
备份还原
79.概述
备份和还原是许多数据库提供的标准操作。有效的备份和还原策略有助于确保用户可以在发生意外故障时恢复数据。 HBase 备份和还原功能有助于确保使用 HBase 作为规范数据存储库的企业可以从灾难性故障中恢复。另一个重要功能是能够将数据库还原到特定时间点,通常称为快照。
HBase 备份和还原功能可以在 HBase 集群中的表上创建完整备份和增量备份。完整备份是应用增量备份以构建迭代快照的基础。可以按计划运行增量备份以捕获随时间的变化,例如通过使用 Cron 任务。增量备份比完全备份更具成本效益,因为它们仅捕获自上次备份以来的更改,并且还使管理员能够将数据库还原到任何先前的增量备份。此外,如果您不想还原备份的整个数据集,则实用程序还可以启用表级数据备份和恢复。
备份和还原功能是对 HBase Replication 功能的补充。虽然 HBase 复制非常适合创建数据的“热”副本(复制数据可立即用于查询),但备份和恢复功能非常适合创建“冷”数据副本(必须采取手动步骤)恢复系统)。以前,用户只能通过 ExportSnapshot 功能创建完整备份。增量备份实现是对 ExportSnapshot 提供的先前“艺术”的新颖改进。
备份和还原功能使用 DistCp 在群集之间传输文件。 HADOOP-15850 修复了一个错误,即 CopyCommitter#concatFileChunks 无条件地尝试将 DistCp 的文件连接到目标集群(尽管这些文件是独立的)。如果没有 HADOOP-15850 的修复,转移将失败。因此备份和恢复功能需要 hadoop 版本,如下所示
2.7.x
2.8.x
2.9.2+
2.10.0+
3.0.4+
3.1.2+
3.2.0+
3.3.0+
80.术语
备份和还原功能引入了新术语,可用于了解控制如何在系统中流动。
_ 备份 _:数据和元数据的逻辑单元,可以将表恢复到特定时间点的状态。
_ 完全备份 _:一种备份类型,它在某个时间点完全封装表的内容。
_ 增量备份 _:一种备份类型,包含自完整备份以来表中的更改。
_ 备份集 _:用户定义的名称,它引用一个或多个可以执行备份的表。
_ 备份 ID_ :一个唯一的名称,用于标识其余的备份,例如
backupId_1467823988425
81.规划
有一些常用策略可用于在您的环境中实现备份和还原。以下部分显示了如何实施这些策略并确定每种策略的潜在权衡。
此备份和还原工具尚未在启用了透明数据加密(TDE)的 HDFS 群集上进行测试。这与未决问题 HBASE-16178 有关。
81.1。在群集内备份
此策略将备份存储在与备份所在的群集相同的群集上。这种方法仅适用于测试,因为它不会在软件本身提供的任何内容之外提供任何额外的安全性。
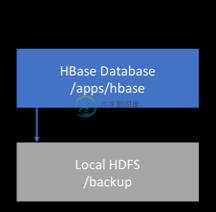 图 4.群集内备份
图 4.群集内备份
81.2。使用专用群集进行备份
此策略提供更高的容错能力,并提供了一条灾难恢复途径。在此设置中,您将备份存储在单独的 HDFS 群集上,方法是将备份目标群集的 HDFS URL 提供给备份实用程序。您应该考虑备份到不同的物理位置,例如不同的数据中心。
通常,备份专用 HDFS 群集使用更经济的硬件配置文件来节省资金。
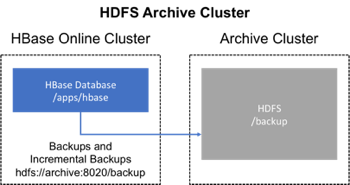 图 5.专用 HDFS 群集备份
图 5.专用 HDFS 群集备份
81.3。备份到云或存储供应商设备
保护 HBase 增量备份的另一种方法是将数据存储在属于第三方供应商且位于非现场的配置的安全服务器上。供应商可以是公共云提供商或使用 Hadoop 兼容文件系统的存储供应商,例如 S3 和其他与 HDFS 兼容的目标。
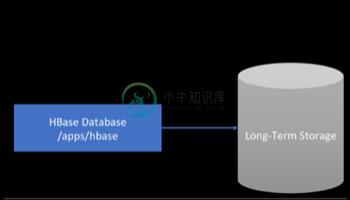 图 6.备份到云或供应商存储解决方案
图 6.备份到云或供应商存储解决方案
HBase 备份实用程序不支持备份到多个目标。解决方法是从 HDFS 或 S3 手动创建备份文件的副本。
82.首次配置步骤
本节包含必须进行的必要配置更改才能使用备份和还原功能。由于此功能大量使用 YARN 的 MapReduce 框架来并行化这些 I / O 繁重操作,因此配置更改仅在hbase-site.xml之外扩展。
82.1。允许 YARN 中的“hbase”系统用户
YARN container-executor.cfg 配置文件必须具有以下属性设置: allowed.system.users = hbase 。此配置文件的条目中不允许有空格。
在执行第一个备份任务时,跳过此步骤将导致运行时错误。
用于备份和恢复的有效 container-executor.cfg 文件示例:
yarn.nodemanager.log-dirs=/var/log/hadoop/mapred
yarn.nodemanager.linux-container-executor.group=yarn
banned.users=hdfs,yarn,mapred,bin
allowed.system.users=hbase
