
架构
66. 概述
66.1. NoSQL?
HBase 是一种 "NoSQL" 数据库。"NoSQL" 是一个通用术语,意味着数据库不像 RDBMS 一样支持 SQL 作为主要访问语言,现有许多类型 NoSQL 数据库:BerkeleyDB 是一种本地 NoSQL 数据库,而 HBase 更适合称为分布数据库。从技术上讲,HBase 实际上更像是“数据存储”而不是“数据库”,因为它缺少很多在 RDBMS 中能找到的功能,例如类型列,二级索引,触发器和高级查询语言等。
但是,HBase 具有许多支持线性和模块化缩放的功能。 HBase 集群通过添加托管在商用服务器上的 RegionServer 进行扩展。举个例子,如果一个集群从 10 个 RegionServer 扩展到 20 个,那么它的存储和处理能力都会翻倍。 RDBMS 同样可以很好地扩展,但会达到一个上限 - 特别是单个数据库服务器的大小 - 并且为了获得最佳性能,需要专门的硬件和存储设备。 HBase 的特点是:
-
强一致读/写:HBase 不是”最终一致”的数据存储。这使得它非常适合高速计数聚合等任务。
-
自动分片:HBase 表通过 region 分布在集群上,并且随着数据的增长,region 会自动分割和重新分配。
-
RegionServer 自动故障转移
-
集成 Hadoop/HDFS:HBase 支持 HDFS 作为其分布式文件系统。
-
MapReduce:HBase 可以作为 source 和 sink,通过 MapReduce 来支持大规模并行处理。
-
Java 客户端 API:HBase 支持易用的 Java API 以进行编程式访问。
-
Thrift/REST API:对于非 Java 前端访问,HBase 还支持 Thrift 和 REST 方式。
-
块缓存和布隆过滤器:HBase 支持块缓存和布隆过滤器,以实现高容量查询优化。
-
运维管理:HBase 提供内置网页监控运维情况,并支持 JMX 指标。
66.2. 什么时候应该使用 HBase?
HBase 并不适合解决所有问题。
第一,确认有足够的数据。如果有上亿或数十亿行数据,那么 HBase 是一个好的选择。如果只有几千或几百万行数据,那么使用传统的 RDBMS 或许是个更好的选择,因为全部数据可能会被调度到单独一个(或者两个)节点上,集群的其他节点可能是空闲的。
第二,确认可以不用 RDBMS 提供的所有额外功能(例如,类型列,二级索引,事务,高级查询语言等)。针对 RDBMS 构建的应用程序无法通过简单地更改 JDBC Driver 就“移植”到 HBase。从 RDBMS 迁移到 HBase 需要完全重新设计而不是移植。
第三,确认有足够的硬件设施。少于 5 个 DataNode 时,HDFS 甚至什么都做不了(由于诸如 HDFS 块复制默认值为 3 之类的情况),再加上 NameNode。
HBase 可以在笔记本电脑上独立运行 - 但是这只应该被当做开发配置
66.3. HBase 和 Hadoop/HDFS 有什么不同?
[HDFS](https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html)是一个分布式文件系统,非常适合存储大型文件。其文档指出,它不是通用文件系统,并且不提供文件中的快速单个记录查找。另一方面,HBase 建立在 HDFS 之上,为大型表提供快速记录查找(和更新)。有时这可能是概念混淆的点。 HBase 内部将数据放在有索引的“StoreFiles”中,存储在 HDFS 之上,以进行高速查找。有关 HBase 如何实现其目标的更多信息,请参见[数据模型](#datamodel)和本章的其余部分。
67. 目录表
目录表 hbase:meta 作为 HBase 表存在,虽然它会从 HBase shell 的 list 命令中过滤掉,但实际上它也是一个表,像任何其他表一样。
67.1. hbase:meta
hbase:meta 表(以前称为.META.)保存系统中所有 region 的列表,hbase:meta 被存储在 ZooKeeper 中。
hbase:meta 表的结构如下:
Key
- Region key 的格式 (
[table],[region start key],[region id])
Values
-
info:regioninfo(当前 region 的序列化实例 HRegionInfo) -
info:server(包含当前 region 的 RegionServer 的 server:port) -
info:serverstartcode(包含此 region 的 RegionServer 进程的开始时间)
当一个表处于拆分过程中时,将创建额外两个列,称为 “info:splitA” 和 “info:splitB”。这些列代表两个子 region。它们的值也是序列化后的 HRegionInfo 实例。region 分割完成后,最终将删除此行。
HRegionInfo 说明
空白 key 用于表示表的开始和结束。拥有空白开始 key 的 region 是表中的第一个 region。如果某个 region 同时包含空白开始 key 和空白结束 key,则它是表中唯一的 region
在(希望不太可能)需要编程处理目录元数据的场景下,请参阅[RegionInfo.parseFrom](https://hbase.apache.org/devapidocs/org/apache/hadoop/hbase/client/RegionInfo.html#parseFrom-byte:A-)实用程序。
67.2. 启动顺序
首先,在 ZooKeeper 中查询 hbase:meta 的位置信息。然后,使用服务器和启动编码更新 hbase:meta 的值
有关 region-RegionServer 分配的信息,参阅Region-RegionServer Assignment。
68. 客户端
HBase 客户端会查找为所关注的特定行范围提供服务的 RegionServer。它通过查询 hbase:meta 表来完成此操作。详情参见[hbase:meta](#arch.catalog.meta)。在找到所需的 region 之后,客户端联系服务该 region 的 RegionServer 发出读取或写入请求,而不是通过 master。此信息被缓存在客户端中,以便后续请求无需经过查找过程。如果 region 由主负载均衡器重新分配,或者因为 RegionServer 已经死亡,则客户端将重新查询目录表以确定用户 region 的新位置。
有关 Master 对 HBase Client 通信的影响的详细信息,请参阅Runtime Impact
管理功能是通过 Admin 实例完成的
68.1. 集群连接
HBase 1.0 中更改了 API。有关连接配置信息,请参阅连接到 HBase 集群的客户端配置和依赖关系。
68.1.1. HBase 1.0.0 的 API
API 已被清理,使用者会通过接口而不是具体类型来工作。在 HBase 1.0 中,从 ConnectionFactory 中获取一个 Connection 对象,然后根据需要从中获取 Table,Admin 和 RegionLocator 的实例。完成后,关闭获取的实例。最后,确保在退出之前清理 Connection 实例。Connections 是重量级对象,但是线程安全,因此可以在应用程序中创建并保持一个实例。Table,Admin 和 RegionLocator 实例是轻量级的。它们可以随时创建,然后在使用后立即释放掉。有关新 HBase 1.0 API 的使用示例,请参阅Client Package Javadoc 说明。
68.1.2. HBase 1.0.0 之前的 API
1.0.0 之前,HTable 实例是与 HBase 集群进行交互的方式。 _[Table](https://hbase.apache.org/apidocs/org/apache/hadoop/hbase/client/Table.html)实例不是线程安全的。在任何给定时间,只有一个线程可以使用 Table 的实例。创建 Table 实例时,建议使用相同的 [HBaseConfiguration](https://hbase.apache.org/apidocs/org/apache/hadoop/hbase/HBaseConfiguration)实例。确保将 ZooKeeper 和套接字实例共享到 RegionServers,通常也是你想要的。例如,推荐这种方式:
HBaseConfiguration conf = HBaseConfiguration.create();
HTable table1 = new HTable(conf, "myTable");
HTable table2 = new HTable(conf, "myTable");
而不是这种:
HBaseConfiguration conf1 = HBaseConfiguration.create();
HTable table1 = new HTable(conf1, "myTable");
HBaseConfiguration conf2 = HBaseConfiguration.create();
HTable table2 = new HTable(conf2, "myTable");
关于 HBase 客户端如何处理连接的更多信息,请参阅 ConnectionFactory.
连接池
For applications which require high-end multithreaded access (e.g., web-servers or application servers that may serve many application threads in a single JVM), you can pre-create a Connection, as shown in the following example: 对于需要高级多线程访问的应用程序(例如,在单个 JVM 中为许多应用程序线程提供服务的 Web 服务器或应用服务器),你可以预先创建一个Connection,示例如下:
Example 22. 预创建一个 Connection
// Create a connection to the cluster.
Configuration conf = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(conf);
Table table = connection.getTable(TableName.valueOf(tablename))) {
// use table as needed, the table returned is lightweight
}
HTablePool已经废弃本指南的早期版本讨论了
HTablePool,不过它在 HBase 0.94, 0.95 和 0.96 版本中被废弃,并在 0.98.1 版本中被删除,HBASE-6580,而HConnection,在 HBase 1.0 中被Connection代替。请改用Connection。
68.2. WriteBuffer 和批处理方法
在 HBase 1.0 和后续版本中,HTable 被废弃,改用 Table。Table 并不使用自动刷新。如果需要缓冲写入,使用 BufferedMutator 类。
在 HBase 2.0 及更高版本中,HTable 不使用 BufferedMutator 来执行 Put 操作。有关更多信息,请参阅HBASE-18500。
关于写入持久性的更多信息,请参阅 ACID semantics 。
对于批量 Put 或 Delete 的细粒度控制,请参阅 Table 方法 batch。
68.3. 异步客户端
HBase 2.0 中引入了一种新 API,旨在提供异步访问 HBase 的能力。
你可以从 ConnectionFactory 中获取 AsyncConnection,然后从中获取一个异步表实例来访问 HBase。处理完成后,关闭 AsyncConnection 实例(通常在程序退出时)。
对于异步表,大多数方法与旧的 Table 接口具有相同的含义,返回值通常用 CompletableFuture 包装。 因为这里没有任何缓冲区,所以没有异步表的 close 方法,你不需要关闭它。它是线程安全的。
对于 scan,有几点不同:
-
仍然有一个
getScanner方法返回一个ResultScanner。可以以旧方式使用它,它的工作方式类似于旧的ClientAsyncPrefetchScanner。 -
有一个
scanAll方法,它会立即返回所有结果。它的目的是为通常希望立即获得全部结果的小范围扫描提供更简单的方法。 -
观察者模式。 有一个 scan 方法接受
ScanResultConsumer作为参数。 它会将结果传递给消费者。
请注意,AsyncTable 接口是模板化的。模板参数指定扫描使用的 ScanResultConsumerBase 的类型,这意味着观察者类型的 scan API 是不同的。scan 的消费者有两种类型 - ScanResultConsumer 和 AdvancedScanResultConsumer。
ScanResultConsumer 需要一个单独的线程池,用于执行注册到返回 CompletableFuture 的回调方法。因为使用独立的线程池可以释放 RPC 线程,所以回调可以自由地执行任何操作。如果回调慢或不确定的时候,使用此配置。
AdvancedScanResultConsumer 在框架线程内执行回调。不允许在回调中进行耗时操作,否则它可能会阻塞框架线程并导致非常糟糕的性能问题。正如其名称一样,它专为希望编写高性能代码的高级用户而设计。有关如何使用它编写完全异步代码,请参阅 org.apache.hadoop.hbase.client.example.HttpProxyExample。
68.4. 异步管理
你可以从 ConnectionFactory 中获取 AsyncConnection,然后从中获取一个 AsyncAdmin 实例来访问 HBase。请注意,有两个 getAdmin 方法可以获取 AsyncAdmin 实例。一种方法有一个额外的线程池参数,用于执行回调。它专为普通用户设计。另一种方法不需要线程池,所有回调都在框架线程内执行,因此不允许在回调中进行耗时操作。它专为高级用户设计。
默认的 getAdmin 方法将返回一个使用默认配置的 AsyncAdmin 实例。如果要自定义某些配置,可以使用 getAdminBuilder 方法获取用于创建 AsyncAdmin 实例的 AsyncAdminBuilder。用户可以自由设置他们关注的配置来创建一个新的 AsyncAdmin 实例。
对于 AsyncAdmin 接口,大多数方法与旧的 Admin 接口具有相同的含义,返回值通常被 CompletableFuture 包装。
For region name, we only accept byte[] as the parameter type and it may be a full region name or a encoded region name. For server name, we only accept ServerName as the parameter type. For table name, we only accept TableName as the parameter type. For list* operations, we only accept Pattern as the parameter type if you want to do regex matching. 对于大多数管理操作,当返回的 CompletableFuture 完成时,也意味着管理操作已完成。但是对于压缩操作,它只意味着压缩请求被发送到 HBase 并且可能需要一些时间来完成压缩操作。对于 rollWALWriter 方法,它只表示 rollWALWriter 请求被发送到 region server,可能需要一些时间来完成 rollWALWriter 操作。
对于 region 名称,只接受 byte[] 类型的参数,它可以是完整的 region 名称或编码后的 region 名称。对于服务器名称,只接受 ServerName 类型的参数。 对于表名,只接受 TableName 类型的参数。 对于 list* 操作,如果想要进行正则表达式匹配,只接受 Pattern 类型的参数。
68.5. 扩展客户端
有关非 Java 客户端和自定义协议的信息,请参阅Apache HBase External APIs
69.客户请求过滤器
获取和扫描实例可以选择配置应用于 RegionServer 的过滤器。
过滤器可能会造成混淆,因为有许多不同的类型,最好通过了解过滤器功能组来处理它们。
69.1。结构
结构过滤器包含其他过滤器
69.1.1。 FilterList
FilterList 表示在过滤器之间具有FilterList.Operator.MUST_PASS_ALL或FilterList.Operator.MUST_PASS_ONE关系的过滤器列表。以下示例显示了两个过滤器之间的“或”(在同一属性上检查“我的值”或“我的其他值”)。
FilterList list = new FilterList(FilterList.Operator.MUST_PASS_ONE);
SingleColumnValueFilter filter1 = new SingleColumnValueFilter(
cf,
column,
CompareOperator.EQUAL,
Bytes.toBytes("my value")
);
list.add(filter1);
SingleColumnValueFilter filter2 = new SingleColumnValueFilter(
cf,
column,
CompareOperator.EQUAL,
Bytes.toBytes("my other value")
);
list.add(filter2);
scan.setFilter(list);
69.2。列值
69.2.1。 SingleColumnValueFilter
SingleColumnValueFilter(参见: https://hbase.apache.org/apidocs/org/apache/hadoop/hbase/filter/SingleColumnValueFilter.html )可用于测试等值的列值(CompareOperaor.EQUAL ),不等式(CompareOperaor.NOT_EQUAL)或范围(例如,CompareOperaor.GREATER)。以下是测试列与 String 值“my value”的等效性的示例...
SingleColumnValueFilter filter = new SingleColumnValueFilter(
cf,
column,
CompareOperaor.EQUAL,
Bytes.toBytes("my value")
);
scan.setFilter(filter);
69.2.2。 ColumnValueFilter
作为 SingleColumnValueFilter 的补充,在 HBase-2.0.0 版本中引入,ColumnValueFilter 仅获取匹配的单元格,而 SingleColumnValueFilter 获取匹配的单元格所属的整个行(具有其他列和值)。 ColumnValueFilter 的构造函数的参数与 SingleColumnValueFilter 相同。
ColumnValueFilter filter = new ColumnValueFilter(
cf,
column,
CompareOperaor.EQUAL,
Bytes.toBytes("my value")
);
scan.setFilter(filter);
注意。对于简单查询,例如“等于系列:限定符:值”,我们强烈建议使用以下方法,而不是使用 SingleColumnValueFilter 或 ColumnValueFilter:
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("family"), Bytes.toBytes("qualifier"));
ValueFilter vf = new ValueFilter(CompareOperator.EQUAL,
new BinaryComparator(Bytes.toBytes("value")));
scan.setFilter(vf);
...
