
1.1. 版本控制的前世和今生
除了茫然未知的宇宙,几乎任何事物都是从无到有,从简陋到完善。随着时间车轮的滚滚向前,历史被抛在身后逐渐远去,如同我们的现代社会,世界大同,到处都是忙碌和喧嚣,再也看不到已经远去的刀耕火种、男耕女织的慢生活岁月。
版本控制系统是一个另类。虽然其历史并不短暂,也有几十年,但是它的演进过程却一直在社会的各个角落重复着,而且惊人的相似。有的人从未使用甚至从未听说过版本控制系统,他和他的团队就像停留在黑暗的史前时代,任由数据自生自灭。有的人使用着有几十年历史的CVS或其改良版Subversion,让时间空耗在网络连接的等待中。再有就是以Git为代表的分布式版本控制系统,已经风靡整个开源社区,正等待你的靠近。
1.1.1. 黑暗的史前时代
人们谈及远古,总爱以黑暗形容。黑暗实际上指的是秩序和工具的匮乏,而不是自然,如以自然环境而论,工业化和城市化对环境的破坏,现今才是最黑暗的年代。对软件开发来说也是如此,虽然遥远的C语言一统天下的日子,要比今天选Java,选.Net,还是选择脚本语言的多选题要简单得多,但是从工具和秩序上讲,过去的年代是黑暗的。
回顾一下我经历的版本控制的“史前时代”吧。在大学里,代码分散地拷贝在各个软盘中,最终我会被搞糊涂,不知道哪个软盘中的代码是最优的,因为最新并非最优,失败的重构会毁掉原来尚能运作的代码。在我工作的第一年,代码管理并未改观,还是以简单的目录拷贝进行数据的备份,三四个程序员利用文件服务器的目录共享进行协同,公共类库和头文件在操作过程中相互覆盖,痛苦不堪。很明显,那时我尚不知道版本控制系统为何物。我的版本控制史前时代一直延续到2000年,那时CVS已经诞生了14年,而我在那时对CVS还一无所知。
实际上,即便是在CVS出现之前的“史前时代”,也已经有了非常好用的源码比较和打补丁的工具:diff和patch,他们今天生命力依然顽强。大名鼎鼎的Linus Torvalds(Linux之父)也对这两个工具偏爱有加,在1991-2002年之间,Linus一直顽固地使用diff和patch管理着Linux的代码,即使不断有人提醒他CVS的存在[1]。
那么来看看diff和patch,熟悉它们将对理解版本控制系统(差异存储),使用版本控制系统(代码比较和冲突合并)都有莫大的好处。
1.1.1.1. 命令diff用于比较两个文本文件或目录的差异
先来构造两个文件[2]:
文件 hello | 文件 world |
|---|---|
应该杜绝文章中的错别子。 但是无论使用 * 全拼,双拼 * 还是五笔 是人就有可能犯错,软件更是如此。 犯了错,就要扣工资! 改正的成本可能会很高。 | 应该杜绝文章中的错别字。 但是无论使用 * 全拼,双拼 * 还是五笔 是人就有可能犯错,软件更是如此。 改正的成本可能会很高。 但是“只要眼球足够多,所有Bug都好捉”, 这就是开源的哲学之一。 |
对这两个文件执行diff命令,查看两个文件的差异。如下所示:
$ diff -u hello world | less -N
上面执行diff命令的-u参数很重要,使得差异输出中带有上下文。管道后面带有-N参数的less命令(按字母q退出)会在输出的每一行前面添加行号,便于对输出结果进行说明。
1 --- hello 2010-09-21 17:45:33.551610940 +0800 2 +++ world 2010-09-21 17:44:46.343610465 +0800 3 @@ -1,4 +1,4 @@ 4 -应该杜绝文章中的错别子。 5 +应该杜绝文章中的错别字。 6 7 但是无论使用 8 * 全拼,双拼 9 @@ -6,6 +6,7 @@ 10 11 是人就有可能犯错,软件更是如此。 12 13 -犯了错,就要扣工资! 14 - 15 改正的成本可能会很高。 16 + 17 +但是“只要眼球足够多,所有Bug都好捉”, 18 +这就是开源的哲学之一。