min.user.id=500
82.2。 HBase 特定的变化
将以下属性添加到 hbase-site.xml 并重新启动 HBase(如果它已在运行)。
“,...”是一个省略号,意味着这是一个以逗号分隔的值列表,而不是应该添加到 hbase-site.xml 的文本文本。
<property>
<name>hbase.backup.enable</name>
<value>true</value>
</property>
<property>
<name>hbase.master.logcleaner.plugins</name>
<value>org.apache.hadoop.hbase.backup.master.BackupLogCleaner,...</value>
</property>
<property>
<name>hbase.procedure.master.classes</name>
<value>org.apache.hadoop.hbase.backup.master.LogRollMasterProcedureManager,...</value>
</property>
<property>
<name>hbase.procedure.regionserver.classes</name>
<value>org.apache.hadoop.hbase.backup.regionserver.LogRollRegionServerProcedureManager,...</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.hadoop.hbase.backup.BackupObserver,...</value>
</property>
<property>
<name>hbase.master.hfilecleaner.plugins</name>
<value>org.apache.hadoop.hbase.backup.BackupHFileCleaner,...</value>
</property>
83.备份和恢复命令
这包括管理员用于创建,还原和合并备份的命令行实用程序。有关检查特定备份会话详细信息的工具将在下一节备份映像管理中介绍。
运行命令hbase backup help <command>以访问提供有关命令及其选项的基本信息的联机帮助。以下信息将在此帮助消息中针对每个命令进行捕获。
83.1。创建备份映像
| |
对于也使用 Apache Phoenix 的 HBase 集群:在备份中包含 SQL 系统目录表。如果需要还原 HBase 备份,则可以通过访问系统目录表来恢复 Phoenix 与已还原数据的互操作性。
|
运行备份和还原实用程序的第一步是执行完全备份,并将数据存储在与源不同的映像中。至少,您必须执行此操作才能获得基准,然后才能依赖增量备份。
以 HBase 超级用户身份运行以下命令:
hbase backup create <type> <backup_path>
命令完成运行后,控制台将显示 SUCCESS 或 FAILURE 状态消息。 SUCCESS 消息包括 _ 备份 _ ID。备份 ID 是 HBase 主机从客户端收到备份请求的 Unix 时间(也称为 Epoch 时间)。
| |
记录成功备份结束时显示的备份 ID。如果源群集出现故障并且您需要使用还原操作恢复数据集,则备份 ID 随时可用可以节省时间。
|
83.1.1。位置命令行参数
_ 类型 _
要执行的备份类型:_ 完整 _ 或 _ 增量 。提醒一下, 增量 _ 备份需要 _ 完整 _ 备份才能存在。
_backup _ 路径 _
_backup _ 路径 _ 参数指定存储备份映像的位置的完整文件系统 URI。有效的前缀是 hdfs:, webhdfs:, s3a: 或其他兼容的 Hadoop 文件系统实现。
83.1.2。命名命令行参数
-t <table_name></table_name>
要备份的以逗号分隔的表列表。如果未指定表,则备份所有表。不存在正则表达式或通配符支持;必须明确列出所有表名。有关对表集合执行操作的更多信息,请参见备份集。与 -s 选项互斥;其中一个命名选项是必需的。
-s <backup_set_name></backup_set_name>
根据备份集确定要备份的表。有关备份集的用途和用法,请参阅使用备份集。与 -t 选项互斥。
-w <number_workers></number_workers>
(可选)指定将数据复制到备份目标的并行工作器数。备份当前由 MapReduce 作业执行,因此该值对应于作业将生成的 Mapper 数。
-b <bandwidth_per_worker></bandwidth_per_worker>
(可选)指定每个工作线程的带宽,以 MB /秒为单位。
-d
(可选)启用“DEBUG”模式,该模式打印有关备份创建的其他日志记录。
-q<name></name>
(可选)允许指定应在其中执行创建备份的 MapReduce 作业的 YARN 队列的名称。此选项有助于防止备份任务从其他高重要性 MapReduce 作业中窃取资源。