此扫描将限制到指定的列'family:qualifier',避免扫描不相关的族和列,具有更好的性能,ValueFilter是用于进行值过滤的条件。
但如果查询比本书更复杂,那么请根据具体情况做出不错的选择。
69.3。列值比较器
Filter 包中有几个 Comparator 类值得特别提及。这些比较器与其他滤波器一起使用,例如 SingleColumnValueFilter 。
69.3.1。 RegexStringComparator
RegexStringComparator 支持用于值比较的正则表达式。
RegexStringComparator comp = new RegexStringComparator("my."); // any value that starts with 'my'
SingleColumnValueFilter filter = new SingleColumnValueFilter(
cf,
column,
CompareOperaor.EQUAL,
comp
);
scan.setFilter(filter);
有关 Java 中支持的支持的 RegEx 模式,请参阅 Oracle JavaDoc。
69.3.2。 SubstringComparator
SubstringComparator 可用于确定某个值是否存在给定的子字符串。比较不区分大小写。
SubstringComparator comp = new SubstringComparator("y val"); // looking for 'my value'
SingleColumnValueFilter filter = new SingleColumnValueFilter(
cf,
column,
CompareOperaor.EQUAL,
comp
);
scan.setFilter(filter);
69.3.3。 BinaryPrefixComparator
69.3.4。 BinaryComparator
参见 BinaryComparator 。
69.4。 KeyValue 元数据
由于 HBase 在内部将数据存储为 KeyValue 对,因此 KeyValue 元数据过滤器会评估行的键的存在(即 ColumnFamily:Column 限定符),而不是上一节的值。
69.4.1。 FamilyFilter
FamilyFilter 可用于过滤 ColumnFamily。在扫描中选择 ColumnFamilies 通常比使用 Filter 执行它更好。
69.4.2。 QualifierFilter
QualifierFilter 可用于根据列(又称限定符)名称进行过滤。
69.4.3。 ColumnPrefixFilter
ColumnPrefixFilter 可用于根据 Column(又称限定符)名称的前导部分进行过滤。
ColumnPrefixFilter 向前搜索与每行中的前缀匹配的第一列以及每个涉及的列族。它可用于在非常宽的行中有效地获取列的子集。
注意:可以在不同的列族中使用相同的列限定符。此过滤器返回所有匹配的列。
示例:查找以“abc”开头的行和族中的所有列
Table t = ...;
byte[] row = ...;
byte[] family = ...;
byte[] prefix = Bytes.toBytes("abc");
Scan scan = new Scan(row, row); // (optional) limit to one row
scan.addFamily(family); // (optional) limit to one family
Filter f = new ColumnPrefixFilter(prefix);
scan.setFilter(f);
scan.setBatch(10); // set this if there could be many columns returned
ResultScanner rs = t.getScanner(scan);
for (Result r = rs.next(); r != null; r = rs.next()) {
for (KeyValue kv : r.raw()) {
// each kv represents a column
}
}
rs.close();
69.4.4。 MultipleColumnPrefixFilter
MultipleColumnPrefixFilter 的行为与 ColumnPrefixFilter 类似,但允许指定多个前缀。
与 ColumnPrefixFilter 一样,MultipleColumnPrefixFilter 有效地向前搜索与最低前缀匹配的第一列,并且还在前缀之间寻找过去的列范围。它可用于从非常宽的行中有效地获得不连续的列集。
示例:查找以“abc”或“xyz”开头的行和族中的所有列
Table t = ...;
byte[] row = ...;
byte[] family = ...;
byte[][] prefixes = new byte[][] {Bytes.toBytes("abc"), Bytes.toBytes("xyz")};
Scan scan = new Scan(row, row); // (optional) limit to one row
scan.addFamily(family); // (optional) limit to one family
Filter f = new MultipleColumnPrefixFilter(prefixes);
scan.setFilter(f);
scan.setBatch(10); // set this if there could be many columns returned
ResultScanner rs = t.getScanner(scan);
for (Result r = rs.next(); r != null; r = rs.next()) {
for (KeyValue kv : r.raw()) {
// each kv represents a column
}
}
rs.close();
69.4.5。 ColumnRangeFilter
ColumnRangeFilter 允许有效的行内扫描。
ColumnRangeFilter 可以提前查找每个相关列族的第一个匹配列。它可用于有效地获得非常宽的行的“切片”。即你连续有一百万列,但你只想查看列 bbbb-bbdd。
Note: The same column qualifier can be used in different column families. This filter returns all matching columns.
示例:在“bbbb”(包括)和“bbdd”(包括)之间查找行和族中的所有列
Table t = ...;
byte[] row = ...;
byte[] family = ...;
byte[] startColumn = Bytes.toBytes("bbbb");
byte[] endColumn = Bytes.toBytes("bbdd");
Scan scan = new Scan(row, row); // (optional) limit to one row
scan.addFamily(family); // (optional) limit to one family
Filter f = new ColumnRangeFilter(startColumn, true, endColumn, true);
scan.setFilter(f);
scan.setBatch(10); // set this if there could be many columns returned
ResultScanner rs = t.getScanner(scan);
for (Result r = rs.next(); r != null; r = rs.next()) {
for (KeyValue kv : r.raw()) {
// each kv represents a column
}
}
rs.close();
注意:在 HBase 0.92 中引入
69.5。 RowKey
69.5.1。的 RowFilter
在扫描行选择时使用 startRow / stopRow 方法通常更好一点,但也可以使用 RowFilter 。
69.6。效用
69.6.1。 FirstKeyOnlyFilter
这主要用于 rowcount 作业。见 FirstKeyOnlyFilter 。
70.师父
HMaster是主服务器的实现。主服务器负责监视集群中的所有 RegionServer 实例,并且是所有元数据更改的接口。在分布式群集中,Master 通常在 NameNode 上运行。 J Mohamed Zahoor 在博客中发表了关于 Master Architecture 的更多细节, HBase HMaster Architecture 。
70.1。启动行为
如果在多主机环境中运行,则所有主机竞争以运行集群。如果活跃的 Master 在 ZooKeeper 中丢失了它的租约(或者 Master 关闭了),那么剩下的 Masters 会争先恐后地接管 Master 角色。
70.2。运行时影响
一个常见的 dist-list 问题涉及当 Master 关闭时 HBase 集群会发生什么。由于 HBase 客户端直接与 RegionServers 通信,因此群集仍然可以在“稳定状态”下运行。此外,根据目录表,hbase:meta作为 HBase 表存在,并且不驻留在主服务器中。但是,Master 控制关键功能,例如 RegionServer 故障转移和完成区域拆分。因此,虽然群集仍然可以在没有 Master 的情况下短时间运行,但 Master 应该尽快重启。
70.3。接口
HMasterInterface公开的方法主要是面向元数据的方法:
-
表(createTable,modifyTable,removeTable,enable,disable)
-
ColumnFamily(addColumn,modifyColumn,removeColumn)
-
区域(移动,分配,取消分配)例如,当调用
Admin方法disableTable时,它由主服务器提供服务。
70.4。流程
Master 运行几个后台线程:
70.4.1。负载平衡器
定期地,当没有转换区域时,负载均衡器将运行并移动区域以平衡群集的负载。请参阅 Balancer 以配置此属性。
有关区域分配的更多信息,请参见 Region-RegionServer Assignment 。
70.4.2。 CatalogJanitor
定期检查并清理hbase:meta表。有关元表的更多信息,请参见 hbase:meta 。
70.5。 MasterProcWAL
HMaster 将管理操作及其运行状态(例如崩溃的服务器,表创建和其他 DDL 的处理)记录到其自己的 WAL 文件中。 WAL 存储在 MasterProcWALs 目录下。 Master WALs 与 RegionServer WALs 不同。保持 Master WAL 允许我们运行一个在 Master 故障中具有弹性的状态机。例如,如果 HMaster 正在创建表遇到问题并且失败,则下一个活动 HMaster 可以占用前一个停止的位置并执行操作。从 hbase-2.0.0 开始,引入了新的 AssignmentManager(AKA AMv2),HMaster 处理区域分配操作,服务器崩溃处理,平衡等,所有这些都通过 AMv2 持久化所有状态并转换为 MasterProcWAL 而不是流入 ZooKeeper,如我们在 hbase-1.x 中做。
如果您想了解有关新 AssignmentManager 的更多信息,请参阅 AMv2 描述 Devs (和程序框架(Pv2): HBASE-12439 )。
70.5.1。 MasterProcWAL 的配置
以下是影响 MasterProcWAL 操作的配置列表。您不必更改默认值。
hbase.procedure.store.wal.periodic.roll.msec
描述
生成新 WAL 的频率
默认
1h (3600000 in msec)
hbase.procedure.store.wal.roll.threshold
Description
WAL 滚动前的大小阈值。每次 WAL 达到此大小或上述时间段,1 小时后,自上次滚动后经过,HMaster 将生成一个新的 WAL。
Default
32MB (33554432 in byte)
hbase.procedure.store.wal.warn.threshold
Description
如果 WAL 的数量超过此阈值,则在滚动时,以下消息应出现在具有 WARN 级别的 HMaster 日志中。
procedure WALs count=xx above the warning threshold 64\. check running procedures to see if something is stuck.
Default
64
hbase.procedure.store.wal.max.retries.before.roll
Description
将插槽(记录)同步到其底层存储(例如 HDFS)时的最大重试次数。每次尝试,以下消息都应出现在 HMaster 日志中。
unable to sync slots, retry=xx
Default
3
hbase.procedure.store.wal.sync.failure.roll.max
Description
在上述 3 次重试之后,日志被滚动并且重试计数被重置为 0,其上开始一组新的重试。此配置控制同步失败时日志滚动的最大尝试次数。也就是说,HMaster 总共无法同步 9 次。一旦超过,HMaster 日志中就会出现以下日志。
Sync slots after log roll failed, abort.
Default
3
71. RegionServer
HRegionServer是 RegionServer 实现。它负责服务和管理地区。在分布式群集中,RegionServer 在 DataNode 上运行。
71.1。接口
HRegionRegionInterface公开的方法包含面向数据和区域维护方法:
-
数据(获取,放置,删除,下一步等)
-
Region(splitRegion,compactRegion 等)例如,当在表上调用
Admin方法majorCompact时,客户端实际上迭代指定表的所有区域并直接请求对每个区域进行主要压缩。
71.2。流程
RegionServer 运行各种后台线程:
71.2.1。 CompactSplitThread
检查拆分并处理轻微压缩。
71.2.2。 MajorCompactionChecker
检查主要的压缩。
71.2.3。 MemStoreFlusher
定期刷新 MemStore 到 StoreFiles 中的内存中写入。
71.2.4。 LogRoller
定期检查 RegionServer 的 WAL。
71.3。协处理器
协处理器的添加量为 0.92。有一个彻底的博客概述 CoProcessors 发布。文档最终会转到此参考指南,但博客是目前最新的信息。
71.4。块缓存
HBase 提供两种不同的 BlockCache 实现来缓存从 HDFS 读取的数据:默认的堆上LruBlockCache和BucketCache,它(通常)是堆外的。本节讨论每个实现的优缺点,如何选择适当的选项以及每个实现的配置选项。
阻止缓存报告:U
有关缓存部署的详细信息,请参阅 RegionServer UI。请参阅配置,大小,当前使用情况,缓存时间,甚至是块计数和类型的详细信息。
71.4.1。缓存选择
LruBlockCache是原始实现,完全在 Java 堆中。 BucketCache是可选的,主要用于将块缓存数据保留在堆外,尽管BucketCache也可以是文件支持的缓存。
启用 BucketCache 时,您将启用双层缓存系统。我们曾经将这些层描述为“L1”和“L2”,但是从 hbase-2.0.0 开始就弃用了这个术语。 “L1”缓存将 LruBlockCache 的实例和“L2”引用到堆外 BucketCache。相反,当启用 BucketCache 时,所有 DATA 块都保存在 BucketCache 层中,元块(INDEX 和 BLOOM 块)在LruBlockCache中堆栈。这两个层次的管理以及决定块如何在它们之间移动的策略由CombinedBlockCache完成。
71.4.2。常规缓存配置
除了缓存实现本身,您还可以设置一些常规配置选项来控制缓存的执行方式。参见 CacheConfig 。设置任何这些选项后,重新启动或滚动重新启动群集以使配置生效。检查日志是否有错误或意外行为。
另见 Blockcache 的预取选项,它讨论了 HBASE-9857 中引入的新选项。
71.4.3。 LruBlockCache 设计
LruBlockCache 是一个 LRU 缓存,包含三个级别的块优先级,以允许扫描阻力和内存中的 ColumnFamilies:
-
单一访问优先级:第一次从 HDFS 加载块时,它通常具有此优先级,并且它将成为驱逐期间要考虑的第一组的一部分。优点是扫描块比使用更多的块更容易被驱逐。
-
多访问优先级:如果再次访问先前优先级组中的块,则会升级到此优先级。因此,它是在驱逐期间考虑的第二组的一部分。
-
内存中访问优先级:如果块的族已配置为“内存中”,则它将成为此优先级的一部分,而不考虑它的访问次数。目录表配置如下。该组是在驱逐期间考虑的最后一组。
要将列族标记为内存,请调用
HColumnDescriptor.setInMemory(true);
如果从 java 创建表,或在 shell 中创建或更改表时设置IN_MEMORY ⇒ true:例如
hbase(main):003:0> create 't', {NAME => 'f', IN_MEMORY => 'true'}
有关更多信息,请参阅 LruBlockCache 源
71.4.4。 LruBlockCache 用法
默认情况下,为所有用户表启用块缓存,这意味着任何读取操作都将加载 LRU 缓存。这可能适用于大量用例,但通常需要进一步调整才能获得更好的性能。一个重要的概念是工作集大小或 WSS,它是:“计算问题答案所需的内存量”。对于网站,这将是在短时间内回答查询所需的数据。
计算 HBase 中用于缓存的内存量的方法是:
number of region servers * heap size * hfile.block.cache.size * 0.99
块缓存的默认值为 0.4,表示可用堆的 40%。最后一个值(99%)是 LRU 高速缓存中的默认可接受加载因子,在此之后启动逐出。它包含在这个等式中的原因是,说可以使用 100%的可用内存是不现实的,因为这会使进程从加载新块的点开始阻塞。这里有些例子:
-
堆大小设置为 1 GB 的一个区域服务器和默认的块高速缓存大小将具有 405 MB 的块高速缓存可用。
-
堆大小设置为 8 GB 的 20 个区域服务器和默认的块高速缓存大小将具有 63.3 的块高速缓存。
-
堆大小设置为 24 GB 且块缓存大小为 0.5 的 100 个区域服务器将具有大约 1.16 TB 的块缓存。
您的数据不是块缓存的唯一驻留者。以下是您可能需要考虑的其他因素:
目录表
hbase:meta表被强制进入块缓存并具有内存中的优先级,这意味着它们更难被驱逐。
hbase:元表可以占用几 MB,具体取决于区域的数量。
HFiles 指数
HFile 是 HBase 用于在 HDFS 中存储数据的文件格式。它包含一个多层索引,允许 HBase 在不必读取整个文件的情况下查找数据。这些索引的大小是块大小(默认为 64KB),键大小和存储数据量的一个因素。对于大数据集,每个区域服务器的数字大约为 1GB 并不罕见,尽管并非所有数据都在缓存中,因为 LRU 将驱逐未使用的索引。
按键
存储的值只是图片的一半,因为每个值都与其键(行键,族限定符和时间戳)一起存储。请参阅尝试最小化行和列大小。
布隆过滤器
就像 HFile 索引一样,这些数据结构(启用时)存储在 LRU 中。
目前,测量 HFile 索引和布隆过滤器大小的推荐方法是查看区域服务器 Web UI 并检查相关指标。对于密钥,可以使用 HFile 命令行工具进行采样,并查找平均密钥大小度量。从 HBase 0.98.3 开始,您可以在 UI 中的特殊“块缓存”部分中查看有关 BlockCache 统计信息和指标的详细信息。
当 WSS 不适合内存时,使用块缓存通常是不好的。例如,当您在所有区域服务器的块缓存中提供 40GB 可用时,您需要处理 1TB 数据。其中一个原因是驱逐产生的流失将不必要地引发更多的垃圾收集。以下是两个用例:
-
完全随机的读取模式:这种情况下,您几乎不会在很短的时间内两次访问同一行,这样命中缓存块的几率就接近于 0.在这样的表上设置块缓存是浪费内存和 CPU 周期,更多,以便它将产生更多垃圾由 JVM 提取。有关监视 GC 的更多信息,请参阅 JVM 垃圾收集日志。
-
映射表:在输入中占用表的典型 MapReduce 作业中,每行只读一次,因此不需要将它们放入块缓存中。 Scan 对象可以选择通过 setCaching 方法将其关闭(将其设置为 false)。如果您需要快速随机读取访问,您仍然可以在此表上保持块缓存。一个例子是计算提供实时流量的表中的行数,缓存该表的每个块会产生大量流失,并且肯定会驱逐当前正在使用的数据。
仅缓存 META 块(fscache 中的 DATA 块)