上面的差异文件,可以这么理解:
- 第1、2行作为差异文件的文件头,分别记录了用于比较的原始文件和目标文件的文件名及时间戳。第1行以三个减号(
---)开始,记录原始文件的文件名和时间戳,而第2行以三个加号(+++)开始,记录的是目标文件的文件名及时间戳。 - 在比较内容中,以减号(
-)开始的行是只出现在原始文件中的行,而在目标文件中不存在,即被删除的内容。例如:第4、13、14行。 - 在比较内容中,以加号(
+)开始的行是只出现在目标文件中的行,而在原始文件中不存在,即新增加的内容。例如:第5、16-18行。 - 在比较内容中,以空格开始的行,是在原始文件和目标文件中都出现的行,用于上下文参考。例如:第6-8、10-12、15行。
- 第3-8行是第一个差异小节。每个差异小节以一行定位语句开始。第3行就是一条差异定位语句,其前后分别用两个@进行标识。
- 第3行定位语句中
-1,4的含义是:本差异小节的内容相当于原始文件的从第1行开始的4行。不妨计算一下,第4、6、7、8行是原始文件中的内容,加起来刚好是4行。 - 第3行定位语句中
+1,4的含义是:本差异小节的内容相当于目标文件的从第1行开始的4行。第5、6、7、8行是目标文件中的内容,加起来刚好是4行。 - 第9-18行是第二个差异小节。第9行是一条定位语句。
- 第9行定位语句中
-6,6的含义是:本差异小节的内容相当于原始文件的从第6行开始的6行。统计一下,第10-15行是原始文件中的内容,加起来刚好是6行。 - 第9行定位语句中
+6,7的含义是:本差异小节的内容相当于目标文件的从第6行开始的7行。第10-12、15-18行是目标文件中的内容,加起来刚好是7行。 - 命令diff是基于行比较,所以即便只修改了一个字,也显示为一整行的修改(参见差异文件第4、5行)。Git对diff进行了扩展,提供一种逐词比较的差异比较方法,参见本书第2篇“11.4.4 差异比较:git diff”小节。
1.1.1.2. 命令patch相当于diff的反向操作
有了原始文件(hello)和差异文件(diff.txt),若目标文件(world)被删除或被覆盖,可以用下面的命令来恢复目标文件(world):
$ cp hello world $ patch world < diff.txt
反之亦然。用目标文件(world)和差异文件(diff.txt)来恢复原始文件(hello),使用如下操作:
$ cp world hello $ patch -R hello < diff.txt
命令diff和patch还可以对目录进行比较和恢复操作,这也就是Linus在1991-2002年用于维护Linux不同版本间差异的办法。可以用此命令,在没有版本控制系统的情况下,记录并保存改动前后的差异,还可以将差异文件注入版本控制系统(如果有的话)。
标准的diff和patch命令存在一个局限,就是不能对二进制文件进行处理。对二进制文件的修改或添加会在差异文件中缺失,进而丢失对二进制文件的改动或添加。Git对差异文件格式提供了扩展支持,支持二进制文件的比较,解决了这个问题。这点可以参考本书第7篇“第38章 补丁中的二进制文件”的相关内容。
1.1.2. CVS——开启版本控制大爆发
CVS(Concurrent Versions System)[3]诞生于1985年,是由荷兰阿姆斯特丹VU大学的Dick Grune教授实现的。当时Dick教授和两个学生共同开发一个项目,但是三个人的工作时间无法协调到一起,迫切需要一个记录和协同代码开发的工具软件。于是Dick教授通过脚本语言对RCS(一个针对单独文件的版本管理工具)进行封装,设计出有史以来第一个被大规模使用的版本控制工具。在Dick教授的网站上记录了CVS这段早期的历史。[4]