83.1.3。用法示例
$ hbase backup create full hdfs://host5:8020/data/backup -t SALES2,SALES3 -w 3
此命令在路径 / data / backup 中的 NameNode 为 host5:8020 的 HDFS 实例中创建两个表 SALES2 和 SALES3 的完整备份映像。 -w 选项指定不超过三个并行工作完成操作。
83.2。恢复备份映像
以 HBase 超级用户身份运行以下命令。您只能在正在运行的 HBase 集群上还原备份,因为必须将数据重新分发到 RegionServers 才能成功完成操作。
hbase restore <backup_path> <backup_id>
83.2.1。位置命令行参数
backup_path
The backup_path argument specifies the full filesystem URI of where to store the backup image. Valid prefixes are hdfs:, webhdfs:, s3a: or other compatible Hadoop File System implementations.
_backup id
唯一标识要还原的备份映像的备份 ID。
83.2.2。命名命令行参数
-t <table_name></table_name>
要还原的以逗号分隔的表列表。有关对表集合执行操作的更多信息,请参见备份集。与 -s 选项互斥;其中一个命名选项是必需的。
-s <backup_set_name></backup_set_name>
Identify tables to backup based on a backup set. See Using Backup Sets for the purpose and usage of backup sets. Mutually exclusive with the -t option.
-q<name></name>
(Optional) Allows specification of the name of a YARN queue which the MapReduce job to create the backup should be executed in. This option is useful to prevent backup tasks from stealing resources away from other MapReduce jobs of high importance.
-c
(可选)执行还原的干运行。检查操作,但不执行。
-m <target_tables></target_tables>
(可选)要还原到的以逗号分隔的表列表。如果未提供此选项,则使用原始表名。提供此选项时,-t选项中必须提供相同数量的条目。
-o
(可选)如果表已存在,则覆盖还原的目标表。
83.2.3。用法示例
hbase restore /tmp/backup_incremental backupId_1467823988425 -t mytable1,mytable2
此命令恢复增量备份映像的两个表。在此示例中:•/tmp/backup_incremental是包含备份映像的目录的路径。 •backupId_1467823988425是备份 ID。 •mytable1和mytable2是要还原的备份映像中的表的名称。
83.3。合并增量备份映像
此命令可用于将两个或多个增量备份映像合并为单个增量备份映像。这可用于将多个小型增量备份映像合并为一个较大的增量备份映像。此命令可用于将每小时增量备份合并到每日增量备份映像中,或每日增量备份合并到每周增量备份中。
$ hbase backup merge <backup_ids>
83.3.1。位置命令行参数
_backup ids
以逗号分隔的增量备份映像 ID 列表,这些 ID 将组合到单个映像中。
83.3.2。命名命令行参数
没有。
83.3.3。用法示例
$ hbase backup merge backupId_1467823988425,backupId_1467827588425
83.4。使用备份集
备份集可以通过减少表名重复输入的数量来简化 HBase 数据备份和还原的管理。您可以使用hbase backup set add命令将表分组到命名备份集中。然后,您可以使用-set选项在hbase backup create或hbase restore中调用备份集的名称,而不是单独列出组中的每个表。您可以拥有多个备份集。
请注意
hbase backup set add命令和 _- 设置 _ 选项之间的区别。必须在使用其他命令中的-set选项之前运行hbase backup set add命令,因为在将备份集用作快捷方式之前,必须对备份集进行命名和定义。
如果运行hbase backup set add命令并指定系统上尚不存在的备份集名称,则会创建一个新集。如果运行具有现有备份集名称的命令的命令,则指定的表将添加到该集。