一个有趣的设置是我们只缓存 META 块,我们在每次访问时读取 DATA 块。如果 DATA 块适合 fscache,当访问在非常大的数据集中完全随机时,这种替代方案可能有意义。要启用此设置,请更改表和每个列族集BLOCKCACHE ⇒ 'false'。您只为此列系列“禁用”BlockCache。您永远不能禁用 META 块的缓存。由于 HBASE-4683 始终缓存索引和布隆块,即使禁用了 BlockCache,我们也会缓存 META 块。
71.4.5。堆外块缓存
如何启用 BucketCache
BucketCache 的常规部署是通过一个管理类来设置两个缓存层:LruBlockCache 实现的堆内缓存和 BucketCache 实现的第二个缓存。默认情况下,管理类是 CombinedBlockCache 。上一个链接描述了 CombinedBlockCache 实现的缓存“策略”。简而言之,它的工作原理是将元块 - INDEX 和 BLOOM 保留在堆上 LruBlockCache 层 - 而 DATA 块保存在 BucketCache 层中。
Pre-hbase-2.0.0 版本
与 pre-hbase-2.0.0 中的 BucketCache 相比,与本机堆上 LruBlockCache 相比,获取总是会更慢。但是,随着时间的推移,延迟往往不那么不稳定,因为使用 BucketCache 时垃圾收集较少,因为它管理的是 BlockCache 分配,而不是 GC。如果 BucketCache 以堆外模式部署,则该内存根本不由 GC 管理。这就是为什么你在 2.0.0 之前使用 BucketCache,所以你的延迟不那么不稳定,以缓解 GC 和堆碎片,因此你可以安全地使用更多的内存。有关运行堆上和堆外测试的比较,请参阅 Nick Dimiduk 的 BlockCache 101 。另请参阅比较 BlockCache Deploys ,它会发现如果您的数据集适合您的 LruBlockCache 部署,请使用它,否则如果您遇到缓存流失(或者您希望缓存存在于 java GC 的变幻莫测之外),请使用 BucketCache 。
在 2.0.0 之前的版本中,可以配置 BucketCache,以便它接收 LruBlockCache 驱逐的victim。所有数据和索引块首先缓存在 L1 中。当从 L1 发生逐出时,块(或victims)将移动到 L2。通过(HColumnDescriptor.setCacheDataInL1(true)或在 shell 中设置cacheDataInL1,创建或修改列族设置CACHE_DATA_IN_L1为真:例如
hbase(main):003:0> create 't', {NAME => 't', CONFIGURATION => {CACHE_DATA_IN_L1 => 'true'}}
hbase-2.0.0 +版本
HBASE-11425 更改了 HBase 读取路径,因此它可以将读取数据保留在堆外,从而避免将缓存数据复制到 Java 堆上。参见 Offheap 读取路径。在 hbase-2.0.0 中,堆外延迟接近堆栈缓存延迟,具有不会激发 GC 的额外好处。
从 HBase 2.0.0 开始,L1 和 L2 的概念已被弃用。当 BucketCache 打开时,DATA 块将始终转到 BucketCache,INDEX / BLOOM 块转到堆 LRUBlockCache。 cacheDataInL1支持已被删除。
BucketCache Block Cache 可以部署 _ 堆外 , 文件 _ 或 mmaped 文件模式。
您可以通过hbase.bucketcache.ioengine设置进行设置。将其设置为offheap将使 BucketCache 在堆外进行分配,并且file:PATH_TO_FILE的 ioengine 设置将指示 BucketCache 使用文件缓存(特别是如果您有一些快速 I / O 连接到盒子,如 SSD) )。从 2.0.0 开始,可以有多个文件支持 BucketCache。当 Cache 大小要求很高时,这非常有用。对于多个后备文件,请将 ioengine 配置为files:PATH_TO_FILE1,PATH_TO_FILE2,PATH_TO_FILE3。 BucketCache 也可以配置为使用 mmapped 文件。为此,将 ioengine 配置为mmap:PATH_TO_FILE。
可以部署分层设置,我们绕过 CombinedBlockCache 策略并让 BucketCache 作为 L1 LruBlockCache 的严格 L2 缓存。对于这样的设置,将hbase.bucketcache.combinedcache.enabled设置为false。在这种模式下,在从 L1 驱逐时,块转到 L2。缓存块时,它首先在 L1 中缓存。当我们去寻找一个缓存的块时,我们首先查看 L1,如果没有找到,则搜索 L2。我们称这种部署格式为 Raw L1 + L2 。注意:此 L1 + L2 模式已从 2.0.0 中删除。使用 BucketCache 时,它将严格地是 DATA 缓存,LruBlockCache 将缓存 INDEX / META 块。
其他 BucketCache 配置包括:指定一个位置以在重新启动时保持缓存,使用多少线程来编写缓存等。有关配置选项和说明,请参阅 CacheConfig.html 类。
要检查它是否已启用,请查找描述缓存设置的日志行;它将详细介绍如何部署 BucketCache。另请参阅 UI。它将详细介绍缓存分层及其配置。
BucketCache 示例配置
此示例提供了 4 GB 堆外 BucketCache 的配置,其中包含 1 GB 的堆栈缓存。
配置在 RegionServer 上执行。
设置hbase.bucketcache.ioengine和hbase.bucketcache.size> 0 启用CombinedBlockCache。让我们假设 RegionServer 已设置为以 5G 堆运行:即HBASE_HEAPSIZE=5g。
-
首先,编辑 RegionServer 的 hbase-env.sh 并将
HBASE_OFFHEAPSIZE设置为大于所需的堆外大小的值,在本例中为 4 GB(表示为 4G)。我们将它设置为 5G。对于我们的堆外缓存,这将是 4G,对于堆外存储器的任何其他用途都是 1G(除了 BlockCache 之外还有其他堆外存储器用户;例如 RegionServer 中的 DFSClient 可以利用堆外存储器)。参见 HBase 中的直接内存使用情况。HBASE_OFFHEAPSIZE=5G -
接下来,将以下配置添加到 RegionServer 的 hbase-site.xml 。
<property> <name>hbase.bucketcache.ioengine</name> <value>offheap</value> </property> <property> <name>hfile.block.cache.size</name> <value>0.2</value> </property> <property> <name>hbase.bucketcache.size</name> <value>4196</value> </property> -
重新启动或滚动重新启动群集,并检查日志中是否存在任何问题。
在上面,我们将 BucketCache 设置为 4G。我们配置堆上 LruBlockCache 有 20%(0.2)的 RegionServer 的堆大小(0.2 * 5G = 1G)。换句话说,您可以像平常一样配置 L1 LruBlockCache(就好像没有 L2 缓存一样)。
HBASE-10641 引入了为 BucketCache 的桶配置多种大小的能力,HBase 0.98 及更高版本。要配置多个存储桶大小,请将新属性hbase.bucketcache.bucket.sizes配置为以逗号分隔的块大小列表,从最小到最大排序,不带空格。目标是根据您的数据访问模式优化存储桶大小。以下示例配置大小为 4096 和 8192 的存储桶。
<property>
<name>hbase.bucketcache.bucket.sizes</name>
<value>4096,8192</value>
</property>
HBase 中的直接内存使用
默认的最大直接内存因 JVM 而异。传统上它是 64M 或与分配的堆大小(-Xmx)或根本没有限制(显然是 JDK7)的某种关系。 HBase 服务器使用直接内存,特别是短路读取(参见利用本地数据),托管 DFSClient 将分配直接内存缓冲区。 DFSClient 使用多少不容易量化;它是打开的 HFiles *
hbase.dfs.client.read.shortcircuit.buffer.size的数量,其中hbase.dfs.client.read.shortcircuit.buffer.size在 HBase 中设置为 128k - 参见 hbase-default.xml 默认配置。如果你进行堆外块缓存,你将使用直接内存。 RPCServer 使用 ByteBuffer 池。从 2.0.0 开始,这些缓冲区是堆外 ByteBuffers。启动 JVM,确保 conf / hbase-env.sh 中的-XX:MaxDirectMemorySize设置考虑了堆外 BlockCache(hbase.bucketcache.size),DFSClient 使用情况,RPC 端 ByteBufferPool 最大值。这必须比关闭堆 BlockCache 大小和最大 ByteBufferPool 大小的总和高一点。为最大直接内存大小分配额外的 1-2 GB 已经在测试中起作用。直接内存是 Java 进程堆的一部分,它与-Xmx 分配的对象堆是分开的。MaxDirectMemorySize分配的值不得超过物理 RAM,并且由于其他内存要求和系统限制,可能会小于总可用 RAM。您可以通过查看 Server Metrics:Memory 选项卡,查看 RegionServer 配置使用的内存量和堆外/直接内存量以及它在任何时候使用了多少内存。 UI。它也可以通过 JMX 获得。特别是服务器当前使用的直接内存可以在
java.nio.type=BufferPool,name=directbean 上找到。在 Java 中使用堆外内存时,Terracotta 有一个良好的写入。它适用于他们的产品 BigMemory,但是很多问题一般都适用于任何脱机的尝试。看看这个。hbase.bucketcache.percentage.in.combinedcache
这是删除了之前的 HBase 1.0 配置,因为它令人困惑。它是一个浮点数,你可以设置为 0.0 到 1.0 之间的某个值。它的默认值是 0.9。如果部署使用 CombinedBlockCache,则 LruBlockCache L1 大小计算为
(1 - hbase.bucketcache.percentage.in.combinedcache) * size-of-bucketcache,BucketCache 大小为hbase.bucketcache.percentage.in.combinedcache * size-of-bucket-cache。其中 bucket-cache-cache 本身的大小是配置的值hbase.bucketcache.size如果它被指定为兆字节 ORhbase.bucketcache.size*-XX:MaxDirectMemorySize,如果hbase.bucketcache.size在 0 和 1.0 之间。在 1.0 中,它应该更直接。使用
hfile.block.cache.size setting(不是最佳名称)将 Onheap LruBlockCache 大小设置为 java 堆的一小部分,并将 BucketCache 设置为绝对兆字节。
71.4.6。压缩的 BlockCache
HBASE-11331 引入了懒惰的 BlockCache 解压缩,更简单地称为压缩的 BlockCache。当启用压缩的 BlockCache 时,数据和编码数据块以其磁盘格式缓存在 BlockCache 中,而不是在缓存之前进行解压缩和解密。
对于托管更多数据而不能容纳缓存的 RegionServer,通过 SNAPPY 压缩启用此功能已显示吞吐量增加 50%,平均延迟提高 30%,同时将垃圾收集增加 80%并增加总体 CPU 负载 2%。有关如何衡量和实现性能的更多详细信息,请参阅 HBASE-11331。对于托管可以轻松适应缓存的数据的 RegionServer,或者如果您的工作负载对额外的 CPU 或垃圾收集负载敏感,您可能会获得较少的好处。
默认情况下禁用压缩的 BlockCache。要启用它,请在所有 RegionServers 上的 hbase-site.xml 中将hbase.block.data.cachecompressed设置为true。
71.5。 RegionServer Offheap 读/写路径
71.5.1。 Offheap 读取路径
在 hbase-2.0.0 中, HBASE-11425 改变了 HBase 读取路径,因此它可以将读取数据保留在堆外,从而避免将缓存数据复制到 Java 堆上。由于产生的垃圾较少而且清除较少,因此可以减少 GC 暂停。堆外读取路径的性能与堆上 LRU 缓存的性能类似/更好。此功能自 HBase 2.0.0 起可用。如果 BucketCache 处于file模式,则与本机堆上 LruBlockCache 相比,获取总是会更慢。有关更多详细信息和测试结果,请参阅下面的博客关闭 Apache HBase 中的读取路径:第 2 部分和生产中的 Offheap 读取路径 - 阿里巴巴故事
对于端到端的非堆积读取路径,首先应该有一个堆外支持的堆外块缓存(BC)。在 hbase-site.xml 中将'hbase.bucketcache.ioengine'配置为堆外。同时使用hbase.bucketcache.size配置指定 BC 的总容量。请记住在 hbase-env.sh 中调整'HBASE_OFFHEAPSIZE'的值。这就是我们如何为 RegionServer java 进程指定最大可能的堆外内存分配。这应该比堆外 BC 大小更大。请记住,hbase.bucketcache.ioengine没有默认值,这意味着 BC 默认关闭(参见 HBase 中的直接内存使用情况)。
接下来要调整的是 RPC 服务器端的 ByteBuffer 池。此池中的缓冲区将用于累积单元字节并创建结果单元块以发送回客户端。 hbase.ipc.server.reservoir.enabled可用于打开或关闭此池。默认情况下,此池为 ON 且可用。 HBase 将创建关闭堆 ByteBuffers 并将它们池化。如果您希望在读取路径中进行端到端的堆叠,请确保不要将其关闭。如果关闭此池,服务器将在堆上创建临时缓冲区以累积单元字节并生成结果单元块。这可能会影响高度读取加载的服务器上的 GC。用户可以根据池中缓冲区的数量以及每个 ByteBuffer 的大小来调整此池。使用 config hbase.ipc.server.reservoir.initial.buffer.size调整每个缓冲区大小。默认值为 64 KB。
当读取模式是随机行读取负载并且每个行的大小与此 64 KB 相比较小时,请尝试减少此行。当结果大小大于一个 ByteBuffer 大小时,服务器将尝试获取多个缓冲区并从中生成结果单元块。当池缓冲区用完时,服务器将最终创建临时堆栈缓冲区。
可以使用 config'hbase.ipc.server.reservoir.initial.max'调整池中 ByteBuffers 的最大数量。其值默认为 64 *区域服务器处理程序配置(请参阅 config'hbase.regionserver.handler.count')。数学是这样的,默认情况下我们认为每个读取结果的结果单元块大小为 2 MB,每个处理程序将处理读取。对于 2 MB 大小,我们需要 32 个大小为 64 KB 的缓冲区(请参阅池中的默认缓冲区大小)。所以每个处理程序 32 ByteBuffers(BB)。我们将此大小的两倍分配为最大 BBs 计数,以便一个处理程序可以创建响应并将其交给 RPC Responder 线程,然后处理创建新响应单元块的新请求(使用池化缓冲区)。即使响应者无法立即发回第一个 TCP 回复,我们的计数应该允许我们在池中仍然有足够的缓冲区而不必在堆上创建临时缓冲区。同样,对于较小尺寸的随机行读取,请调整此最大计数。有懒惰创建的缓冲区,计数是要合并的最大计数。
如果在堆外端到端读取路径之后仍然看到 GC 问题,请在相应的缓冲池中查找问题。使用 INFO 级别检查以下 RegionServer 日志:
Pool already reached its max capacity : XXX and no free buffers now. Consider increasing the value for 'hbase.ipc.server.reservoir.initial.max' ?
hbase-env.sh 中 _HBASE OFFHEAPSIZE 的设置也应考虑 RPC 端的堆缓冲池。我们需要将 RegionServer 的最大堆大小配置为略高于此最大池大小和关闭堆高速缓存大小的总和。 TCP 层还需要为 TCP 通信创建直接字节缓冲区。此外,DFS 客户端将需要一些堆外工作来完成其工作,尤其是在配置了短路读取的情况下。为最大直接内存大小分配额外的 1 - 2 GB 已经在测试中起作用。
如果您正在使用协处理器并在读取结果中引用单元格,请不要将这些单元格的引用存储在 CP 挂钩方法的范围之外。有时,CP 需要存储有关单元格的信息(如其行键),以便在下一个 CP 钩子调用等中进行考虑。对于这种情况,请根据用例克隆整个 Cell 的必需字段。 [参见 CellUtil#cloneXXX(Cell)API]
71.5.2。 Offheap 写路径
去做
71.6。 RegionServer 拆分实现
由于写请求由区域服务器处理,它们会累积在称为 memstore 的内存存储系统中。 memstore 填充后,其内容将作为附加存储文件写入磁盘。此事件称为 memstore flush 。随着存储文件的累积,RegionServer 将将压缩为更少,更大的文件。每次刷新或压缩完成后,存储在该区域中的数据量已更改。 RegionServer 查询区域拆分策略,以确定该区域是否已经变得太大,或者是否应该针对另一个特定于策略的原因进行拆分。如果策略建议,则会将区域拆分请求排入队列。
从逻辑上讲,分割区域的过程很简单。我们在区域的键空间中找到一个合适的点,我们应该将区域分成两半,然后将区域的数据分成两个新的区域。然而,该过程的细节并不简单。当发生拆分时,新创建的 _ 子区域 _ 不会立即将所有数据重写为新文件。相反,他们创建类似于符号链接文件的小文件,名为参考文件,它根据分割点指向父商店文件的顶部或底部。参考文件的使用方式与常规数据文件类似,但只考虑了一半的记录。如果不再有对父区域的不可变数据文件的引用,则只能拆分该区域。这些参考文件通过压缩逐渐清理,以便该区域将停止引用其父文件,并可以进一步拆分。
虽然拆分区域是 RegionServer 做出的本地决策,但拆分过程本身必须与许多参与者协调。 RegionServer 在拆分之前和之后通知 Master,更新.META.表,以便客户端可以发现新的子区域,并重新排列 HDFS 中的目录结构和数据文件。拆分是一个多任务流程。要在发生错误时启用回滚,RegionServer 会保留有关执行状态的内存日记。 RegionServer 执行拆分所采取的步骤在 RegionServer 拆分流程中说明。每个步骤都标有其步骤编号。 RegionServers 或 Master 的操作显示为红色,而客户端的操作显示为绿色。
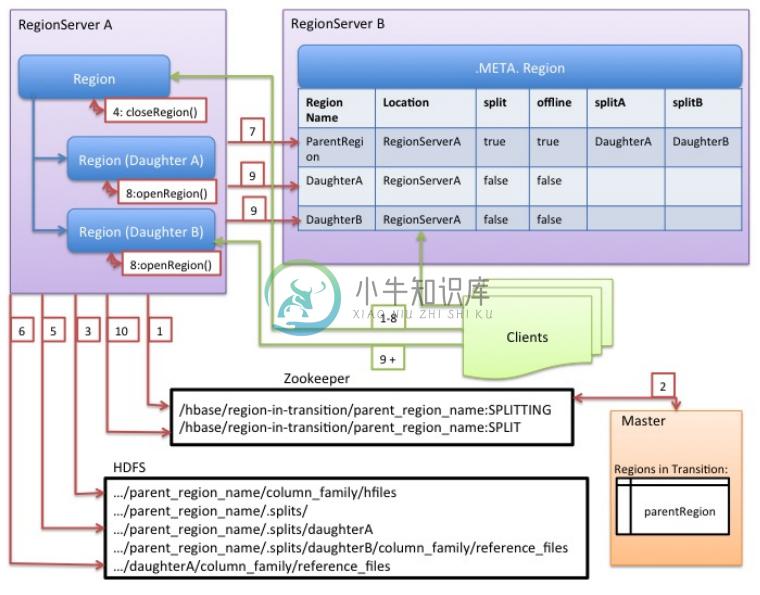 图 1. RegionServer 拆分流程
图 1. RegionServer 拆分流程
-
RegionServer 在本地决定拆分区域,并准备拆分。 分拆交易已经开始。 作为第一步,RegionServer 获取表上的共享读锁,以防止在拆分过程中修改模式。然后它在
/hbase/region-in-transition/region-name下的 zookeeper 中创建一个 znode,并将 znode 的状态设置为SPLITTING。 -
Master 了解这个 znode,因为它有一个父
region-in-transitionznode 的观察者。 -
RegionServer 在 HDFS 的父级
region目录下创建一个名为.splits的子目录。 -
RegionServer 关闭父区域,并在其本地数据结构中将该区域标记为脱机。 分裂区域现在离线。 此时,来到父区域的客户端请求将抛出
NotServingRegionException。客户端将重试一些退避。关闭区域被刷新。 -
RegionServer 在
.splits目录下为子区域 A 和 B 创建区域目录,并创建必要的数据结构。然后它会分割存储文件,因为它会在父区域中为每个存储文件创建两个参考文件。这些参考文件将指向父区域的文件。 -
RegionServer 在 HDFS 中创建实际的区域目录,并移动每个子项的参考文件。
-
RegionServer 将
Put请求发送到.META.表,在.META.表中将父级设置为脱机,并添加有关子区域的信息。此时,.META.中的女儿不会有个别条目。客户将看到父区域在扫描.META.时被拆分,但在.META.出现之前不会知道这些女儿。另外,如果这Put到.META。成功后,父母将被有效分割。如果 RegionServer 在此 RPC 成功之前失败,则 Master 和下一个打开该区域的 Region Server 将清除有关区域拆分的脏状态。但是,.META.更新后,区域拆分将由 Master 进行前滚。 -
RegionServer 并行打开女儿 A 和 B.