“在1985年一个糟糕的秋日里,我站在校汽车站等车回家,脑海里一直纠结着一件事 ——如何处理RCS文件、用户文件(工作区)和Entries文件的复杂关系,有的文件 可能会缺失、冲突、被删除,等等。我的头有些晕了,于是决定画一个大表,将复杂 的关联画在其中看看出来的结果是什么样的……”
1986年Dick教授通过新闻组发布了CVS,1989年由Brian Berliner将CVS用C语言重写。
从CVS的历史可以看出CVS不是设计出来的,而是被实际需要逼出来的,因此根据实用为上的原则,借用了已有的针对单一文件的多版本管理工具RCS。CVS采用客户端/服务器架构设计,版本库位于服务器端,实际上就是一个RCS文件容器。每一个RCS文件以“,v”作为文件名后缀,用于保存对应文件的历次更改历史。RCS文件中只保留一个版本的完全拷贝,其他历次更改仅将差异存储其中,使得存储变得更加高效。我在2008年设计的一个SVN管理后台pySvnManager[5],实际上也采用了RCS作为保存SVN授权文件变更记录的“数据库”。
图1-1展示了CVS版本控制系统的工作原理,可以看到作为RCS文件容器的CVS版本库和工作区目录结构的一一对应关系。
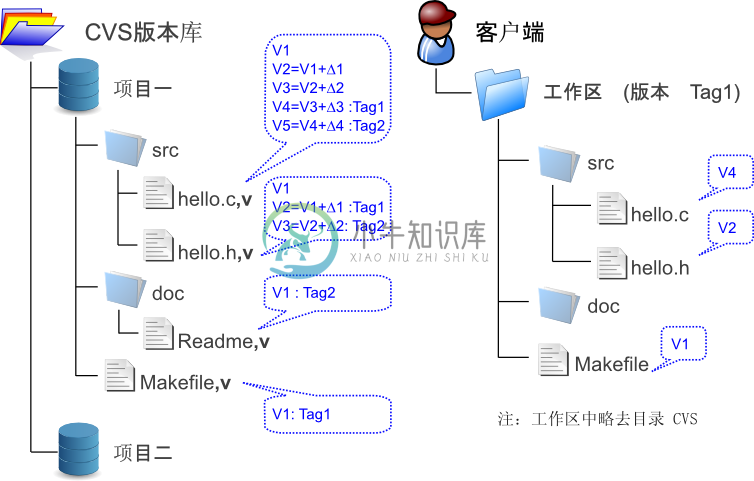
图1-1:CVS版本控制系统示意图
CVS的这种实现方式的最大好处就是简单。把版本库中随便一个目录拿出来就可以成为另外一个版本库。如果将版本库中的一个RCS文件重命名,工作区检出的文件名也相应地改变。这种低成本的服务器管理模式成为很多CVS粉丝至今不愿舍弃CVS的原因。
CVS的出现让软件工程师认识到了原来还可以这样协同工作。CVS成功地为后来的版本控制系统确立了标准,像提交(commit)、检入(checkin)、检出(checkout)、里程碑(tag或译为标签)、分支(branch)等概念早在CVS中就已经确立。CVS的命令行格式也被后来的版本控制系统竞相模仿。
在2001年,我正为使用CVS激动不已的时候,公司领导要求采用和美国研发部门同样的版本控制解决方案。于是,我的项目组率先进行了从CVS到该商业版本控制工具的迁移[6]。虽然商业版本控制工具有更漂亮的界面及更好的产品整合性,但是就版本控制本身而言,商业版本控制工具存在着如下缺陷。
- 采用黑盒子式的版本库设计。让人捉摸不透的版本库设计,最大的目的可能就是阻止用户再迁移到其他平台。
- 缺乏版本库整理工具。如果有一个文件(如记录核弹起爆密码的文件)检入到版本库中,就没有办法再彻底移除它。
- 商业版本控制工具很难为个人提供版本控制解决方案,除非个人愿意花费高昂的许可证费用。
- 商业版本控制工具注定是小众软件,对新员工的培训成本不可忽视。
而上述商业版本控制系统的缺点,恰恰是CVS及其他开源版本控制系统的强项。但在经历了最初的成功之后,CVS也尽显疲态:
- 服务器端松散的RCS文件,导致在建立里程碑或分支时缺乏效率,服务器端文件越多,速度越慢。
- 分支和里程碑不可见,因为它们被分散地记录在服务器端的各个RCS文件中。
- 合并困难重重,因为缺乏对合并的追踪从而导致重复合并,引发严重冲突。
- 缺乏对原子提交的支持,会导致客户端向服务器端提交不完整的数据。
- 不能优化存储内容相同但文件名不同的文件,因为在服务器端每个文件都是单独进行差异存储的。
- 不能对文件和目录的重命名进行版本控制,虽然直接在服务器端修改RCS文件名可以让改名后的文件保持历史,但是这样做实际会破坏历史。