在此命令中,备份集名称区分大小写。
备份集的元数据存储在 HBase 中。如果您无法访问具有备份集元数据的原始 HBase 集群,则必须指定单个表名以还原数据。
要创建备份集,请以 HBase 超级用户身份运行以下命令:
$ hbase backup set <subcommand> <backup_set_name> <tables>
83.4.1。备份集子命令
以下列表详细介绍了 hbase backup set 命令的子命令。
在 hbase backup set 设置完成操作后,必须输入以下子命令中的一个(且不超过一个)。此外,备份集名称在命令行实用程序中区分大小写。
_ 加 _
将表[s]添加到备份集。在此参数后指定 _backup_set _ 名称 _ 值以创建备份集。
_ 删除 _
从集中删除表。在 tables 参数中指定要删除的表。
_ 清单 _
列出所有备份集。
_ 描述 _
显示备份集的描述。该信息包括该集是具有完整备份还是增量备份,备份的开始和结束时间以及集合中的表列表。此子命令必须位于 _backup_set _ 名称 _ 值的有效值之前。
_ 删除 _
删除备份集。在hbase backup set delete命令后直接输入 _backup_set _ 名称 _ 选项的值。
83.4.2。位置命令行参数
_backup_set _ 名称 _
用于分配或调用备份集名称。备份集名称必须仅包含可打印字符,并且不能包含任何空格。
_ 表 _
要包含在备份集中的表(或单个表)的列表。输入表名作为逗号分隔列表。如果未指定表,则所有表都包含在集中。
维护区分大小写的备份集名称的日志或其他记录以及单独或远程群集上的每个集中的相应表,备份策略。如果主群集出现故障,此信息可以帮助您。
83.4.3。用法示例
$ hbase backup set add Q1Data TEAM3,TEAM_4
根据环境的不同,此命令会导致 _ 一个 _ 执行以下操作:
如果
Q1Data备份集不存在,则会创建包含表TEAM_3和TEAM_4的备份集。如果
Q1Data备份集已存在,则表TEAM_3和TEAM_4将添加到Q1Data备份集。
84.备份图像的管理
hbase backup命令有几个子命令,有助于在累积时管理备份映像。大多数生产环境都需要重复备份,因此必须使用实用程序来帮助管理备份存储库的数据。通过某些子命令,您可以查找有助于识别与搜索特定数据相关的备份的信息。您还可以删除备份映像。
以下列表详细介绍了可以帮助管理备份的每个hbase backup subcommand。以 HBase 超级用户身份运行完整的 command-subcommand 行。
84.1。管理备份进度
您可以通过运行 _hbase 备份进度 _ 命令并将备份 ID 指定为参数来监视另一个终端会话中正在运行的备份。
例如,以 hbase 超级用户身份运行以下命令以查看备份进度
$ hbase backup progress <backup_id>
84.1.1。位置命令行参数
backup_id
通过查看进度信息指定要监视的备份。 backupId 区分大小写。
84.1.2。命名命令行参数
None.
84.1.3。用法示例
hbase backup progress backupId_1467823988425
84.2。管理备份历史记录
此命令显示备份会话的日志。每个会话的信息包括备份 ID,类型(完整或增量),备份中的表,状态以及开始和结束时间。使用可选的-n 参数指定要显示的备份会话数。
$ hbase backup history <backup_id>
84.2.1。位置命令行参数
backup_id
Specifies the backup that you want to monitor by seeing the progress information. The backupId is case-sensitive.
84.2.2。命名命令行参数
-n <num_records></num_records>
(可选)最大备份记录数(默认值:10)。
-p <backup_root_path></backup_root_path>
存储备份映像的完整文件系统 URI。
-s <backup_set_name></backup_set_name>
要获取其历史记录的备份集的名称。与 -t 选项互斥。
-t<table_name></table_name>
获取历史记录的表的名称。与 -s 选项互斥。
84.2.3。用法示例
$ hbase backup history
$ hbase backup history -n 20
$ hbase backup history -t WebIndexRecords
84.3。描述备份映像
此命令可用于获取有关特定备份映像的信息。
$ hbase backup describe <backup_id>
84.3.1。位置命令行参数
backup_id
要描述的备份映像的 ID。
84.3.2。命名命令行参数
None.