-
RegionServer 将女儿 A 和 B 添加到
.META.,以及它托管区域的信息。 分裂地区(带有父母参考的孩子)现在在线。 在此之后,客户可以发现新区域并向他们发出请求。客户端在本地缓存.META.条目,但是当它们向 RegionServer 或.META.发出请求时,它们的缓存将无效,并且它们将从.META.中了解新区域。 -
RegionServer 将 ZooKeeper 中的 znode
/hbase/region-in-transition/region-name更新为状态SPLIT,以便主人可以了解它。如有必要,平衡器可以自由地将子区域重新分配给其他区域服务器。 分裂交易现已完成。 -
拆分后,
.META.和 HDFS 仍将包含对父区域的引用。当子区域中的压缩重写数据文件时,将删除这些引用。主服务器中的垃圾收集任务会定期检查子区域是否仍然引用父区域的文件。如果不是,则将删除父区域。
71.7。写前方日志(WAL)
71.7.1。目的
_ 预写日志(WAL)_ 将对 HBase 中数据的所有更改记录到基于文件的存储。在正常操作下,不需要 WAL,因为数据更改从 MemStore 移动到 StoreFiles。但是,如果 RegionApp 在刷新 MemStore 之前崩溃或变得不可用,则 WAL 会确保可以重播对数据的更改。如果写入 WAL 失败,则修改数据的整个操作将失败。
HBase 使用 WAL 接口的实现。通常,每个 RegionServer 只有一个 WAL 实例。一个例外是携带 hbase:meta 的 RegionServer; meta 表获得了自己的专用 WAL。 RegionServer 记录其 WAL 的删除和删除,然后为受影响的商店记录这些突变 MemStore 。
HLo
在 2.0 之前,HBase 中 WALs 的接口被命名为
HLog。在 0.94 中,HLog 是 WAL 实现的名称。您可能会在针对这些旧版本的文档中找到对 HLog 的引用。
WAL 驻留在 / hbase / WALs / 目录中的 HDFS 中,每个区域都有子目录。
有关预写日志概念的更多一般信息,请参阅 Wikipedia Write-Ahead Log 文章。
71.7.2。 WAL 提供商
在 HBase 中,有许多 WAL 元素(或“提供者”)。每个都有一个简短的名称标签(不幸的是,它并不总是描述性的)。您在 hbase-site.xml 中设置提供程序,将 WAL 提供者短名称作为 hbase.wal.provider 属性的值设置(设置 hbase 的提供程序: meta 使用 _hbase.wal.meta _ 提供程序 _ 属性,否则它使用由 hbase.wal.provider 配置的相同提供程序。
-
asyncfs :默认。自 hbase-2.0.0 以来的新版本(HBASE-15536,HBASE-14790)。这个 AsyncFSWAL 提供程序,它在 RegionServer 日志中标识自身,是基于一个新的非阻塞 dfsclient 实现。它目前驻留在 hbase 代码库中,但目的是将其移回 HDFS 本身。 WALs 编辑被并发(“扇出”)样式写入每个 DataNode 上的每个 WAL 块复制品,而不是像默认客户端那样在链式管道中。延迟应该更好。有关实施的更多详细信息,请参阅第 14 页第 14 页的小米的 Apache HBase 改进和实践。
-
filesystem :这是 hbase-1.x 版本中的默认值。它建立在阻塞 DFSClient 的基础上,并在经典 DFSCLient 管道模式下写入副本。在日志中,它标识为 FSHLog 或 FSHLogProvider 。
-
multiwal :此提供程序由 asyncfs 或 _ 文件系统 _ 的多个实例组成。有关 multiwal 的更多信息,请参阅下一节。
在 RegionServer 日志中查找如下所示的行,以查看适当的提供程序(下面显示了默认的 AsyncFSWALProvider):
2018-04-02 13:22:37,983 INFO [regionserver/ve0528:16020] wal.WALFactory: Instantiating WALProvider of type class org.apache.hadoop.hbase.wal.AsyncFSWALProvider
由于 AsyncFSWAL 侵入了 DFSClient 实现的内部,因此即使对于简单的补丁版本,也可以通过升级 hadoop 依赖关系来轻松破解它。因此,如果您没有明确指定 wal 提供程序,我们将首先尝试使用 asyncfs ,如果失败,我们将回退使用 _ 文件系统 _。请注意,这可能并不总是有效,因此如果由于启动 AsyncFSWAL 的问题仍然无法启动 HBase,请在配置文件中明确指定 _ 文件系统 _。
已经在 hadoop-3.x 中添加了 EC 支持,并且它与 WAL 不兼容,因为 EC 输出流不支持 hflush / hsync。为了在 EC 目录中创建非 EC 文件,我们需要为 FileSystem 使用新的基于构建器的创建 API,但它仅在 hadoop-2.9 +中引入,对于 HBase 我们仍然需要支持 hadoop-2.7.x。因此,在我们找到处理它的方法之前,请不要为 WAL 目录启用 EC。
71.7.3。 MultiWAL
对于每个 RegionServer 一个 WAL,RegionServer 必须串行写入 WAL,因为 HDFS 文件必须是顺序的。这导致 WAL 成为性能瓶颈。
HBase 1.0 在 HBASE-5699 中引入了对 MultiWal 的支持。 MultiWAL 允许 RegionServer 通过在底层 HDFS 实例中使用多个管道来并行写入多个 WAL 流,这会增加写入期间的总吞吐量。这种并行化是通过按区域划分传入编辑来完成的。因此,当前的实现无助于增加单个区域的吞吐量。
使用原始 WAL 实现的 RegionServers 和使用 MultiWAL 实现的 RegionServers 都可以处理任一组 WAL 的恢复,因此通过滚动重启可以实现零停机配置更新。
配置 MultiWAL
要为 RegionServer 配置 MultiWAL,请通过粘贴以下 XML 将属性hbase.wal.provider的值设置为multiwal:
<property>
<name>hbase.wal.provider</name>
<value>multiwal</value>
</property>
重新启动 RegionServer 以使更改生效。
要为 RegionServer 禁用 MultiWAL,请取消设置该属性并重新启动 RegionServer。
71.7.4。 WAL 法拉盛
TODO(描述)。
71.7.5。 WAL 分裂
RegionServer 服务于许多地区。区域服务器中的所有区域共享相同的活动 WAL 文件。 WAL 文件中的每个编辑都包含有关它所属的区域的信息。打开某个区域时,需要重播属于该区域的 WAL 文件中的编辑。因此,WAL 文件中的编辑必须按区域分组,以便可以重放特定的集合以重新生成特定区域中的数据。按区域对 WAL 编辑进行分组的过程称为 _ 日志分割 _。如果区域服务器出现故障,这是恢复数据的关键过程。
日志拆分由集群启动期间的 HMaster 完成,或者由区域服务器关闭时由 ServerShutdownHandler 完成。为了保证一致性,受影响的区域在数据恢复之前不可用。在给定区域再次可用之前,需要恢复和重放所有 WAL 编辑。因此,在进程完成之前,受日志拆分影响的区域将不可用。
过程:Log Step,Step by Step
-
重命名 / hbase / WALs / <host>,<port>, <startcode></startcode> </port></host> 目录。
重命名目录很重要,因为即使 HMaster 认为它已关闭,RegionServer 仍可能正在启动并接受请求。如果 RegionServer 没有立即响应并且没有对其 ZooKeeper 会话进行心跳,则 HMaster 可能会将其解释为 RegionServer 故障。重命名 logs 目录可确保仍然无法写入仍由活动但繁忙的 RegionServer 使用的现有有效 WAL 文件。
新目录根据以下模式命名:
/hbase/WALs/<host>,<port>,<startcode>-splitting此类重命名目录的示例可能如下所示:
/hbase/WALs/srv.example.com,60020,1254173957298-splitting -
每个日志文件被拆分,一次一个。
日志分割器一次读取一个编辑条目的日志文件,并将每个编辑条目放入与编辑区域对应的缓冲区中。同时,拆分器启动了几个写入程序线程。 Writer 线程获取相应的缓冲区并将缓冲区中的编辑条目写入临时恢复的编辑文件。临时编辑文件使用以下命名模式存储到磁盘:
/hbase/<table_name>/<region_id>/recovered.edits/.temp此文件用于存储此区域的 WAL 日志中的所有编辑。日志分割完成后, .temp 文件将重命名为写入该文件的第一个日志的序列 ID。
要确定是否已编写所有编辑,将序列 ID 与写入 HFile 的最后一次编辑的序列进行比较。如果最后一次编辑的序列大于或等于文件名中包含的序列 ID,则很明显编辑文件中的所有写入都已完成。
-
日志拆分完成后,每个受影响的区域都将分配给 RegionServer。
打开该区域时,将检查 restored.edits 文件夹中是否有恢复的编辑文件。如果存在任何此类文件,则通过阅读编辑并将其保存到 MemStore 来重放它们。重放所有编辑文件后,MemStore 的内容将写入磁盘(HFile)并删除编辑文件。
日志拆分过程中的错误处理
如果将hbase.hlog.split.skip.errors选项设置为true,则会将错误视为:
-
将记录拆分期间遇到的任何错误。
-
有问题的 WAL 日志将被移动到 hbase
rootdir下的 .corrupt 目录中, -
WALL 的处理将继续进行
如果hbase.hlog.split.skip.errors选项设置为false(默认值),则会传播该异常并将拆分记录为失败。请参阅 HBASE-2958 当 hbase.hlog.split.skip.errors 设置为 false 时,我们无法进行拆分,但这就是。如果设置了这个标志,我们需要做的不仅仅是失败拆分。
拆分崩溃的 RegionServer 的 WAL 时如何处理 EOFExceptions
如果在分割日志时发生 EOFException,即使hbase.hlog.split.skip.errors设置为false,分割仍会继续。在读取要拆分的文件集中的最后一个日志时可能会出现 EOFException,因为 RegionServer 可能正在崩溃时写入记录。有关背景信息,请参阅 HBASE-2643 图如何处理 eof 拆分日志
日志拆分期间的性能改进
WAL 日志拆分和恢复可能是资源密集型的,需要很长时间,具体取决于崩溃中涉及的 RegionServers 的数量和区域的大小。 启用或禁用分布式日志拆分是为了提高日志拆分期间的性能而开发的。
启用或禁用分布式日志拆分
默认情况下启用分布式日志处理,因为 HBase 为 0.92。该设置由hbase.master.distributed.log.splitting属性控制,可以设置为true或false,但默认为true。
分布式日志拆分,一步一步
配置分布式日志分割后,HMaster 控制该过程。 HMaster 在日志分割过程中注册每个 RegionServer,分割日志的实际工作由 RegionServers 完成。如分布式日志分割,逐步中所述的日志分割的一般过程仍然适用于此处。
-
如果启用了分布式日志处理,则 HMaster 会在启动集群时创建 _ 拆分日志管理器 _ 实例。
-
拆分日志管理器管理需要扫描和拆分的所有日志文件。
-
拆分日志管理器将所有日志放入 ZooKeeper splitWAL 节点( / hbase / splitWAL )作为任务。
-
您可以通过发出以下
zkCli命令来查看 splitWAL 的内容。显示示例输出。ls /hbase/splitWAL [hdfs%3A%2F%2Fhost2.sample.com%3A56020%2Fhbase%2FWALs%2Fhost8.sample.com%2C57020%2C1340474893275-splitting%2Fhost8.sample.com%253A57020.1340474893900, hdfs%3A%2F%2Fhost2.sample.com%3A56020%2Fhbase%2FWALs%2Fhost3.sample.com%2C57020%2C1340474893299-splitting%2Fhost3.sample.com%253A57020.1340474893931, hdfs%3A%2F%2Fhost2.sample.com%3A56020%2Fhbase%2FWALs%2Fhost4.sample.com%2C57020%2C1340474893287-splitting%2Fhost4.sample.com%253A57020.1340474893946]输出包含一些非 ASCII 字符。解码后,它看起来更简单:
[hdfs://host2.sample.com:56020/hbase/WALs /host8.sample.com,57020,1340474893275-splitting /host8.sample.com%3A57020.1340474893900, hdfs://host2.sample.com:56020/hbase/WALs /host3.sample.com,57020,1340474893299-splitting /host3.sample.com%3A57020.1340474893931, hdfs://host2.sample.com:56020/hbase/WALs /host4.sample.com,57020,1340474893287-splitting /host4.sample.com%3A57020.1340474893946]该列表表示要扫描和拆分的 WAL 文件名,这是日志拆分任务的列表。
-
-
拆分日志管理器监视日志拆分任务和工作人员。
拆分日志管理器负责以下正在进行的任务:
-
一旦拆分日志管理器将所有任务发布到 splitWAL znode,它就会监视这些任务节点并等待它们被处理。
-
检查是否有任何死亡分裂日志工作者排队。如果它找到无响应的工作人员声称的任务,它将重新提交这些任务。如果重新提交由于某些 ZooKeeper 异常而失败,则死亡工作者将再次排队等待重试。
-
检查是否有任何未分配的任务。如果找到任何,它将创建一个短暂的重新扫描节点,以便通知每个拆分日志工作者通过
nodeChildrenChangedZooKeeper 事件重新扫描未分配的任务。 -
检查已分配但已过期的任务。如果找到任何一个,它们将再次移回
TASK_UNASSIGNED状态,以便可以重试它们。这些任务可能会分配给慢速工作人员,或者可能已经完成。这不是问题,因为日志拆分任务具有幂等性。换句话说,可以多次处理相同的日志分割任务而不会引起任何问题。 -
拆分日志管理器不断监视 HBase 拆分日志 znodes。如果更改了任何拆分日志任务节点数据,则拆分日志管理器将检索节点数据。节点数据包含任务的当前状态。您可以使用
zkCliget命令检索任务的当前状态。在下面的示例输出中,输出的第一行显示该任务当前未分配。get /hbase/splitWAL/hdfs%3A%2F%2Fhost2.sample.com%3A56020%2Fhbase%2FWALs%2Fhost6.sample.com%2C57020%2C1340474893287-splitting%2Fhost6.sample.com%253A57020.1340474893945 unassigned host2.sample.com:57000 cZxid = 0×7115 ctime = Sat Jun 23 11:13:40 PDT 2012 ...根据更改数据的任务的状态,拆分日志管理器执行以下操作之一:
-
如果未分配,则重新提交任务
-
如果已分配任务,请心跳任务
-
如果任务被重新签名则重新提交或失败(请参阅任务失败的原因)
-
如果任务完成但有错误,请重新提交或失败(请参阅任务失败的原因)
-
如果由于错误而无法完成任务,请重新提交或失败(请参阅任务失败的原因)
-
如果任务成功完成或失败,请删除该任务
> 任务失败的原因 > > * 该任务已被删除。 >
>
> * 节点不再存在。 >
>
> * 日志状态管理器无法将任务状态移动到TASK_UNASSIGNED。 >
>
> * 重新提交的次数超过重新提交阈值。
-
-
每个 RegionServer 的拆分日志工作程序都执行日志分割任务。
每个 RegionServer 都运行一个名为 _ 拆分日志工作程序 _ 的守护程序线程,该程序负责拆分日志。守护程序线程在 RegionServer 启动时启动,并注册自己以监视 HBase znode。如果任何 splitWAL znode 子代更改,它会通知睡眠工作线程唤醒并获取更多任务。如果更改了工作人员当前任务的节点数据,则工作人员会检查该任务是否已由另一个工作人员执行。如果是这样,工作线程将停止当前任务的工作。
工作人员不断监视 splitWAL znode。当出现新任务时,拆分日志工作程序将检索任务路径并检查每个任务路径,直到找到无人认领的任务,并尝试声明该任务。如果声明成功,它会尝试执行任务并根据拆分结果更新任务的
state属性。此时,拆分日志工作程序将扫描另一个无人认领的任务。拆分日志工作者如何处理任务
-
它查询任务状态,仅在任务处于
TASK_UNASSIGNED状态时才执行操作。 -
如果任务处于
TASK_UNASSIGNED状态,则工作程序会尝试将状态设置为TASK_OWNED。如果它未能设置状态,另一个工人将尝试抓住它。如果任务仍未分配,拆分日志管理器还将要求所有工作人员稍后重新扫描。 -
如果工作者成功获得任务的所有权,它会再次尝试获取任务状态,以确保它真正异步获取它。在此期间,它启动一个拆分任务执行器来完成实际工作:
-
获取 HBase 根文件夹,在根目录下创建临时文件夹,并将日志文件拆分为临时文件夹。
-
如果拆分成功,则任务执行程序将任务设置为状态
TASK_DONE。 -
如果 worker 捕获到意外的 IOException,则该任务将设置为 state
TASK_ERR。 -
如果工作人员正在关闭,请将任务设置为
TASK_RESIGNED状态。 -
如果任务由另一个工作人员执行,则只需记录它。
-
-
-
拆分日志管理器监视未完成的任务。
当所有任务成功完成时,拆分日志管理器将返回。如果所有任务都在某些失败的情况下完成,则拆分日志管理器会抛出异常,以便可以重试日志拆分。由于异步实现,在极少数情况下,拆分日志管理器会丢失一些已完成的任务。因此,它会定期检查其任务图或 ZooKeeper 中剩余的未完成任务。如果没有找到,它会抛出异常,以便可以立即重试日志拆分,而不是挂在那里等待不会发生的事情。
71.7.6。 WAL 压缩
可以使用 LRU Dictionary 压缩来压缩 WAL 的内容。这可用于加速 WAL 复制到不同的数据节点。字典最多可以存储 2 个 <sup>15</sup> 元素;在超过此数量后开始驱逐。
要启用 WAL 压缩,请将hbase.regionserver.wal.enablecompression属性设置为true。此属性的默认值为false。默认情况下,启用 WAL 压缩时会打开 WAL 标记压缩。您可以通过将hbase.regionserver.wal.tags.enablecompression属性设置为“false”来关闭 WAL 标记压缩。
WAL 压缩的一个可能的缺点是,如果在写入中间终止,则我们会丢失 WAL 中最后一个块的更多数据。如果最后一个块中的条目添加了新的字典条目但由于突然终止而导致修改的字典仍然存在,则读取该最后一个块可能无法解析最后写入的条目。
71.7.7。耐久力
可以在每个突变或表格上设置 _ 耐久性 _。选项包括:
-
_SKIP WAL :不要将变形写入 WAL(参见下一节,禁用 WAL )。
-
_ASYNC WAL :异步写入 WAL;不要让客户等待他们写入文件系统的同步,而是立即返回。编辑变得可见。同时,在后台,Mutation 将在稍后的某个时间刷新到 WAL。此选项目前可能会丢失数据。见 HBASE-16689。
-
_SYNC WAL :默认。在我们将成功返回给客户端之前,每个编辑都会同步到 HDFS。
-
_FSYNC WAL :在我们将成功返回给客户端之前,每个编辑都与 HDFS 和文件系统进行 fsync。
不要将 Mutation 或 Table 上的 _ASYNC WAL 选项与 AsyncFSWAL 编写器混淆;不幸的是,它们是不同的选择
71.7.8。禁用 WAL
可以禁用 WAL,以在某些特定情况下提高性能。但是,禁用 WAL 会使您的数据面临风险。推荐这种情况的唯一情况是在批量加载期间。这是因为,如果出现问题,可以重新运行批量加载而不会有数据丢失的风险。
通过调用 HBase 客户端字段Mutation.writeToWAL(false)禁用 WAL。使用Mutation.setDurability(Durability.SKIP_WAL)和 Mutation.getDurability()方法设置并获取字段的值。没有办法只为特定的表禁用 WAL。
如果禁用 WAL 而不是批量加载,则数据存在风险。
72.地区
区域是表的可用性和分布的基本元素,并且由每列存储族组成。对象的层次结构如下:
Table (HBase table)
Region (Regions for the table)
Store (Store per ColumnFamily for each Region for the table)
MemStore (MemStore for each Store for each Region for the table)
StoreFile (StoreFiles for each Store for each Region for the table)
Block (Blocks within a StoreFile within a Store for each Region for the table)
有关写入 HDFS 时 HBase 文件的描述,请参阅浏览 HBFS 对象的 HDFS 。
72.1。区域数量的考虑因素
通常,HBase 被设计为每个服务器运行一小部分(20-200)个相对较大(5-20Gb)的区域。对此的考虑如下:
72.1.1。我为什么要保持我的地区数量低?
