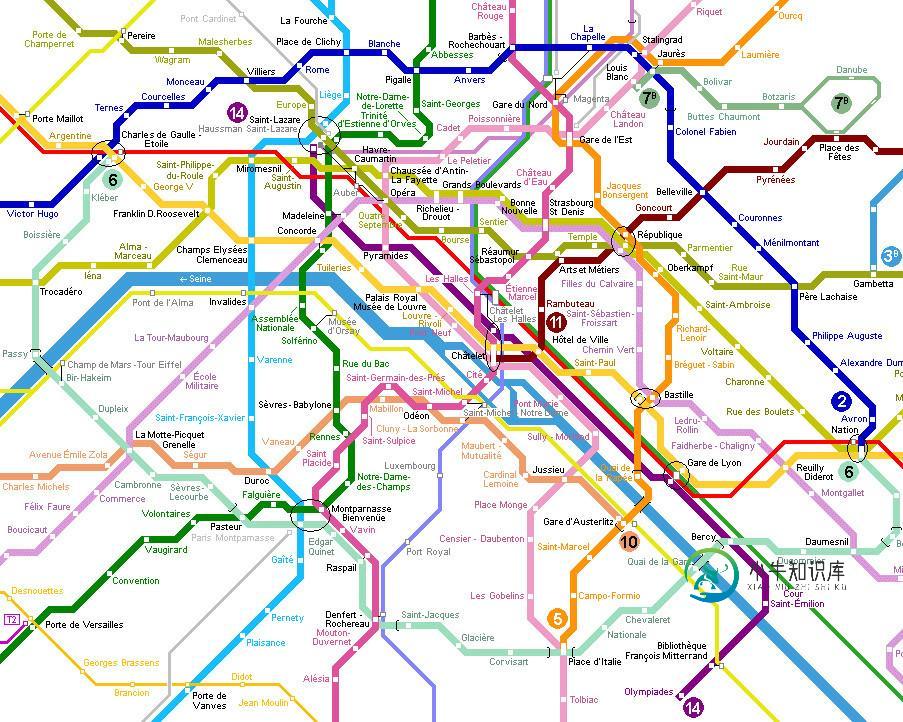
现在尝试使用直接的Python字典来计算FDR和La Fourche之间的时间吗?这涉及两个或多个不同的路线和多个选项。
甲树或某种形式的图形是较好的结构。字典对于1对1映射而言是极好的。树对于相互关联的节点的丰富描述更好。然后,您将使用类似Dijkstra的算法的导航方式。
由于嵌套的dict或list的dict是一个图,因此很容易提出一个递归示例:
def find_all_paths(graph, start, end, path=[]):
path = path + [start]
if start == end:
return [path]
if start not in graph:
return []
paths = []
for node in graph[start]:
if node not in path:
newpaths = find_all_paths(graph, node, end, path)
for newpath in newpaths:
paths.append(newpath)
return paths
def min_path(graph, start, end):
paths=find_all_paths(graph,start,end)
mt=10**99
mpath=[]
print '\tAll paths:',paths
for path in paths:
t=sum(graph[i][j] for i,j in zip(path,path[1::]))
print '\t\tevaluating:',path, t
if t<mt:
mt=t
mpath=path
e1=' '.join('{}->{}:{}'.format(i,j,graph[i][j]) for i,j in zip(mpath,mpath[1::]))
e2=str(sum(graph[i][j] for i,j in zip(mpath,mpath[1::])))
print 'Best path: '+e1+' Total: '+e2+'\n'
if __name__ == "__main__":
graph = {'A': {'B':5, 'C':4},
'B': {'C':3, 'D':10},
'C': {'D':12},
'D': {'C':5, 'E':9},
'E': {'F':8},
'F': {'C':7}}
min_path(graph,'A','E')
min_path(graph,'A','D')
min_path(graph,'A','F')
印刷品:
All paths: [['A', 'C', 'D', 'E'], ['A', 'B', 'C', 'D', 'E'], ['A', 'B', 'D', 'E']]
evaluating: ['A', 'C', 'D', 'E'] 25
evaluating: ['A', 'B', 'C', 'D', 'E'] 29
evaluating: ['A', 'B', 'D', 'E'] 24
Best path: A->B:5 B->D:10 D->E:9 Total: 24
All paths: [['A', 'C', 'D'], ['A', 'B', 'C', 'D'], ['A', 'B', 'D']]
evaluating: ['A', 'C', 'D'] 16