84.3.3。用法示例
$ hbase backup describe backupId_1467823988425
84.4。删除备份映像
此命令可用于删除不再需要的备份映像。
$ hbase backup delete <backup_id>
84.4.1。位置命令行参数
backup_id
应删除备份映像的 ID。
84.4.2。命名命令行参数
None.
84.4.3。用法示例
$ hbase backup delete backupId_1467823988425
84.5。备份修复命令
此命令尝试更正由于软件错误或未处理的故障情况而存在的持久备份元数据中的任何不一致。虽然备份实现尝试自行更正所有错误,但在系统无法自动恢复的情况下,此工具可能是必需的。
$ hbase backup repair
84.5.1。位置命令行参数
None.
84.6。命名命令行参数
None.
84.6.1。用法示例
$ hbase backup repair
85.配置键
备份和还原功能包括必需和可选配置键。
85.1。必需的属性
hbase.backup.enable :控制是否启用该功能(默认值:false)。将此值设置为true。
hbase.master.logcleaner.plugins :清除 HBase Master 中的日志时调用的逗号分隔的类列表。将此值设置为org.apache.hadoop.hbase.backup.master.BackupLogCleaner或将其附加到当前值。
hbase.procedure.master.classes :用 Master 中的 Procedure 框架调用的逗号分隔的类列表。将此值设置为org.apache.hadoop.hbase.backup.master.LogRollMasterProcedureManager或将其附加到当前值。
hbase.procedure.regionserver.classes :使用 RegionServer 中的 Procedure 框架调用的逗号分隔的类列表。将此值设置为org.apache.hadoop.hbase.backup.regionserver.LogRollRegionServerProcedureManager或将其附加到当前值。
hbase.coprocessor.region.classes :在表上部署的以逗号分隔的 RegionObservers 列表。将此值设置为org.apache.hadoop.hbase.backup.BackupObserver或将其附加到当前值。
hbase.master.hfilecleaner.plugins :部署在 Master 上的以逗号分隔的 HFileCleaners 列表。将此值设置为org.apache.hadoop.hbase.backup.BackupHFileCleaner或将其附加到当前值。
85.2。可选属性
hbase.backup.system.ttl :hbase:backup表中数据的生存时间(以秒为单位)(默认值:永久)。此属性仅在创建hbase:backup表之前相关。当此表已存在时,使用 HBase shell 中的alter命令修改 TTL。有关此配置属性的影响的更多详细信息,请参见下面的部分。
hbase.backup.attempts.max :获取 hbase 表快照时尝试执行的次数(默认值:10)。
hbase.backup.attempts.pause.ms :失败的快照尝试之间等待的时间(以毫秒为单位)(默认值:10000)。
hbase.backup.logroll.timeout.millis :等待 RegionServers 在 Master 的过程框架中执行 WAL 滚动的时间(以毫秒为单位)(默认值:30000)。
86.最佳做法
86.1。制定恢复策略并对其进行测试。
在依赖生产环境的备份和还原策略之前,请确定必须如何执行备份,更重要的是,必须如何执行还原。测试计划以确保其可行。至少,从不同群集或服务器上的生产群集存储备份数据。要进一步保护数据,请使用位于不同物理位置的备份位置。
如果由于计算机系统问题导致主生产群集上的数据丢失不可恢复,则可以从同一站点的其他群集或服务器还原数据。然而,破坏整个站点的灾难使本地存储的备份变得毫无用处。考虑存储备份数据和必要资源(计算能力和操作员专业知识),以便在远离生产站点的站点恢复数据。如果在整个主要站点(火灾,地震等)发生灾难,远程备份站点可能非常有价值。