通常,您希望保留您的区域在 HBase 上的数量较少,原因有很多。通常每个 RegionServer 大约 100 个区域产生了最好的结果。以下是保持区域数量低的一些原因:
-
MSLAB(MemStore 本地分配缓冲区)每个 MemStore 需要 2MB(每个区域每个系列 2MB)。每个拥有 2 个系列的 1000 个区域使用了 3.9GB 的堆,并且它甚至还没有存储数据。注意:2MB 值是可配置的。
-
如果以相同的速率填充所有区域,则全局内存使用会使得当您有太多区域而这会产生压缩时会强制进行微小的刷新。几十次重写相同的数据是你想要的最后一件事。一个例子是平均填充 1000 个区域(有一个系列),让我们考虑全局 MemStore 使用 5GB 的下限(区域服务器将有一个大堆)。一旦达到 5GB,它将强制刷新最大区域,此时它们几乎都应该有大约 5MB 的数据,因此它将刷新该数量。稍后插入 5MB,它将刷新另一个区域,现在将有超过 5MB 的数据,依此类推。这是目前区域数量的主要限制因素;参见每个 RS 的区域数 - 上限详细公式。
-
主人对大量地区过敏,并且需要花费大量时间分配它们并分批移动它们。原因是它对 ZK 的使用很重,而且目前它并不是非常同步(真的可以改进 - 并且已经在 0.96 HBase 中得到了改进)。
-
在旧版本的 HBase(pre-HFile v2,0.90 和之前版本)中,少数 RS 上的大量区域可能导致存储文件索引上升,增加堆使用量并可能在 RS 上产生内存压力或 OOME
另一个问题是 MapReduce 作业的区域数量的影响;每个 HBase 区域通常有一个映射器。因此,每个 RS 仅托管 5 个区域可能不足以为 MapReduce 作业获取足够数量的任务,而 1000 个区域将生成太多任务。
有关配置指南,请参阅确定区域计数和大小。
72.2。 Region-RegionServer 分配
本节介绍如何将区域分配给 RegionServers。
72.2.1。启动
当 HBase 启动时,区域分配如下(短版本):
-
Master 在启动时调用
AssignmentManager。 -
AssignmentManager查看hbase:meta中的现有区域分配。 -
如果区域分配仍然有效(即,如果 RegionServer 仍在线),则保留分配。
-
如果赋值无效,则调用
LoadBalancerFactory来分配区域。负载均衡器(HBase 1.0 中默认为StochasticLoadBalancer)将区域分配给 RegionServer。 -
在 RegionServer 打开区域时,使用 RegionServer 分配(如果需要)和 RegionServer 启动代码(RegionServer 进程的开始时间)更新
hbase:meta。
72.2.2。故障转移
RegionServer 失败时:
-
由于 RegionServer 已关闭,这些区域立即变为不可用。
-
Master 将检测到 RegionServer 失败。
-
区域分配将被视为无效,并将像启动顺序一样重新分配。
-
机上查询会重新尝试,而不会丢失。
-
操作在以下时间内切换到新的 RegionServer:
ZooKeeper session timeout + split time + assignment/replay time
72.2.3。区域负载平衡
可以通过 LoadBalancer 周期性地移动区域。
72.2.4。地区国家转型
HBase 维护每个区域的状态,并在hbase:meta中保持状态。 hbase:meta区域本身的状态在 ZooKeeper 中持久存在。您可以在 Master Web UI 中查看转换中的区域的状态。以下是可能的区域状态列表。
可能的地区国家
-
OFFLINE:该区域处于脱机状态且未打开 -
OPENING:该地区正处于开放状态 -
OPEN:区域已打开且 RegionServer 已通知主服务器 -
FAILED_OPEN:RegionServer 无法打开该区域 -
CLOSING:该地区正处于关闭状态 -
CLOSED:RegionServer 已关闭该区域并通知主站 -
FAILED_CLOSE:RegionServer 无法关闭该区域 -
SPLITTING:RegionServer 通知主站区域正在拆分 -
SPLIT:RegionServer 通知主站区域已完成拆分 -
SPLITTING_NEW:正在通过正在进行的拆分创建此区域 -
MERGING:RegionServer 通知主服务器该区域正在与另一个区域合并 -
MERGED:RegionServer 通知主服务器该区域已合并 -
MERGING_NEW:该区域由两个区域的合并创建
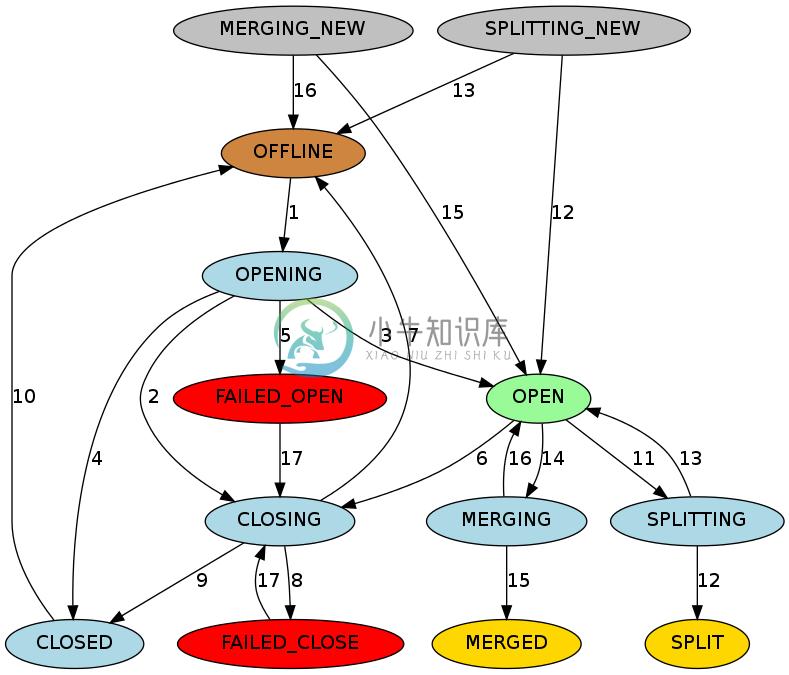 图 2. Region State TransitionsGraph Legend
图 2. Region State TransitionsGraph Legend
-
布朗:离线状态,一种特殊状态,可以是瞬态的(在打开之前关闭之后),终端(禁用表的区域)或初始(新创建的表的区域)
-
Palegreen:在线状态,区域可以提供请求
-
Lightblue:瞬态
-
红色:失败状态需要 OPS 注意
-
黄金:区域的终端状态分裂/合并
-
灰色:通过拆分/合并创建的区域的初始状态
过渡状态描述
-
主设备将区域从
OFFLINE移动到OPENING状态,并尝试将区域分配给 RegionServer。 RegionServer 可能已收到或未收到开放区域请求。主服务器重试将开放区域请求发送到 RegionServer,直到 RPC 通过或主服务器用完为止。 RegionServer 收到开放区域请求后,RegionServer 开始打开该区域。 -
如果主服务器没有重试,则主服务器会阻止 RegionServer 通过将区域移动到
CLOSING状态并尝试关闭它来打开该区域,即使 RegionServer 开始打开该区域也是如此。 -
在 RegionServer 打开区域后,它会继续尝试通知主服务器,直到主服务器将区域移动到
OPEN状态并通知 RegionServer。该地区现已开放。 -
如果 RegionServer 无法打开该区域,则会通知主服务器。主服务器将区域移动到
CLOSED状态并尝试在不同的 RegionServer 上打开该区域。 -
如果主服务器无法在某个区域中的任何区域上打开该区域,则会将该区域移动到
FAILED_OPEN状态,并且在操作员从 HBase shell 进行干预或服务器已停止之前不会采取进一步操作。 -
主设备将区域从
OPEN移动到CLOSING状态。持有该区域的 RegionServer 可能已收到或未收到近区域请求。主服务器重试向服务器发送关闭请求,直到 RPC 通过或主服务器用完为止。 -
如果 RegionServer 未联机或抛出
NotServingRegionException,则主服务器将该区域移至OFFLINE状态并将其重新分配给其他 RegionServer。 -
如果 RegionServer 处于联机状态,但在主计算机用完重试后无法访问,则主服务器会将该区域移至
FAILED_CLOSE状态,并且在操作员从 HBase shell 进行干预或服务器已停止之前不会采取进一步操作。 -
如果 RegionServer 获取关闭区域请求,它将关闭该区域并通知主服务器。主设备将区域移动到
CLOSED状态,并将其重新分配给不同的 RegionServer。 -
在分配区域之前,如果区域处于
CLOSED状态,则主区域会自动将区域移动到OFFLINE状态。 -
当 RegionServer 即将拆分区域时,它会通知主服务器。主设备将要分割的区域从
OPEN状态移动到SPLITTING状态,并将要创建的两个新区域添加到 RegionServer。这两个区域最初处于SPLITTING_NEW状态。 -
通知主服务器后,RegionServer 开始拆分该区域。一旦超过不返回点,RegionServer 就会再次通知主站,以便主站可以更新
hbase:meta表。但是,在服务器通知拆分完成之前,主服务器不会更新区域状态。如果分割成功,则分割区域从SPLITTING移动到SPLIT状态,并且两个新区域从SPLITTING_NEW移动到OPEN状态。 -
如果分割失败,则分割区域从
SPLITTING移回OPEN状态,并且创建的两个新区域从SPLITTING_NEW移动到OFFLINE状态。 -
当 RegionServer 即将合并两个区域时,它会首先通知主服务器。主设备将要合并的两个区域从
OPEN合并到MERGING状态,并将保存合并区域区域内容的新区域添加到 RegionServer。新区域最初处于MERGING_NEW状态。 -
通知主服务器后,RegionServer 开始合并这两个区域。一旦超过不返回点,RegionServer 就会再次通知主服务器,以便主服务器可以更新 META。但是,在 RegionServer 通知合并已完成之前,主服务器不会更新区域状态。如果合并成功,则两个合并区域从
MERGING移动到MERGED状态,并且新区域从MERGING_NEW移动到OPEN状态。 -
如果合并失败,则两个合并区域从
MERGING移回到OPEN状态,并且为保持合并区域的内容而创建的新区域从MERGING_NEW移动到OFFLINE状态。 -
对于
FAILED_OPEN或FAILED_CLOSE状态的区域,当操作员通过 HBase Shell 重新分配它们时,主设备会尝试再次关闭它们。
72.3。 Region-RegionServer 的位置
随着时间的推移,Region-RegionServer 的位置是通过 HDFS 块复制实现的。在选择写入副本的位置时,HDFS 客户端默认执行以下操作:
-
第一个副本写入本地节点
-
第二个副本写入另一个机架上的随机节点
-
第三个副本与第二个副本写在同一个机架上,但是在随机选择的不同节点上
-
后续副本将写入群集上的随机节点。请参阅此页面上的 _ 副本放置:第一个婴儿步骤 _: HDFS 架构
因此,HBase 最终在冲洗或压实之后实现区域的局部性。在 RegionServer 故障转移情况下,可以为 RegionServer 分配具有非本地 StoreFiles 的区域(因为没有任何副本是本地的),但是当在该区域中写入新数据,或者压缩表并重写 StoreFiles 时,它们将成为 RegionServer 的“本地”。
有关详细信息,请参阅此页面上的 _ 副本放置:第一个婴儿步骤 _: HDFS 架构以及 Lars George 关于 HBase 和 HDFS 位置的博客。
72.4。地区分裂
区域在达到配置的阈值时分割。下面我们简单地讨论这个话题。有关更长时间的展示,请参阅我们的 Enis Soztutar 的 Apache HBase 区域拆分和合并。
Splits 在 RegionServer 上独立运行;即师父不参加。 RegionServer 拆分一个区域,对拆分区域进行离线,然后将子区域添加到hbase:meta,打开父级托管 RegionServer 上的女儿,然后将拆分报告给 Master。请参阅 Managed Splitting ,了解如何手动管理拆分(以及为什么要这样做)。
72.4.1。自定义拆分策略
您可以使用自定义 RegionSplitPolicy (HBase 0.94+)覆盖默认拆分策略。通常,自定义拆分策略应该扩展 HBase 的默认拆分策略: IncreaseToUpperBoundRegionSplitPolicy 。
策略可以通过 HBase 配置或基于每个表进行全局设置。
在 hbase-site.xml 中全局配置拆分策略
<property>
<name>hbase.regionserver.region.split.policy</name>
<value>org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy</value>
</property>
使用 Java API 在表上配置拆分策略
HTableDescriptor tableDesc = new HTableDescriptor("test");
tableDesc.setValue(HTableDescriptor.SPLIT_POLICY, ConstantSizeRegionSplitPolicy.class.getName());
tableDesc.addFamily(new HColumnDescriptor(Bytes.toBytes("cf1")));
admin.createTable(tableDesc);
----
使用 HBase Shell 在表上配置拆分策略
hbase> create 'test', {METADATA => {'SPLIT_POLICY' => 'org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy'}},{NAME => 'cf1'}
可以通过使用的 HBaseConfiguration 或基于每个表来全局设置策略:
HTableDescriptor myHtd = ...;
myHtd.setValue(HTableDescriptor.SPLIT_POLICY, MyCustomSplitPolicy.class.getName());
DisabledRegionSplitPolicy策略阻止手动区域拆分。
72.5。手动区域拆分
可以在创建表(预分割)时或在稍后的时间手动拆分表作为管理操作。出于以下一个或多个原因,您可以选择拆分您的区域。可能还有其他正当理由,但手动拆分表的需要也可能表明您的架构设计存在问题。
手动拆分表的原因
-
您的数据按时间序列或其他类似算法排序,该算法在表格末尾对新数据进行排序。这意味着持有最后一个区域的 Region Server 始终处于负载状态,而其他 Region Servers 处于空闲状态或大部分处于空闲状态。另请参见单调递增行键/时间序列数据。
-
您在桌子的一个区域中开发了一个意外的热点。例如,跟踪网络搜索的应用程序可能会因为有关该名人的新闻而对名人进行大量搜索而被淹没。有关此特定方案的更多讨论,请参见 perf.one.region 。
-
在群集中 RegionServers 数量大幅增加之后,可以快速分散负载。
-
在大容量负载之前,这可能会导致跨区域的异常和不均匀负载。
有关完全手动管理拆分的危险和可能的好处的讨论,请参阅管理拆分。
The
DisabledRegionSplitPolicypolicy blocks manual region splitting.