evaluating: ['A', 'B', 'C', 'D'] 20
evaluating: ['A', 'B', 'D'] 15
Best path: A->B:5 B->D:10 Total: 15
All paths: [['A', 'C', 'D', 'E', 'F'], ['A', 'B', 'C', 'D', 'E', 'F'], ['A', 'B', 'D', 'E', 'F']]
evaluating: ['A', 'C', 'D', 'E', 'F'] 33
evaluating: ['A', 'B', 'C', 'D', 'E', 'F'] 37
evaluating: ['A', 'B', 'D', 'E', 'F'] 32
Best path: A->B:5 B->D:10 D->E:9 E->F:8 Total: 32
-
字典类似于你通过联系人名字查找地址和联系人详细情况的地址簿,即,我们把键(名字)和值(详细情况)联系在一起。注意,键必须是唯一的,就像如果有两个人恰巧同名的话,你无法找到正确的信息。 注意,你只能使用不可变的对象(比如字符串)来作为字典的键,但是你可以不可变或可变的对象作为字典的值。基本说来就是,你应该只使用简单的对象作为键。 键值对在字典中以这样的方式标记:d = {key1 : value1,
-
主要内容:一、dict 字典,二、源码分析,三、总结一、dict 字典 在Redis中,字典就是HASH表。哈希表的优势在于查找速度快(理想状态下O(1)),但大小不好控制,大了浪费,小了冲突。而过多的冲突最终会使得哈希表退化。这就需要有一个处理机制,来达到容量和冲突解决的一个动态平衡。在Redis中,字典可以自动动态扩容,为了保证适应性和安全性,DICT不是一次完成扩容的,是渐进的,批次完成的。 二、源码分析 1、字典的定义: 如果简单的只是提供
-
问题内容: 我想要一个从键到对象,反之亦然的数据结构(与仅在单个方向上映射的HashMaps不同)。一个想法可能是将HashMap存储在其内部以进行反向查找,但这将是一种低效的方法。 双向映射的最佳实现是什么? 问题答案: 最简单的想法:包装器类包含2个映射,第二个包含交换的键/值。您将保持O(1)的复杂性,并且将仅使用稍微更多的内存,因为您(可能)将对象保留在那里。
-
我有几个不同的路由,但包含相似的参数。 示例: 请注意,所有三个视图都使用相同的图表控制器来控制视图。这是一个相当通用的控制器,但它需要在可用的图表类型之间切换。。。同时保持路线的其余部分<示例:(这不起作用) 有人知道如何在不完全重新键入或重建路由路径的情况下轻松更新路由参数吗?
-
我想做一个递归函数,减少振幅/时间图上的数据点,同时保留曲线的特征。我最初认为我应该使用一个循环,这里是粗略的伪代码; 空隙压缩(长度时间,幅度范围){ 检查长度时间的分辨率是否高于数据返回的分辨率(如果高于); 循环通过长度时间,得到最小和最大幅度; 如果最小和最大振幅之间的差异在振幅范围内,则存储最小和最大并返回; 如果没有,除以时间长度/4并调用compress(长度时间/4,范围); 然而
-
6.1 字典 字典是一种以键- 值对形式存储数据的数据结构,就像电话号码簿里的名字和电话号码一 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>字典sample</title> </head> <body> <script> function Dictionary(){ this.ad