86.2。首先保护完整备份映像。
作为基准,您必须至少完成一次 HBase 数据的完整备份,然后才能依赖增量备份。完整备份应存储在源群集之外。要确保完整的数据集恢复,必须使用还原基准完全备份选项运行还原实用程序。完整备份是数据集的基础。在还原操作期间,将在完全备份的顶部应用增量备份数据,以使您返回上次执行备份的时间点。
86.3。为作为整个数据集的逻辑子集的表组定义和使用备份集。
您可以将表分组到称为备份集的对象中。当您有一组特定的表,您希望重复备份或还原时,备份集可以节省时间。
创建备份集时,键入要包括在组中的表名。备份集不仅包括相关表组,还包含 HBase 备份元数据。然后,您可以调用备份集名称以指示哪些表适用于命令执行,而不是单独输入所有表名。
86.4。记录备份和还原策略,理想情况下记录有关每个备份的信息。
记录整个过程,以便知识库可以在员工离职后转移给新的管理员。作为额外的安全预防措施,还要记录日历日期,时间以及有关每个备份数据的其他相关详细信息。在源群集发生故障或主站点灾难的情况下,此元数据可能有助于查找特定数据集。维护所有文档的重复副本:生产集群站点的一个副本和备份位置的另一个副本,或管理员从生产集群远程访问的任何位置。
87.场景:在 Amazon S3 上保护应用程序数据集
此业务情景描述了假设的零售业务如何使用备份来保护应用程序数据,然后在故障后恢复数据集。
HBase 管理团队使用备份集来存储来自一组表的数据,这些表具有名为 green 的应用程序的相关信息。在此示例中,一个表包含事务记录,另一个表包含客户详细信息。需要备份这两个表并将其作为一个组进行恢复。
管理团队还希望确保自动进行每日备份。
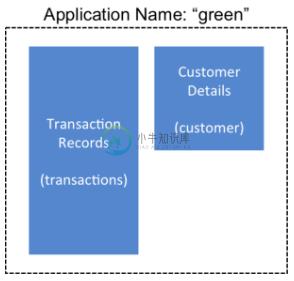 图 7.组成备份集的表
图 7.组成备份集的表
以下是用于备份 green 应用程序的数据并稍后恢复数据的命令步骤和示例的概述。以 HBase 超级用户身份登录时,将运行所有命令。
创建名为 _green set 的备份集作为事务表和 customer 表的别名。备份集可用于所有操作,以避免键入每个表名。备份集名称区分大小写,应仅使用可打印字符且不带空格。
$ hbase backup set add green_set transactions $ hbase backup set add green_set customergreen_set 数据的第一个备份必须是完整备份。以下命令示例显示如何将凭据传递到 Amazon S3 并使用 s3a:前缀指定文件系统。
$ ACCESS_KEY=ABCDEFGHIJKLMNOPQRST $ SECRET_KEY=123456789abcdefghijklmnopqrstuvwxyzABCD $ sudo -u hbase hbase backup create full\ s3a://$ACCESS_KEY:SECRET_KEY@prodhbasebackups/backups -s green_set应根据计划运行增量备份,以确保在发生灾难时进行必要的数据恢复。在这家零售公司,HBase 管理团队决定自动每日备份可以充分保护数据。团队决定通过修改
/etc/crontab中定义的现有 Cron 作业来实现此目的。因此,IT 通过添加以下行来修改 Cron 作业:@daily hbase hbase backup create incremental s3a://$ACCESS_KEY:$SECRET_KEY@prodhbasebackups/backups -s green_set灾难性 IT 事件会禁用绿色应用程序使用的生产群集。备份群集的 HBase 系统管理员必须将 _green _ 集 _ 数据集还原到最接近恢复目标的时间点。
> 如果备份 HBase 群集的管理员具有可访问记录中具有相关详细信息的备份 ID,则可以绕过以下使用
hdfs dfs -ls命令进行的搜索并手动扫描备份 ID 列表。请考虑在环境中的生产群集外部持续维护和保护备份 ID 的详细日志。HBase 管理员在存储备份的目录上运行以下命令,以在控制台上打印成功备份 ID 的列表:
`hdfs dfs -ls -t /prodhbasebackups/backups`管理员扫描列表以查看在最接近恢复目标的日期和时间创建了哪个备份。为此,管理员将恢复时间点的日历时间戳转换为 Unix 时间,因为备份 ID 是用 Unix 时间唯一标识的。备份 ID 按反向时间顺序列出,这意味着最先出现的最新成功备份。