72.5.1。确定分裂点
手动拆分表的目的是为了在单独使用良好的 rowkey 设计无法实现的情况下,提高平衡群集负载的几率。牢记这一点,您划分区域的方式非常依赖于数据的特征。您可能已经知道拆分桌子的最佳方法。如果没有,你拆分表的方式取决于你的键是什么样的。
字母数字 Rowkeys
如果您的 rowkeys 以字母或数字开头,则可以在字母或数字边界处拆分表格。例如,以下命令创建一个表,其中区域在每个元音处分开,因此第一个区域具有 A-D,第二个区域具有 E-H,第三个区域具有 I-N,第四个区域具有 O-V,第五个区域具有 U-Z。
使用自定义算法
RegionSplitter 工具随 HBase 一起提供,并使用 SplitAlgorithm 为您确定分割点。作为参数,您可以为其提供算法,所需的区域数和列族。它包括三种分割算法。第一种是[HexStringSplit](https://hbase.apache.org/devapidocs/org/apache/hadoop/hbase/util/RegionSplitter.HexStringSplit.html)算法,它假设行键是十六进制字符串。第二个是[DecimalStringSplit](https://hbase.apache.org/devapidocs/org/apache/hadoop/hbase/util/RegionSplitter.DecimalStringSplit.html)算法,它假定行键是 00000000 到 99999999 范围内的十进制字符串。第三个[UniformSplit](https://hbase.apache.org/devapidocs/org/apache/hadoop/hbase/util/RegionSplitter.UniformSplit.html)假设行键是随机字节数组。你可能需要开发自己的[SplitAlgorithm](https://hbase.apache.org/devapidocs/org/apache/hadoop/hbase/util/RegionSplitter.SplitAlgorithm.html),使用提供的那些作为模型。
72.6。在线区域合并
Master 和 RegionServer 都参与在线区域合并事件。客户端将合并 RPC 发送到主服务器,然后主服务器将这些区域一起移动到负载较重的区域所在的 RegionServer。最后,主服务器将合并请求发送到此 RegionServer,然后运行合并。与区域拆分过程类似,区域合并在 RegionServer 上作为本地事务运行。它勾勒出区域,然后合并文件系统上的两个区域,从hbase:meta原子删除合并区域并将合并区域添加到hbase:meta,打开 RegionServer 上的合并区域并将合并报告给主区域。
HBase shell 中区域合并的示例
$ hbase> merge_region 'ENCODED_REGIONNAME', 'ENCODED_REGIONNAME'
$ hbase> merge_region 'ENCODED_REGIONNAME', 'ENCODED_REGIONNAME', true
这是一个异步操作,调用立即返回而不等待合并完成。将true作为可选的第三个参数传递将强制合并。通常只能合并相邻区域。 force参数会覆盖此行为,仅供专家使用。
72.7。商店
商店拥有一个 MemStore 和 0 个或更多 StoreFiles(HFiles)。商店对应于给定区域的表的列族。
72.7.1。那种 MEMSTORE
MemStore 保存对 Store 的内存修改。修改是 Cells / KeyValues。请求刷新时,当前的 MemStore 将移动到快照并被清除。 HBase 继续提供来自新 MemStore 和后备快照的编辑,直到刷新器报告刷新成功。此时,快照将被丢弃。请注意,当刷新发生时,属于同一区域的 MemStore 都将被刷新。
72.7.2。 MemStore Flush
可以在下面列出的任何条件下触发 MemStore 刷新。最小冲洗单位是每个区域,而不是单个 MemStore 级别。
-
当 MemStore 达到
hbase.hregion.memstore.flush.size指定的大小时,属于其区域的所有 MemStore 都将刷新到磁盘。 -
当整个 MemStore 使用率达到
hbase.regionserver.global.memstore.upperLimit指定的值时,来自不同区域的 MemStores 将刷新到磁盘,以减少 RegionServer 中的 MemStore 总体使用量。刷新顺序基于区域的 MemStore 用法的降序。
区域将刷新其 MemStore,直到整个 MemStore 使用率降至或略低于
hbase.regionserver.global.memstore.lowerLimit。 -
当给定区域服务器的 WAL 中的 WAL 日志条目数达到
hbase.regionserver.max.logs中指定的值时,来自不同区域的 MemStores 将刷新到磁盘以减少 WAL 中的日志数。冲洗订单基于时间。
具有最早 MemStores 的区域首先被刷新,直到 WAL 计数降至
hbase.regionserver.max.logs以下。
72.7.3。扫描
-
当客户端对表发出扫描时,HBase 会生成
RegionScanner对象,每个区域一个,以提供扫描请求。 -
RegionScanner对象包含StoreScanner对象列表,每列一个对象。 -
每个
StoreScanner对象还包含StoreFileScanner对象的列表,对应于相应列族的每个 StoreFile 和 HFile,以及 MemStore 的KeyValueScanner对象列表。 -
这两个列表合并为一个,按照升序排序,列表末尾的 MemStore 扫描对象。
-
构造
StoreFileScanner对象时,它与MultiVersionConcurrencyControl读取点相关联,该读取点是当前memstoreTS,过滤掉读取点之外的任何新更新。
72.7.4。 StoreFile(HFile)
StoreFiles 是您的数据所在的位置。
HFile 格式
HFile 文件格式基于[BigTable 2006 ]论文和 Hadoop 的 TFile 中描述的 SSTable 文件(单元测试套件和压缩线束是直接取自 TFile)。 Schubert Zhang 关于 HFile 的博文:存储分类键值对的块索引文件格式对 HBase 的 HFile 进行了全面介绍。 Matteo Bertozzi 也提出了一个有用的描述, HBase I / O:HFile 。
有关更多信息,请参阅 HFile 源代码。另请参阅带有内联块(版本 2)的 HBase 文件格式,以获取有关 0.92 中包含的 HFile v2 格式的信息。
HFile 工具
要查看 HFile 内容的文本化版本,您可以使用hbase hfile工具。键入以下内容以查看用法:
$ ${HBASE_HOME}/bin/hbase hfile
例如,要查看文件 hdfs://10.81.47.41:8020 / hbase / default / TEST / 1418428042 / DSMP / 4759508618286845475 的内容,请键入以下内容:
$ ${HBASE_HOME}/bin/hbase hfile -v -f hdfs://10.81.47.41:8020/hbase/default/TEST/1418428042/DSMP/4759508618286845475
如果你不使用选项-v 来查看 HFile 的摘要。有关hfile工具的其他信息,请参阅用法。
在此工具的输出中,您可能会在“Mid-key”/“firstKey”/“lastKey”等位置看到某些键的“seqid = 0”。这些是'KeyOnlyKeyValue'类型实例 - 意味着它们的 seqid 是无关紧要的&amp;我们只需要这些键值实例的键。
HDFS 上的 StoreFile 目录结构
有关目录结构的 HDFS 上 StoreFiles 的详细信息,请参阅浏览 HBase 对象的 HDFS 。
72.7.5。块
StoreFiles 由块组成。 blocksize 是基于每个 ColumnFamily 配置的。
压缩发生在 StoreFiles 中的块级别。有关压缩的更多信息,请参见 HBase 中的压缩和数据块编码。
有关块的更多信息,请参阅 HFileBlock 源代码。
72.7.6。核心价值
KeyValue 类是 HBase 中数据存储的核心。 KeyValue 包装一个字节数组,并将偏移量和长度转换为传递的数组,该数组指定将内容解释为 KeyValue 的位置。
字节数组中的 KeyValue 格式为:
-
keylength
-
valuelength
-
键
-
值
密钥进一步分解为:
-
rowlength
-
行(即 rowkey)
-
columnfamilylength
-
的 ColumnFamily
-
列限定符
-
时间戳
-
keytype(例如,Put,Delete,DeleteColumn,DeleteFamily)
KeyValue 实例是 _ 而不是 _ 跨块分割。例如,如果存在 8 MB KeyValue,即使块大小为 64kb,此 KeyValue 也将作为相干块读入。有关更多信息,请参阅 KeyValue 源代码。
例
为了强调上述几点,请检查同一行的两个不同列的两个 Puts 会发生什么:
-
放#1:
rowkey=row1, cf:attr1=value1 -
放#2:
rowkey=row1, cf:attr2=value2
即使这些是同一行,也会为每列创建一个 KeyValue:
Put#1 的关键部分:
-
rowlength -----------→ 4 -
row -----------------→ row1 -
columnfamilylength --→ 2 -
columnfamily --------→ cf -
columnqualifier -----→ attr1 -
timestamp -----------→ server time of Put -
keytype -------------→ Put
Put#2 的关键部分:
-
rowlength -----------→ 4 -
row -----------------→ row1 -
columnfamilylength --→ 2 -
columnfamily --------→ cf -
columnqualifier -----→ attr2 -
timestamp -----------→ server time of Put -
keytype -------------→ Put
了解 rowkey,ColumnFamily 和 column(aka columnqualifier)嵌入在 KeyValue 实例中至关重要。这些标识符越长,KeyValue 就越大。
72.7.7。压实
模棱两可的术语
-
StoreFile 是 HFile 的外观。在压缩方面,StoreFile 的使用似乎在过去一直盛行。
-
_ 商店 _ 与列族相同。商店文件与商店或 ColumnFamily 相关。
-
如果您想了解更多关于 StoreFiles 与 HFiles 和 Stores 与 ColumnFamilies 的信息,请参阅 HBASE-11316 。
当 MemStore 达到给定大小(hbase.hregion.memstore.flush.size)时,它会将其内容刷新到 StoreFile。商店中的 StoreFiles 数量会随着时间的推移而增加。 _ 压缩 _ 是一种通过将它们合并在一起来减少 Store 中 StoreFiles 数量的操作,以提高读取操作的性能。压缩可能需要大量资源,并且可能会因许多因素而有助于或阻碍性能。
压缩分为两类:次要和主要。次要和主要压缩在以下方面有所不同。
_ 次要压缩 _ 通常选择少量小的相邻 StoreFiles 并将它们重写为单个 StoreFile。由于潜在的副作用,次要压缩不会删除(过滤掉)删除或过期版本。有关如何处理与压缩相关的删除和版本的信息,请参阅压缩和删除和压缩和版本。对于给定的商店,次要压缩的最终结果是更少,更大的 StoreFiles。
_ 主要压缩 _ 的最终结果是每个商店的单个 StoreFile。主要压缩也处理删除标记和最大版本。有关如何处理与压缩相关的删除和版本的信息,请参阅压缩和删除和压缩和版本。
压缩和删除
在 HBase 中发生显式删除时,实际上不会删除数据。而是编写 _ 墓碑 _ 标记。逻辑删除标记可防止数据与查询一起返回。在主要压缩过程中,实际上会删除数据,并从 StoreFile 中删除逻辑删除标记。如果由于 TTL 过期而发生删除,则不会创建逻辑删除。相反,过期的数据被过滤掉,不会写回到压缩的 StoreFile。
压缩和版本
创建列族时,可以通过指定HColumnDescriptor.setMaxVersions(int versions)指定要保留的最大版本数。默认值为3。如果存在的版本超过指定的最大值,则会过滤掉多余的版本,而不会将其写回到压缩的 StoreFile。
主要压缩可能会影响查询结果
在某些情况下,如果明确删除较新版本,则可能会无意中复活旧版本。请参阅主要压缩更改查询结果以获得更深入的解释。这种情况只有在压缩完成之前才有可能。
从理论上讲,主要压缩可以提高性能。但是,在高负载系统中,主要压缩可能需要不适当数量的资源并对性能产生负面影响。在默认配置中,主要压缩会自动安排在 7 天内运行一次。这有时不适合生产中的系统。您可以手动管理主要压缩。参见管理的压缩。
压缩不执行区域合并。有关区域合并的更多信息,请参见 Merge 。
压实开关
我们可以在区域服务器上打开和关闭压缩。关闭压缩也会中断任何当前正在进行的压缩。它可以使用 hbase shell 中的“compaction_switch”命令动态完成。如果从命令行完成,则在重新启动服务器时此设置将丢失。要在区域服务器之间保留更改,请修改 hbase-site.xml 中的配置 hbase.regionserver .compaction.enabled 并重新启动 HBase。
压缩策略 - HBase 0.96.x 及更新版本
压缩大型 StoreFiles 或一次使用太多 StoreFiles 会导致比集群能够处理的 IO 负载更多,而不会导致性能问题。 HBase 选择哪个 StoreFiles 包含在压缩中的方法(以及压缩是次要压缩还是主要压缩)称为 _ 压缩策略 _。
在 HBase 0.96.x 之前,只有一个压缩策略。原始压缩策略仍可作为RatioBasedCompactionPolicy使用。新的压缩默认策略称为ExploringCompactionPolicy,随后被移植到 HBase 0.94 和 HBase 0.95,并且是 HBase 0.96 及更新版本的默认值。它在 HBASE-7842 中实施。简而言之,ExploringCompactionPolicy尝试选择尽可能最好的 StoreFiles 集合,以最少的工作量压缩,而RatioBasedCompactionPolicy选择符合条件的第一个集合。
无论使用何种压缩策略,文件选择都由几个可配置参数控制,并以多步骤方式发生。这些参数将在上下文中进行解释,然后将在表格中给出,该表格显示了它们的描述,默认值以及更改它们的含义。
被卡住
当 MemStore 变得太大时,它需要将其内容刷新到 StoreFile。但是,Stores 配置了 StoreFiles 数字hbase.hstore.blockingStoreFiles的绑定,如果超过,则 MemStore 刷新必须等到 StoreFile 计数减少一个或多个压缩。如果 MemStore 太大而且 StoreFiles 的数量也太高,则该算法被称为“卡住”。默认情况下,我们将等待hbase.hstore.blockingWaitTime毫秒的压缩。如果这段时间到期,即使我们超过hbase.hstore.blockingStoreFiles计数,我们也会冲洗。
提高hbase.hstore.blockingStoreFiles计数将允许刷新,但具有许多 StoreFiles 的 Store 可能具有更高的读取延迟。试着想一想为什么 Compactions 没跟上。这是一种引发这种情况的写入突发还是经常出现,并且群集的写入量不足?
ExploringCompactionPolicy 算法
在选择压缩最有益的集合之前,ExploringCompactionPolicy 算法会考虑每个可能的相邻 StoreFiles 集合。
ExploringCompactionPolicy 工作得特别好的一种情况是,当您批量加载数据时,批量加载会创建比 StoreFiles 更大的 StoreFiles,而 StoreFiles 的数据保存的数据早于批量加载数据。这可以“欺骗”HBase 在每次需要压缩时选择执行主要压缩,并导致大量额外开销。使用 ExploringCompactionPolicy,主要压缩发生的频率要低得多,因为较小的压缩效率更高。
通常,ExploringCompactionPolicy 是大多数情况下的正确选择,因此是默认的压缩策略。您还可以使用 ExploringCompactionPolicy 和 Experimental:Stripe Compactions 。
可以在 hbase-server / src / main / java / org / apache / hadoop / hbase / regionserver / compactions / ExploringCompactionPolicy.java 中检查此策略的逻辑。以下是 ExploringCompactionPolicy 逻辑的演练。
-
列出商店中所有现有的 StoreFiles。算法的其余部分过滤此列表以提出将被选择用于压缩的 HFile 子集。
-
如果这是用户请求的压缩,则尝试执行请求的压缩类型,而不管通常选择什么。请注意,即使用户请求主要压缩,也可能无法执行主要压缩。这可能是因为并非列族中的所有 StoreFiles 都可用于压缩,或者因为列族中的存储太多。
-
某些 StoreFiles 会自动排除在考虑之外。这些包括:
-
大于
hbase.hstore.compaction.max.size的 StoreFiles -
由明确排除压缩的批量加载操作创建的 StoreFiles。您可以决定从压缩中排除因批量加载而产生的 StoreFiles。为此,请在批量装入操作期间指定
hbase.mapreduce.hfileoutputformat.compaction.exclude参数。
-
-
迭代步骤 1 中的列表,并列出所有可能的 StoreFiles 集合以压缩在一起。潜在集合是列表中的
hbase.hstore.compaction.min连续 StoreFiles 的分组。对于每个集合,执行一些完整性检查并确定这是否是可以完成的最佳压缩:-
如果此集合中的 StoreFiles 数量(不是 StoreFiles 的大小)小于
hbase.hstore.compaction.min或大于hbase.hstore.compaction.max,请将其考虑在内。 -
将这组 StoreFiles 的大小与目前在列表中找到的最小可能压缩的大小进行比较。如果这组 StoreFiles 的大小代表可以完成的最小压缩,则存储它以用作后退,如果算法被“卡住”并且否则将不选择 StoreFiles。见被困。
-
对这组 StoreFiles 中的每个 StoreFile 进行基于大小的健全性检查。
-
如果此 StoreFile 的大小大于
hbase.hstore.compaction.max.size,请将其考虑在内。 -
如果大小大于或等于
hbase.hstore.compaction.min.size,则根据基于文件的比率进行健全性检查,以查看它是否太大而无法考虑。如果符合以下条件,则完整性检查成功:
-
此集中只有一个 StoreFile,或
-
对于每个 StoreFile,其大小乘以
hbase.hstore.compaction.ratio(如果配置非高峰时间,则为hbase.hstore.compaction.ratio.offpeak,并且在非高峰时段)小于该集合中其他 HFile 的大小总和。
-
-
-
如果仍在考虑这组 StoreFiles,请将其与先前选择的最佳压缩进行比较。如果它更好,用这个替换先前选择的最佳压缩。
-
当处理完整个潜在压缩列表后,执行找到的最佳压缩。如果没有选择 StoreFiles 进行压缩,但有多个 StoreFiles,则假设算法被卡住(参见被困),如果是,请执行步骤 3 中找到的最小压缩。
RatioBasedCompactionPolicy 算法
RatioBasedCompactionPolicy 是 HBase 0.96 之前唯一的压缩策略,尽管 ExploringCompactionPolicy 现已被反向移植到 HBase 0.94 和 0.95。要使用 RatioBasedCompactionPolicy 而不是 ExploringCompactionPolicy,请在 hbase-site.xml 文件中将hbase.hstore.defaultengine.compactionpolicy.class设置为RatioBasedCompactionPolicy。要切换回 ExploringCompactionPolicy,请从 hbase-site.xml 中删除该设置。
以下部分将引导您完成用于在 RatioBasedCompactionPolicy 中选择 StoreFiles 进行压缩的算法。
-
第一阶段是创建所有压缩候选者的列表。将创建一个列表,该列表不包含在压缩队列中的所有 StoreFiles,以及比当前正在压缩的最新文件更新的所有 StoreFiles。 StoreFiles 列表按序列 ID 排序。将 Put 添加到预写日志(WAL)时生成序列 ID,并将其存储在 HFile 的元数据中。
-
检查算法是否卡住(参见被困,如果是,则强制进行主要压缩。这是 ExploringCompactionPolicy 算法通常比选择的更好的关键区域。 RatioBasedCompactionPolicy。
-
如果压缩是用户请求的,请尝试执行请求的压缩类型。请注意,如果所有 HFile 都不可用于压缩或存在太多 StoreFiles(超过
hbase.hstore.compaction.max),则可能无法进行主要压缩。 -
Some StoreFiles are automatically excluded from consideration. These include:
-
StoreFiles that are larger than
hbase.hstore.compaction.max.size -
StoreFiles that were created by a bulk-load operation which explicitly excluded compaction. You may decide to exclude StoreFiles resulting from bulk loads, from compaction. To do this, specify the
hbase.mapreduce.hfileoutputformat.compaction.excludeparameter during the bulk load operation.