- 网络操作效率不高,修改的文件在提交时要通过网络传输完整的文件,这是因为本地缺乏文件的原始拷贝而不能在提交前计算出差异数据。
CVS的成功开启了版本控制系统的大爆发,各式各样的版本控制系统如雨后春笋般地诞生了。新的版本控制系统或多或少地解决了CVS版本控制系统存在的问题。在这些版本控制系统中最典型的就是Subversion(SVN)。
1.1.3. SVN——集中式版本控制集大成者
Subversion[7],因其命令行工具名为svn因此通常被简称为SVN。SVN由CollabNet公司于2000年资助并发起开发,目的是创建一个更好用的版本控制系统以取代CVS。前期SVN的开发使用CVS做版本控制,到了2001年,SVN已经可以用于自己的版本控制了[8]。SVN成熟的标志是其完成了后端存储上的变革,即从一开始的BDB(简单的关系型数据库)到FSFS(文件数据库)的转变[9]。FSFS相对于BDB具有更高的稳定性、免维护性,以及实现的可视性。图1-2展示了采用FSFS作为存储后端的SVN版本控制系统的工作原理。
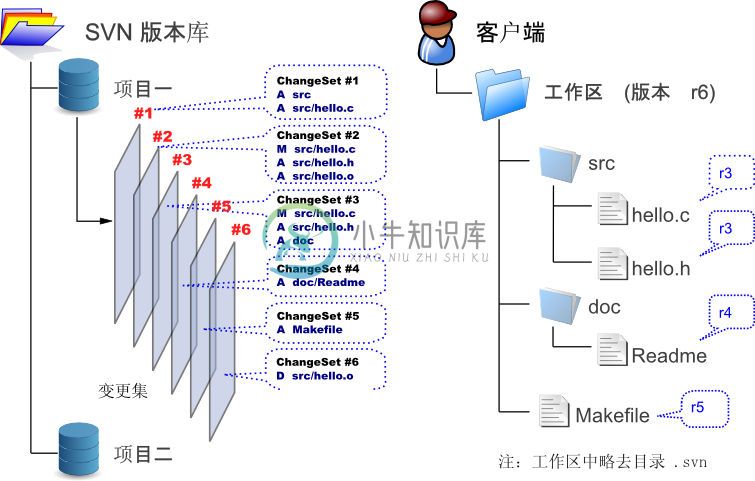
图1-2:SVN版本控制系统示意图
SVN的每一次提交,都会在服务器端的db/revs和db/revprops目录下各创建一个以顺序数字编号命名的文件。其中db/revs目录下 的文件(即变更集文件)记录与上一个提交之间的差异(字母A表示新增,M表示修改,D表示删除)。在db/revprops目录下的同名文件(没有在图1-2中体现)则保存着提交日志、作者、提交时间等信息(称作版本属性)。这样设计的好处有:
- 拥有全局版本号。每提交一次,SVN的版本号就会自动加一。这为SVN的使用提供了极大的便利。回想CVS时代,每个文件都拥有各自独立的版本号(RCS版本号),要想获得全局版本号,只能通过手工不断地建立里程碑(tag)来实现。
- 实现了原子提交。SVN不会像CVS那样出现部分文件被提交而其他文件由于故障没有被提交的状态。
- 文件名不受限制。因为服务器端不再需要建立和客户端文件相似的文件名,这样,文件的命名就不再受服务器操作系统的字符集及大小写的限制。
- 文件和目录重命名也得到了支持。
SVN最具特色的功能是轻量级拷贝,例如将目录trunk拷贝为branches/v1.x的操作类似于创建符号链接(仅需在db/revs下的变更集文件中用特定的语法标注一下),是轻量级操作,可快速完成。利用轻量级拷贝,SVN在不同的名字空间下创建不同的目录实现里程碑和分支的创建,轻松地解决了CVS中存在的里程碑、分支创建速度慢又不可见的问题。使用SVN创建里程碑和分支只在眨眼之间。
SVN在版本库授权上也有改进,不再像CVS那样依赖操作系统本身对版本库目录和文件进行授权,而是采用授权文件的方式来实现。
SVN还有一个突破,就是在工作区跟踪目录(.svn目录)下为当前目录中的每一个文件都保存一份冗余的原始拷贝。这样做的好处一个是提高了网络的效率,在提交时仅传输变更差异,另外一个好处是部分操作不再需要网络连接,如本地修改的差异比较,以及本地更改的回退等。
正是由于SVN的这些闪亮的功能,使得SVN成为继CVS之后诞生的诸多版本控制系统中的集大成者,成为开源社区一时的新宠,也成为当时各个企业版本控制的最佳选择之一。
但是SVN相对CVS在本质上并没有突破,都属于集中式版本控制系统,即一个项目只有唯一的一个版本库与之对应,所有的项目成员都通过网络向该服务器进行提交。单点故障是集中式版本控制的死穴,并由此带来数据备份和数据恢复的管理成本。此外集中式版本控制系统还存在着提交瓶颈。