管理员注意到命令输出中的以下行与需要恢复的 _green _ 集 _ 备份相对应:
/prodhbasebackups/backups/backup_1467823988425`管理员恢复 green_set 调用备份 ID 和-overwrite 选项。 -overwrite 选项截断目标中的所有现有数据,并使用备份数据集中的数据填充表。如果没有此标志,备份数据将附加到目标中的现有数据。在这种情况下,管理员决定覆盖数据,因为它已损坏。
$ sudo -u hbase hbase restore -s green_set \ s3a://$ACCESS_KEY:$SECRET_KEY@prodhbasebackups/backups backup_1467823988425 \ -overwrite
88.备份数据的安全性
利用此功能可以将数据复制到远程位置,请花点时间清楚地说明数据安全性存在的程序问题。与 HBase 复制功能一样,备份和还原提供了将数据从公司边界自动复制到该边界之外的某个系统的构造。在存储具有备份和恢复功能的敏感数据时,除了从 HBase 中提取数据的任何功能,发送数据的位置都经过安全审核以确保只允许经过身份验证的用户访问该数据时,这一点非常重要。
例如,对于将数据备份到 S3 的上述示例,最重要的是将适当的权限分配给 S3 存储桶以确保仅允许最小的一组授权用户访问该数据。由于不再通过 HBase 访问数据及其身份验证和授权控制,因此我们必须确保存储该数据的文件系统提供相当级别的安全性。这是用户必须自行实施的手动步骤。
89.增量备份和还原的技术细节
与之前尝试使用串行备份和还原解决方案(例如仅使用 HBase 导出和导入 API 的方法)相比,HBase 增量备份可以更有效地捕获 HBase 表映像。增量备份使用“预写日志”(WAL)来捕获自上次备份创建以来的数据更改。在所有 RegionServers 上执行 WAL roll(创建新的 WAL)以跟踪需要在备份中的 WAL。
创建增量备份映像后,源备份文件通常与数据源位于同一节点上。类似于 DistCp(分布式副本)工具的过程用于将源备份文件移动到目标文件系统。当表恢复操作开始时,启动两步过程。首先,从完整备份映像恢复完整备份。其次,来自上次完全备份和正在恢复的增量备份之间的增量备份的所有 WAL 文件都将转换为 HFiles,HBase 批量装入实用程序会自动将其导入为表中的已还原数据。
您只能在活动的 HBase 群集上进行还原,因为必须重新分发数据才能成功完成还原操作。
90.关于文件系统增长的警告
提醒一下,通过保留 HBase 主要用于数据持久性的预写日志来实现增量备份。因此,为确保需要包含在备份中的所有数据在系统中仍然可用,HBase 备份和还原功能将保留自上次备份以来的所有预写日志,直到执行下一个增量备份。
与 HBase 快照一样,对于高容量表,这可能对 HBase 的 HDFS 使用产生预期的巨大影响。注意启用和使用备份和还原功能,尤其要注意在未主动使用备份会话时删除备份会话。
用于备份和还原的保留预写日志的唯一自动上限基于hbase:backup系统表的 TTL,截至本文档编写时,该 TTL 是无限的(备份表条目永远不会自动删除)。这要求管理员按照计划执行备份,该计划的频率相对于 HDFS 上的可用空间量(例如,较少的可用 HDFS 空间需要更积极的备份合并和删除)。提醒一下,可以使用 HBase shell 中的alter命令在hbase:backup表上更改 TTL。在系统表存在后修改 hbase-site.xml 中的配置属性hbase.backup.system.ttl无效。
91.能力规划
在设计分布式系统部署时,必须执行一些基本的数学严谨性,以确保在给定系统的数据和软件要求的情况下有足够的计算能力。对于此功能,在估计某些备份和还原实施的性能时,网络容量的可用性是最大的瓶颈。第二个最昂贵的功能是可以读/写数据的速度。
91.1。完全备份
要估计完整备份的持续时间,我们必须了解调用的一般操作:
每个 RegionServer 上的预写日志滚动:并行每个 RegionServer 几十秒。相对于每个 RegionServer 的负载。
获取表格的 HBase 快照:几十秒。相对于构成表的区域和文件的数量。
将快照导出到目标:请参阅下文。相对于数据的大小和到目的地的网络带宽。