-
-
主要压缩中允许的最大 StoreFiles 数由
hbase.hstore.compaction.max参数控制。如果列表包含的数量超过此数量的 StoreFiles,则即使进行了主要压缩,也会执行次要压缩。但是,即使存在多个hbase.hstore.compaction.maxStoreFiles 要压缩,仍会发生用户请求的主要压缩。 -
如果列表包含少于
hbase.hstore.compaction.minStoreFiles 以进行压缩,则会中止轻微压缩。请注意,可以在单个 HFile 上执行主要压缩。它的功能是删除删除和过期版本,并重置 StoreFile 上的位置。 -
hbase.hstore.compaction.ratio参数的值乘以小于给定文件的 StoreFiles 的总和,以确定是否在次要压缩期间选择了 StoreFile 进行压缩。例如,如果 hbase.hstore.compaction.ratio 为 1.2,则 FileX 为 5MB,FileY 为 2MB,FileZ 为 3MB:5 <= 1.2 x (2 + 3) or 5 <= 6在这种情况下,FileX 有资格进行轻微压缩。如果 FileX 为 7MB,则不符合轻微压缩的条件。这个比例有利于较小的 StoreFile。如果还配置了
hbase.offpeak.start.hour和hbase.offpeak.end.hour,则可以使用参数hbase.hstore.compaction.ratio.offpeak配置在非高峰时段使用的不同比率。 -
如果最后一次主要的压缩是很久以前并且要压缩多个 StoreFile,则会运行一个主要的压缩,即使它本来是次要的。默认情况下,主要压缩之间的最长时间为 7 天,加上或减去 4.8 小时,并在这些参数中随机确定。在 HBase 0.96 之前,主要压实期为 24 小时。请参阅下表中的
hbase.hregion.majorcompaction以调整或禁用基于时间的主要压缩。
压缩算法使用的参数
该表包含压缩的主要配置参数。这份清单并非详尽无遗。要从默认值中调整这些参数,请编辑 hbase-default.xml 文件。有关所有可用配置参数的完整列表,请参阅 config.files
hbase.hstore.compaction.min
在压缩之前必须符合压缩条件的最小 StoreFiles 数量才能运行。调整hbase.hstore.compaction.min的目的是避免使用太多的小型 StoreFiles 来压缩。将此值设置为 2 会在每次在 Store 中存在两个 StoreFiles 时导致轻微压缩,这可能不合适。如果将此值设置得太高,则需要相应调整所有其他值。对于大多数情况,默认值是合适的。在以前版本的 HBase 中,参数hbase.hstore.compaction.min被称为hbase.hstore.compactionThreshold。
默认:3
hbase.hstore.compaction.max
无论符合条件的 StoreFiles 的数量,将为单个次要压缩选择的 StoreFiles 的最大数量。实际上,hbase.hstore.compaction.max的值控制单个压缩完成所需的时间长度。将其设置得更大意味着更多 StoreFiles 包含在压缩中。对于大多数情况,默认值是合适的。
默认:10
hbase.hstore.compaction.min.size
小于此大小的 StoreFile 将始终符合轻微压缩的条件。通过hbase.hstore.compaction.ratio评估此大小或更大的 StoreFiles 以确定它们是否符合条件。由于此限制表示所有小于此值的 StoreFiles 的“自动包含”限制,因此可能需要在写入 1-2 MB 范围内的许多文件的写入繁重环境中减少此值,因为每个 StoreFile 都将成为目标压缩和生成的 StoreFiles 可能仍然在最小尺寸,需要进一步压缩。如果降低此参数,则会更快地触发比率检查。这解决了早期版本的 HBase 中出现的一些问题,但在大多数情况下不再需要更改此参数。
默认值:128 MB
hbase.hstore.compaction.max.size
大于此大小的 StoreFile 将被排除在压缩之外。提高hbase.hstore.compaction.max.size的效果更少,更大的 StoreFiles 不会经常被压缩。如果您觉得压缩过于频繁而没有太多好处,您可以尝试提高此值。
默认:Long.MAX_VALUE
hbase.hstore.compaction.ratio
对于轻微压缩,此比率用于确定大于hbase.hstore.compaction.min.size的给定 StoreFile 是否有资格进行压缩。它的作用是限制大型 StoreFile 的压缩。 hbase.hstore.compaction.ratio的值表示为浮点小数。
-
较大的比例(例如 10)将生成单个巨型 StoreFile。相反,值为.25,将产生类似于 BigTable 压缩算法的行为,产生四个 StoreFiles。
-
建议使用介于 1.0 和 1.4 之间的中等值。调整此值时,您将平衡写入成本与读取成本。提高值(类似于 1.4)会产生更多的写入成本,因为您将压缩更大的 StoreFiles。但是,在读取过程中,HBase 需要通过更少的 StoreFiles 来完成读取。如果你不能利用布隆过滤器,请考虑这种方法。
-
或者,您可以将此值降低到 1.0 以降低写入的后台成本,并用于限制读取期间触摸的 StoreFiles 的数量。对于大多数情况,默认值是合适的。
默认:
1.2F
hbase.hstore.compaction.ratio.offpeak
非高峰时段使用的压实比例,如果还配置了非高峰时段(见下文)。表示为浮点小数。这允许在设定的时间段内更具侵略性(或者如果将其设置为低于hbase.hstore.compaction.ratio则更不具侵略性)压实。如果禁用非高峰时忽略(默认)。这与hbase.hstore.compaction.ratio的作用相同。
默认:5.0F
hbase.offpeak.start.hour
非高峰时段的开始,表示为 0 到 23 之间的整数,包括 0 和 23。设置为-1 可禁用非高峰。
默认:-1(禁用)
hbase.offpeak.end.hour
非高峰时段结束,表示为 0 到 23 之间的整数,包括 0 和 23。设置为-1 可禁用非高峰。
Default: -1 (disabled)
hbase.regionserver.thread.compaction.throttle
压缩有两种不同的线程池,一种用于大型压缩,另一种用于小型压缩。这有助于快速压缩精益表(例如hbase:meta)。如果压缩大于此阈值,则会进入大型压缩池。在大多数情况下,默认值是合适的。
默认:2 x hbase.hstore.compaction.max x hbase.hregion.memstore.flush.size(默认为128)
hbase.hregion.majorcompaction
主要压缩之间的时间,以毫秒表示。设置为 0 可禁用基于时间的自动主要压缩。用户请求的和基于大小的主要压缩仍将运行。该值乘以hbase.hregion.majorcompaction.jitter,以使压缩在给定的时间窗口内以稍微随机的时间开始。
默认:7 天(604800000毫秒)
hbase.hregion.majorcompaction.jitter
应用于 hbase.hregion.majorcompaction 的乘数,以使压缩在hbase.hregion.majorcompaction的任一侧发生给定的时间。数字越小,压缩越接近hbase.hregion.majorcompaction间隔。表示为浮点小数。
默认:.50F
压缩文件选择
遗产信息
此部分由于历史原因而保留,并且指的是在 HBase 0.96.x 之前压缩的方式。如果启用 RatioBasedCompactionPolicy 算法,您仍然可以使用此行为。有关压缩在 HBase 0.96.x 及更高版本中的工作方式的信息,请参阅压缩。
要了解 StoreFile 选择的核心算法,Store 源代码中有一些 ASCII 技术将作为有用的参考。
它已复制如下:
/* normal skew:
*
* older ----> newer
* _
* | | _
* | | | | _
* --|-|- |-|- |-|---_-------_------- minCompactSize
* | | | | | | | | _ | |
* | | | | | | | | | | | |
* | | | | | | | | | | | |
*/
重要的旋钮:
-
hbase.hstore.compaction.ratio压缩文件选择算法中使用的比率(默认值为 1.2f)。 -
hbase.hstore.compaction.min(在 HBase v 0.90 中称为hbase.hstore.compactionThreshold)(文件)要为压缩发生选择的每个商店的最小 StoreFiles 数(默认值为 2)。 -
hbase.hstore.compaction.max(files)每次轻微压缩时压缩的最大 StoreFiles 数(默认值为 10)。 -
hbase.hstore.compaction.min.size(字节)任何小于此设置的 StoreFile 都会自动成为压缩的候选对象。默认为hbase.hregion.memstore.flush.size(128 mb)。 -
hbase.hstore.compaction.max.size(。92)(字节)任何大于此设置的 StoreFile 都会自动从压缩中排除(默认为 Long.MAX_VALUE)。
次要压缩 StoreFile 选择逻辑是基于大小的,并在file ⇐ sum(smaller_files) * hbase.hstore.compaction.ratio时选择要压缩的文件。
次要压缩文件选择 - 示例#1(基本示例)
此示例反映了单元测试TestCompactSelection中的示例。
-
hbase.hstore.compaction.ratio= 1.0f -
hbase.hstore.compaction.min= 3(档案) -
hbase.hstore.compaction.max= 5(文件) -
hbase.hstore.compaction.min.size= 10(字节) -
hbase.hstore.compaction.max.size= 1000(字节)
存在以下 StoreFiles:每个 100,50,33,12 和 12 个字节(从最旧到最新)。使用上述参数,将为轻微压缩选择的文件为 23,12 和 12。
为什么?
-
100→否,因为总和(50,23,12,12)* 1.0 = 97。
-
50→否,因为总和(23,12,12)* 1.0 = 47。
-
23→是,因为总和(12,12)* 1.0 = 24。
-
12→是,因为已包含上一个文件,因为这不超过最大文件限制 5
-
12→是,因为已包含上一个文件,因为这不超过最大文件限制 5。
次要压缩文件选择 - 示例#2(没有足够的文件压缩)
This example mirrors an example from the unit test TestCompactSelection.
-
hbase.hstore.compaction.ratio= 1.0f -
hbase.hstore.compaction.min= 3 (files) -
hbase.hstore.compaction.max= 5 (files) -
hbase.hstore.compaction.min.size= 10 (bytes) -
hbase.hstore.compaction.max.size= 1000 (bytes)
存在以下 StoreFiles:每个 100,25,12 和 12 个字节(从最旧到最新)。使用上述参数,将不会启动压缩。
Why?
-
100→否,因为总和(25,12,12)* 1.0 = 47
-
25→否,因为总和(12,12)* 1.0 = 24
-
12→No.候选因为 sum(12)* 1.0 = 12,只有 2 个文件要压缩,小于 3 的阈值
-
12→No.候选,因为以前的 StoreFile 是,但没有足够的文件来压缩
次要压缩文件选择 - 示例#3(将文件限制为紧凑)
This example mirrors an example from the unit test TestCompactSelection.
-
hbase.hstore.compaction.ratio= 1.0f -
hbase.hstore.compaction.min= 3 (files) -
hbase.hstore.compaction.max= 5 (files) -
hbase.hstore.compaction.min.size= 10 (bytes) -
hbase.hstore.compaction.max.size= 1000 (bytes)
存在以下 StoreFiles:每个 7,6,5,4,3,2 和 1 个字节(从最旧到最新)。使用上述参数,为轻微压缩选择的文件是 7,6,5,4,3。
Why?
-
7→是,因为总和(6,5,4,3,2,1)* 1.0 = 21.此外,7 小于最小尺寸
-
6→是,因为总和(5,4,3,2,1)* 1.0 = 15.此外,6 小于最小尺寸。
-
5→是,因为总和(4,3,2,1)* 1.0 = 10.此外,5 小于最小尺寸。
-
4→是,因为总和(3,2,1)* 1.0 = 6.此外,4 小于最小尺寸。
-
3→是,因为 sum(2,1)* 1.0 = 3.此外,3 小于最小尺寸。
-
2→编号候选,因为选择了先前的文件,并且 2 小于最小尺寸,但已达到要压缩的最大文件数。
-
1→编号候选,因为选择了上一个文件,1 小于最小尺寸,但已达到要压缩的最大文件数。
密钥配置选项的影响此信息现在包含在压缩算法使用的参数的配置参数表中。
日期分层压缩
日期分层压缩是一种日期感知的存储文件压缩策略,有利于时间序列数据的时间范围扫描。
何时使用日期分层压缩
考虑使用 Date Tiered Compaction 进行有限时间范围的读取,尤其是对最近数据的扫描
不要用它
-
随机获得没有有限的时间范围
-
经常删除和更新
-
频繁的乱序数据会写入创建长尾的情况,尤其是具有未来时间戳的写入
-
频繁的批量加载,时间范围很重叠
绩效改进
性能测试表明,时间范围扫描的性能在有限的时间范围内有很大改善,特别是对最近数据的扫描。
启用日期分层压缩
您可以通过将hbase.hstore.engine.class设置为org.apache.hadoop.hbase.regionserver.DateTieredStoreEngine来为表或列族启用日期分层压缩。
如果使用所有默认设置,您还需要将hbase.hstore.blockingStoreFiles设置为高数字,例如 60,而不是默认值 12)。如果更改参数,则使用 1.5~2 x 预计文件计数,预计文件计数=每层的窗口 x 层数+传入窗口最小值+早于最大年龄的文件
您还需要将hbase.hstore.compaction.max设置为与hbase.hstore.blockingStoreFiles相同的值以取消阻止主要压缩。
过程:启用日期分层压缩
-
在 HBase shell 中运行以下命令之一。将表名
orders_table替换为表的名称。alter 'orders_table', CONFIGURATION => {'hbase.hstore.engine.class' => 'org.apache.hadoop.hbase.regionserver.DateTieredStoreEngine', 'hbase.hstore.blockingStoreFiles' => '60', 'hbase.hstore.compaction.min'=>'2', 'hbase.hstore.compaction.max'=>'60'} alter 'orders_table', {NAME => 'blobs_cf', CONFIGURATION => {'hbase.hstore.engine.class' => 'org.apache.hadoop.hbase.regionserver.DateTieredStoreEngine', 'hbase.hstore.blockingStoreFiles' => '60', 'hbase.hstore.compaction.min'=>'2', 'hbase.hstore.compaction.max'=>'60'}} create 'orders_table', 'blobs_cf', CONFIGURATION => {'hbase.hstore.engine.class' => 'org.apache.hadoop.hbase.regionserver.DateTieredStoreEngine', 'hbase.hstore.blockingStoreFiles' => '60', 'hbase.hstore.compaction.min'=>'2', 'hbase.hstore.compaction.max'=>'60'} -
如果需要,配置其他选项。有关详细信息,请参阅配置日期分层压缩。
过程:禁用日期分层压缩
-
将
hbase.hstore.engine.class选项设置为 nil 或org.apache.hadoop.hbase.regionserver.DefaultStoreEngine。任一选项都具有相同的效果。确保将您更改的其他选项也设置为原始设置。alter 'orders_table', CONFIGURATION => {'hbase.hstore.engine.class' => 'org.apache.hadoop.hbase.regionserver.DefaultStoreEngine', 'hbase.hstore.blockingStoreFiles' => '12', 'hbase.hstore.compaction.min'=>'6', 'hbase.hstore.compaction.max'=>'12'}}
当您以任一方式更改商店引擎时,可能会在大多数区域执行主要压缩。在新表上没有必要这样做。
配置日期分层压缩
应在表或列族级别配置日期分层压缩的每个设置。如果使用 HBase shell,则常规命令模式如下:
alter 'orders_table', CONFIGURATION => {'key' => 'value', ..., 'key' => 'value'}}
层参数
您可以通过更改以下参数的设置来配置日期层:
| 设置 | 笔记 |
|---|---|
hbase.hstore.compaction.date.tiered.max.storefile.age.millis |
max-timestamp 小于此值的文件将不再被压缩。默认值为 Long.MAX_VALUE。
| | hbase.hstore.compaction.date.tiered.base.window.millis |
基本窗口大小(以毫秒为单位)。默认为 6 小时。
| | hbase.hstore.compaction.date.tiered.windows.per.tier |
每层的窗口数。默认为 4。
| | hbase.hstore.compaction.date.tiered.incoming.window.min |
在传入窗口中压缩的最小文件数。将其设置为窗口中预期的文件数,以避免浪费压缩。默认为 6。
| | hbase.hstore.compaction.date.tiered.window.policy.class |
在同一时间窗口内选择存储文件的策略。它不适用于传入窗口。在探索压缩时默认。这是为了避免浪费的压实。
|
压缩 Throttler
通过分层压缩,群集中的所有服务器将同时将窗口提升到更高层,因此建议使用压缩节流:将hbase.regionserver.throughput.controller设置为org.apache.hadoop.hbase.regionserver.compactions.PressureAwareCompactionThroughputController。
有关日期分层压缩的更多信息,请参阅 https://docs.google.com/document/d/1_AmlNb2N8Us1xICsTeGDLKIqL6T-oHoRLZ323MG_uy8 中的设计规范
实验:条纹压缩
条带压缩是 HBase 0.98 中添加的一个实验性功能,旨在改善大区域或非均匀分布的行键的压缩。为了实现更小和/或更细粒度的压缩,区域内的 StoreFiles 分别维护该区域的若干行键子范围或“条带”。条带对 HBase 的其余部分是透明的,因此对 HFiles 或数据的其他操作无需修改即可工作。
条带压缩会更改 HFile 布局,从而在区域内创建子区域。这些子区域更容易压缩,并且应该导致更少的主要压缩。这种方法减轻了较大区域的一些挑战。
条带压缩与 Compaction 完全兼容,并与 ExploringCompactionPolicy 或 RatioBasedCompactionPolicy 结合使用。它可以为现有表启用,如果稍后禁用,表将继续正常运行。
何时使用条纹压缩
如果您具有以下任一条件,请考虑使用条带压缩:
-
大区域。您可以获得较小区域的积极影响,而无需 MemStore 和区域管理开销的额外开销。
-
非统一键,例如键中的时间维度。只有接收新密钥的条纹才需要压缩。如果有的话,旧数据不会经常压缩
Performance Improvements
性能测试表明,读取性能有所提高,读写性能的可变性大大降低。在大的非均匀行键区域上可以看到整体的长期性能改进,例如以散列为前缀的时间戳键。在已经很大的桌子上,这些性能提升是最显着的。性能改进可能会扩展到区域分割。
启用条带压缩
您可以通过将hbase.hstore.engine.class设置为org.apache.hadoop.hbase.regionserver.StripeStoreEngine来为表或列族启用条带压缩。您还需要将hbase.hstore.blockingStoreFiles设置为高数字,例如 100(而不是默认值 10)。
过程:启用条带压缩
-
Run one of following commands in the HBase shell. Replace the table name
orders_tablewith the name of your table.alter 'orders_table', CONFIGURATION => {'hbase.hstore.engine.class' => 'org.apache.hadoop.hbase.regionserver.StripeStoreEngine', 'hbase.hstore.blockingStoreFiles' => '100'} alter 'orders_table', {NAME => 'blobs_cf', CONFIGURATION => {'hbase.hstore.engine.class' => 'org.apache.hadoop.hbase.regionserver.StripeStoreEngine', 'hbase.hstore.blockingStoreFiles' => '100'}} create 'orders_table', 'blobs_cf', CONFIGURATION => {'hbase.hstore.engine.class' => 'org.apache.hadoop.hbase.regionserver.StripeStoreEngine', 'hbase.hstore.blockingStoreFiles' => '100'} -
如果需要,配置其他选项。有关详细信息,请参阅配置条带压缩。
-
启用表格。
过程:禁用条带压缩
-
将
hbase.hstore.engine.class选项设置为 nil 或org.apache.hadoop.hbase.regionserver.DefaultStoreEngine。任一选项都具有相同的效果。alter 'orders_table', CONFIGURATION => {'hbase.hstore.engine.class' => 'rg.apache.hadoop.hbase.regionserver.DefaultStoreEngine'} -
Enable the table.