所谓提交瓶颈就是单位时间内版本库允许的提交数量的限制。当提交非常密集时,会出现有的用户始终无法完成本地工作区的改动和服务器最新版本间的合并,其所做的改动无法提交的状况。为避免过早地出现提交瓶颈,SVN允许本地出现混杂版本(即工作区文件版本不一致,有的可能是最新版本,有的可能是历史版本),并可以针对部分目录、文件进行提交。这种非全量的提交方式会导致版本库中文件状态不可测,即本地提交前代码编译、运行是完好的,但被他人更新出来的版本存在bug。
集中式版本控制系统对分布式开发支持得不好,在局域网之外使用SVN,单是查看日志、提交数据等操作的延迟,就足以让基于广域网协同工作的团队抓狂了。
除了集中式版本控制系统固有的问题外,SVN的里程碑、分支的设计也被证明是一个错误,虽然这个错误使得SVN拥有了快速创建里程碑和分支的能力,但是这个错误导致了如下的更多问题。
项目文件在版本库中必须按照一定的目录结构进行部署,否则就可能无法建立里程碑和分支。
我在项目咨询过程中就见过很多团队,直接在版本库的根目录下创建项目文件。这样的版本库布局,在需要创建里程碑和分支时就无从下手了,因为根目录是不能拷贝到子目录中的。所以SVN的用户在创建版本库时必须遵守一个古怪的约定:先创建三个顶级目录
/trunk、/tags和/branches。创建里程碑和分支会破坏精心设计的授权。
SVN的授权是基于目录的,分支和里程碑也被视为目录(和其他目录没有分别)。因此每次创建分支或里程碑时,就要将针对
/trunk目录及其子目录的授权在新建的分支或里程碑上重建。随着分支和里程碑数量的增多,授权愈加复杂,维护也愈加困难。虽然在SVN 1.5之后拥有了合并追踪功能,但仅适用于单向的合并追踪。
SVN的合并追踪信息并非由合并提交本身提供,而是通过记录在合并的目标目录之上、由独立于合并提交之外的属性提供的,是单边而非双边的。所以这种合并追踪方式仅适用于分支间的单向合并,对双向合并和复杂的多分支合并帮助不大。
2009年底,SVN由CollabNet公司交由Apache社区管理,至此SVN成为了Apache的一个子项目[10]。这对SVN到底意味着什么?是开发的停滞,还是新的开始,结果如何我们将拭目以待。
1.1.4. Git——Linus的第二个伟大作品
Linux之父Linus是坚定的CVS反对者,他也同样地反对SVN。这就是为什么在1991-2002这十余年间,Linus宁可使用补丁文件和tar包的方式维护代码,也迟迟不愿使用CVS。2002年Linus顶着开源社区精英们的口诛笔伐,选择了一个商业版本控制系统BitKeeper作为Linux内核的代码管理工具[11]。和CVS/SVN不同,BitKeeper是属于分布式版本控制系统。
分布式版本控制系统最大的反传统之处在于,可以不需要集中式的版本库,每个人都工作在通过克隆操作建立的本地版本库中,也就是说每个人都拥有一个完整的版本库。分布式版本控制系统的几乎所有操作包括查看提交日志、提交、创建里程碑和分支、合并分支、回退等都直接在本地完成而不需要网络连接。每个人都是本地版本库的主人,不再有谁能提交谁不能提交的限制,加之多样的协同工作模型(版本库间推送、拉回,及补丁文件传送等)让开源项目的参与度有爆发式增长。
2005年发生的一件事最终导致了Git的诞生。在2005年初Andrew Tridgell,即大名鼎鼎的Samba的作者,试图尝试对BitKeeper反向工程,以开发一个能与BitKeeper交互的开源工具。这激怒了BitKeeper软件的所有者BitMover公司,要求收回对Linux社区免费使用BitKeeper的授权[12]。迫不得已,Linus选择了自己开发一个分布式版本控制工具以替代BitKeeper。以下是Git诞生大事记[13]:
- 2005年4月3日,开始开发Git。
- 2005年4月6日,项目发布。