为了估计最后一步将花费多长时间,我们必须对硬件做出一些假设。请注意,而非对您的系统来说是准确的 - 这些是您或您的管理员对您的系统所知的数字。假设在单个节点上从 HDFS 读取数据的速度上限为 80MB / s(在该主机上运行的所有 Mapper 上),现代网络接口控制器(NIC)支持 10Gb / s,架顶式交换机可以处理 40Gb / s,集群之间的 WAN 为 10Gb / s。这意味着您只能以 1.25GB / s 的速度向远程数据库发送数据 - 这意味着参与 ExportSnapshot 的 16 个节点(1.25 * 1024 / 80 = 16)应该能够完全饱和集群之间的链接。由于群集中有更多节点,我们仍然可以使网络饱和,但对任何一个节点的影响较小,这有助于确保本地 SLA。如果快照的大小是 10TB,这将完全备份将占用 2.5 小时的球场(10 * 1024 / 1.25 / (60 * 60) = 2.23hrs)
作为一般声明,本地群集与远程存储之间的 WAN 带宽很可能是完全备份速度的最大瓶颈。
当关注点限制备份对“生产系统”的计算影响时,上述公式可以与hbase backup create:-b,-w,-q的可选命令行参数一起使用。 -b选项定义每个工作程序(Mapper)写入数据的带宽。 -w参数限制将在 DistCp 作业中生成的工作器数量。 -q允许用户指定 YARN 队列,该队列可以限制生成工作人员的特定节点 - 这可以将执行复制的备份工作人员隔离到一组非关键节点。将-b和-w选项与我们之前的公式相关联:-b将用于限制每个节点以完全 80MB / s 的速度读取数据,-w用于限制作业产生 16 个工作任务。
91.2。增量备份
就像我们为完整备份所做的那样,我们必须了解增量备份过程以接近其运行时和成本。
识别自上次完全备份或增量备份以来的新预写日志:可忽略不计。来自备份系统表的先验知识。
读取,过滤和写入“最小化”文件等同于 WALls:以写入数据的速度为主。相对于 HDFS 的写入速度。
将 HFiles 分配到目的地:见上文。
对于第二步,此操作的主要成本是重写数据(假设 WAL 中的大多数数据被保留)。在这种情况下,我们可以假设每个节点的聚合写入速度为 30MB / s。继续我们的 16 节点集群示例,这需要大约 15 分钟来执行 50GB 数据(50 * 1024/60/60 = 14.2)的此步骤。启动 DistCp MapReduce 作业的时间可能会主导复制数据所需的实际时间(50 / 1.25 = 40 秒),可以忽略。
92.备份和还原实用程序的限制
串口备份操作
备份操作不能同时运行。操作包括创建,删除,还原和合并等操作。仅支持一个活动备份会话。 HBASE-16391 将引入多备份会话支持。
无法取消备份
备份和还原操作都无法取消。 ( HBASE-15997 , HBASE-15998 )。取消备份的解决方法是终止客户端备份命令(control-C),确保已退出所有相关的 MapReduce 作业,然后运行hbase backup repair命令以确保系统备份元数据一致。
备份只能保存到一个位置
将备份信息复制到多个位置是留给用户的练习。 HBASE-15476 将引入本质上指定多备份目的地的能力。
需要 HBase 超级用户访问
只允许 HBase 超级用户(例如 hbase)执行备份/恢复,这可能会对共享 HBase 安装造成问题。当前的缓解措施需要与系统管理员协调,以构建和部署备份和恢复策略( HBASE-14138 )。
备份恢复是在线操作
要从备份执行还原,需要 HBase 集群在线作为当前实现的警告( HBASE-16573 )。
某些操作可能会失败并需要重新运行
HBase 备份功能主要由客户端驱动。虽然 HBase 连接中内置了标准的 HBase 重试逻辑,但执行操作中的持久性错误可能会传播回客户端(例如,由于区域分裂导致的快照失败)。应将备份实现从客户端移动到将来的 ProcedureV2 框架中,这将为瞬态/可重试故障提供额外的稳健性。 hbase backup repair命令用于纠正系统无法自动检测和恢复的状态。
避免申报公共 API
虽然存在与此功能交互的 Java API 并且其实现与接口分离,但是已经应用了不足以确定它是否正是我们打算发送给用户的确切内容。因此,它被标记为Private受众,期望随着用户开始尝试该功能,将需要修改,这将需要破坏兼容性( HBASE-17517 )。
缺乏备份和恢复的全局指标
单独的备份和恢复操作包含有关操作所包含的工作量的指标,但没有集中位置(例如主 UI)提供消费信息( HBASE-16565 )。