- 2005年4月7日,Git就可以作为自身的版本控制工具了。
- 2005年4月18日,发生第一个多分支合并。
- 2005年4月29日,Git的性能就已经达到了Linus的预期。
- 2005年6月16日,Linux核心2.6.12发布,那时Git已经在维护Linux核心的源代码了。
Linus以一个文件系统专家和内核设计者的视角对Git进行了设计,其独特的设计,让Git拥有非凡的性能和存储管理。完成原型设计后,在2005年7月26日,Linus功成身退,将Git的维护交给另外一个Git的主要贡献者Junio C Hamano[14],直到现在。
最初的Git除了一些核心命令以外,其他的都用脚本语言开发,而且每个功能都作为一条独立的命令,例如克隆操作的命令git-clone,提交操作的命令git-commit。这导致Git拥有庞大的命令集,使用习惯也和其他版本控制系统格格不入。随着Git的开发者和使用者的增加,Git的使用界面也变得更友好。例如到1.5.4版本时,将一百多个独立的命令封装为一个git命令,使用习惯已经和其他版本控制工具非常一致了。
在Git出现之前,SVN曾是开源项目版本控制的毋庸置疑的首选,但是在Git诞生后的短短几年,开源项目中再一次出现了版本控制系统的大迁移,Git取代SVN成为当之无愧的版本控制之王。看看下面这些使用Git的项目吧,各个都耳熟能详:Linux kernel、Perl、Eclipse、Gnome、KDE、Qt、Ruby on Rails、Android、PostgreSQL、Debian、X.org,当然还有GitHub上的上百万个项目。
成为版本控制之王,Git当之无愧。
安全性强。
抵御了kernel.org在2011年的黑客事件。 Git管理的每一个文件、目录、提交等都使用SHA1哈希值。
分布式。
No delta, 全量提交。
提交的父子关系和分支。
DAG。提交
| [1] | Linus Torvalds于2007-05-03在Google的演讲:http://www.youtube.com/watch?v=4XpnKHJAok8 |
| [2] | 文件中特意留下的错别字(“字”误为“子”),是便于演示文件的差异比较。 |
| [3] | http://www.nongnu.org/cvs/ |
| [4] | http://dickgrune.com/Programs/CVS.orig/ |
| [5] | http://pysvnmanager.sourceforge.net/ |
| [6] | 于是就有了这篇文章:http://www.worldhello.net/doc/cvs_vs_starteam/ |
| [7] | http://subversion.apache.org/ |
| [8] | http://svnbook.red-bean.com/en/1.5/svn.intro.whatis.html |
| [9] | http://subversion.apache.org/docs/release-notes/1.2.html |
| [10] | http://en.wikipedia.org/wiki/Apache_Subversion |
| [11] | http://en.wikipedia.org/wiki/BitKeeper |
| [12] | http://en.wikipedia.org/wiki/Andrew_Tridgell |
| [13] | http://en.wikipedia.org/wiki/Git_%28software%29 |
| [14] | http://marc.info/?l=git&m=112243466603239 |