在以任一方式更改存储引擎后启用大表时,可能会在大多数区域上执行主要压缩。在新表上没有必要这样做。
配置条带压缩
应该在表或列族级别配置条带压缩的每个设置。如果使用 HBase shell,则常规命令模式如下:
alter 'orders_table', CONFIGURATION => {'key' => 'value', ..., 'key' => 'value'}}
区域和条带大小
您可以根据区域大小调整配置条带大小。默认情况下,新区域将以一个条带开头。在条带变得太大(16 x MemStore 刷新大小)之后的下一次压缩中,它被分成两个条带。随着区域的增长,条纹分裂继续,直到该区域足够大以分裂。
您可以为自己的数据改进此模式。一个好的规则是瞄准至少 1 GB 的条带大小,以及用于统一行键的大约 8-12 个条带。例如,如果您的区域为 30 GB,则 12 x 2.5 GB 条纹可能是一个很好的起点。
| Setting | Notes |
|---|---|
hbase.store.stripe.initialStripeCount |
启用条带压缩时要创建的条带数。您可以按如下方式使用它:
-
对于相对统一的行键,如果您知道上面的条纹的近似目标数,则可以通过从几个条纹(2,5,10 ......)开始来避免一些分裂开销。如果早期数据不代表整体行密钥分配,则效率不高。
-
对于包含大量数据的现有表,此设置将有效地预分割条带。
-
对于诸如散列前缀顺序密钥之类的密钥,每个区域具有多个散列前缀,预分割可能是有意义的。
| |
hbase.store.stripe.sizeToSplit|
条带在分割之前增长的最大大小。根据上述尺寸考虑,将此项与hbase.store.stripe.splitPartCount结合使用可控制目标条带尺寸(sizeToSplit = splitPartsCount * target stripe size)。
| | hbase.store.stripe.splitPartCount |
分割条带时要创建的新条带数。默认值为 2,适用于大多数情况。对于非统一行键,您可以尝试将数字增加到 3 或 4,以将到达的更新隔离到区域的较窄切片中,而无需额外的拆分。
|
MemStore 大小设置
默认情况下,刷新根据现有条带边界和要刷新的行键从一个 MemStore 创建多个文件。这种方法可以最大限度地减少写入放大,但如果 MemStore 很小且有很多条纹,则可能不合需要,因为文件太小。
在这种情况下,您可以将hbase.store.stripe.compaction.flushToL0设置为true。这将导致 MemStore 刷新创建单个文件。当至少hbase.store.stripe.compaction.minFilesL0这样的文件(默认为 4)累积时,它们将被压缩成条带文件。
正常压实配置和条带压缩
适用于正常压缩的所有设置(参见压缩算法使用的参数)适用于条带压缩。最小和最大文件数例外,默认设置为较高值,因为条带中的文件较小。要控制这些条纹压缩,请使用hbase.store.stripe.compaction.minFiles和hbase.store.stripe.compaction.maxFiles,而不是hbase.hstore.compaction.min和hbase.hstore.compaction.max。
73.批量装载
73.1。概观
HBase 包括几种将数据加载到表中的方法。最直接的方法是使用 MapReduce 作业中的TableOutputFormat类,或使用普通的客户端 API;然而,这些并不总是最有效的方法。
批量加载功能使用 MapReduce 作业以 HBase 的内部数据格式输出表数据,然后直接将生成的 StoreFiles 加载到正在运行的集群中。与仅使用 HBase API 相比,使用批量加载将使用更少的 CPU 和网络资源。
73.2。批量加载架构
HBase 批量加载过程包括两个主要步骤。
73.2.1。通过 MapReduce 作业准备数据
批量加载的第一步是使用HFileOutputFormat2从 MapReduce 作业生成 HBase 数据文件(StoreFiles)。此输出格式以 HBase 的内部存储格式写出数据,以便以后可以非常有效地将它们加载到集群中。
为了有效地工作,必须配置HFileOutputFormat2使得每个输出 HFile 适合单个区域。为此,将输出将批量加载到 HBase 中的作业使用 Hadoop 的TotalOrderPartitioner类将映射输出划分为密钥空间的不相交范围,对应于表中区域的键范围。
HFileOutputFormat2包括便利功能configureIncrementalLoad(),它根据表格的当前区域边界自动设置TotalOrderPartitioner。
73.2.2。完成数据加载
准备好数据导入后,使用带有“importtsv.bulk.output”选项的importtsv工具或使用HFileOutputFormat的其他 MapReduce 作业,completebulkload工具用于将数据导入正在运行的集群。此命令行工具遍历准备好的数据文件,并且每个文件确定文件所属的区域。然后它会联系相应的 RegionServer,它采用 HFile,将其移入其存储目录并使数据可供客户端使用。
如果在批量装载准备过程中或在准备和完成步骤之间区域边界已更改,则completebulkload实用程序将自动将数据文件拆分为与新边界对应的部分。此过程效率不高,因此用户应注意尽量减少准备批量加载和将其导入群集之间的延迟,尤其是在其他客户端通过其他方式同时加载数据时。
$ hadoop jar hbase-server-VERSION.jar completebulkload [-c /path/to/hbase/config/hbase-site.xml] /user/todd/myoutput mytable
-c config-file选项可用于指定包含相应 hbase 参数的文件(例如,hbase-site.xml)(如果 CLASSPATH 上尚未提供)(此外,CLASSPATH 必须包含具有 zookeeper 配置文件的目录,如果 zookeeper 不是由 HBase 管理的)。
如果 HBase 中尚不存在目标表,则此工具将自动创建表。
73.3。也可以看看
有关引用的实用程序的更多信息,请参阅 ImportTsv 和 CompleteBulkLoad 。
请参阅操作方法:使用 HBase 批量加载,以及为什么获取最新博客的当前批量加载状态。
73.4。高级用法
尽管importtsv工具在许多情况下很有用,但高级用户可能希望以编程方式生成数据,或从其他格式导入数据。要开始这样做,请深入研究ImportTsv.java并检查 JavaDoc for HFileOutputFormat。
批量加载的导入步骤也可以通过编程方式完成。有关更多信息,请参见LoadIncrementalHFiles类。
73.5。批量加载复制
HBASE-13153 为批量加载的 HFile 增加了复制支持,自 HBase 1.3 / 2.0 起可用。通过将hbase.replication.bulkload.enabled设置为true(默认为false)启用此功能。您还需要将源群集配置文件复制到目标群集。
还需要其他配置:
-
hbase.replication.source.fs.conf.provider这定义了在目标集群中加载源集群文件系统客户端配置的类。应为目标群集中的所有 RS 配置此项。默认值为
org.apache.hadoop.hbase.replication.regionserver.DefaultSourceFSConfigurationProvider。 -
hbase.replication.conf.dir这表示将源群集的文件系统客户端配置复制到目标群集的基本目录。应为目标群集中的所有 RS 配置此项。默认值为
$HBASE_CONF_DIR。 -
hbase.replication.cluster.id群集中需要此配置,其中启用了批量加载数据的复制。源群集由目标群集使用此 ID 唯一标识。应为所有 RS 的源群集配置文件中的所有 RS 配置此项。
例如:如果将源群集 FS 客户端配置复制到目录/home/user/dc1/下的目标群集,则hbase.replication.cluster.id应配置为dc1,hbase.replication.conf.dir应配置为/home/user。
DefaultSourceFSConfigurationProvider仅支持xml类型文件。它仅加载源群集 FS 客户端配置一次,因此如果更新源群集 FS 客户端配置文件,则必须重新启动每个对等群集 RS 以重新加载配置。
74. HDFS
由于 HBase 在 HDFS 上运行(并且每个 StoreFile 都作为 HDFS 上的文件写入),因此了解 HDFS 架构非常重要,尤其是在存储文件,处理故障转移和复制块方面。
有关更多信息,请参阅 HDFS 架构上的 Hadoop 文档。
74.1。的 NameNode
NameNode 负责维护文件系统元数据。有关更多信息,请参阅上面的 HDFS 架构链接。
74.2。数据管理部
DataNode 负责存储 HDFS 块。有关更多信息,请参阅上面的 HDFS 架构链接。
75.时间线一致的高可用读数
当前 Assignment Manager V2 与区域副本不兼容,因此可能会破坏此功能。请谨慎使用。
75.1。介绍
从结构上看,HBase 从一开始就始终具有强大的一致性保证。所有读取和写入都通过单个区域服务器进行路由,这可确保所有写入按顺序发生,并且所有读取都会查看最新提交的数据。
但是,由于将读取单一归位到单个位置,如果服务器变得不可用,则区域服务器中托管的表的区域将在一段时间内不可用。区域恢复过程分为三个阶段 - 检测,分配和恢复。其中,检测通常是最长的,目前大约 20-30 秒,具体取决于 ZooKeeper 会话超时。在此期间和恢复完成之前,客户端将无法读取区域数据。
但是,对于某些用例,要么数据可能是只读的,要么对某些陈旧数据进行读取是可以接受的。通过时间线一致的高可用读取,HBase 可用于这类延迟敏感的用例,其中应用程序可能期望在读取完成时具有时间限制。
为了实现读取的高可用性,HBase 提供了一种称为 _ 区域复制 _ 的功能。在此模型中,对于表的每个区域,将有多个副本在不同的 RegionServers 中打开。默认情况下,区域复制设置为 1,因此只部署了一个区域副本,并且不会对原始模型进行任何更改。如果区域复制设置为 2 或更多,则主服务器将分配表的区域的副本。负载均衡器可确保区域副本不在同一区域服务器中共存,也可在同一机架中共存(如果可能)。
单个区域的所有副本将具有从 0 开始的唯一 replica_id。具有 replica_id == 0 的区域副本被称为主要区域,而其他区域 _ 次要区域 _ 或次要区域。只有主服务器可以接受来自客户端的写入,主服务器将始终包含最新的更改。由于所有写入仍然必须通过主区域,因此写入不是高度可用的(这意味着如果区域变得不可用,它们可能会阻塞一段时间)。
75.2。时间线一致性
通过此功能,HBase 引入了一致性定义,可以根据读取操作(获取或扫描)提供该定义。
public enum Consistency {
STRONG,
TIMELINE
}
Consistency.STRONG是 HBase 提供的默认一致性模型。如果表具有 region replication = 1,或者在具有区域副本的表中但读取是使用此一致性完成的,则读取始终由主要区域执行,因此不会对先前的行为进行任何更改,并且客户端始终观察最新数据。
如果使用Consistency.TIMELINE执行读取,则首先将读取的 RPC 发送到主区域服务器。在短暂的间隔(hbase.client.primaryCallTimeout.get,默认为 10 毫秒)之后,如果主服务器没有响应,也将发送辅助区域副本的并行 RPC。在此之后,从最先完成的 RPC 返回结果。如果响应从主要区域副本返回,我们始终可以知道数据是最新的。为此,添加了 Result.isStale()API 来检查陈旧性。如果结果来自辅助区域,则 Result.isStale()将设置为 true。然后,用户可以检查该字段以可能推断数据。
在语义方面,HBase 实现的 TIMELINE 一致性与这些方面的纯粹最终一致性不同:
-
单个归属和有序更新:区域复制与否,在写入端,仍然只有 1 个可以接受写入的已定义副本(主要)。此副本负责对编辑进行排序并防止冲突。这可以保证不同副本不会同时提交两个不同的写入,并且数据会发散。有了这个,就没有必要进行读取修复或最后时间戳获胜的冲突解决方案。
-
辅助节点也按主节点提交的顺序应用编辑。这样,辅助节点将包含任何时间点的原色数据的快照。这类似于 RDBMS 复制,甚至是 HBase 自己的多数据中心复制,但是在单个集群中。
-
在读取端,客户端可以检测读取是来自最新数据还是过时数据。此外,客户端可以在每个操作的基础上发出具有不同一致性要求的读取,以确保其自身的语义保证。
-
客户端仍然可以观察无序编辑,如果它首先观察来自一个辅助副本的读取,然后是另一个辅助副本,则可以及时返回。区域副本或基于事务 ID 的保证没有粘性。如果需要,可以稍后实施。
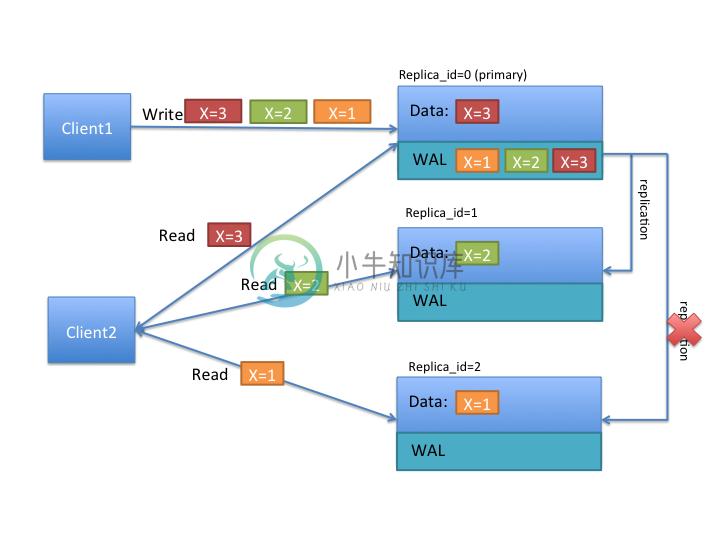 图 3.时间轴一致性
图 3.时间轴一致性
为了更好地理解 TIMELINE 语义,让我们看一下上图。假设有两个客户端,第一个客户端首先写入 x = 1,然后 x = 2,x = 3。如上所述,所有写入都由主要区域副本处理。写入保存在写入日志(WAL)中,并异步复制到其他副本。在上图中,请注意 replica_id = 1 接收到 2 次更新,其数据显示 x = 2,而 replica_id = 2 仅接收单次更新,其数据显示 x = 1。
如果 client1 以 STRONG 一致性读取,它将仅与 replica_id = 0 对话,因此保证观察到 x = 3 的最新值。如果客户端发出 TIMELINE 一致性读取,则 RPC 将转到所有副本(在主超时之后),并且将返回第一个响应的结果。因此,客户端可以看到 1,2 或 3 作为 x 的值。假设主要区域已失败,并且日志复制无法继续一段时间。如果客户端使用 TIMELINE 一致性进行多次读取,则可以先观察 x = 2,然后 x = 1,依此类推。
75.3。权衡
为读取可用性托管次要区域需要进行一些权衡,应根据用例仔细评估。以下是优点和缺点。
好处
-
只读表的高可用性
-
过时读取的高可用性
-
能够进行非常低延迟的读取,具有非常高的百分位数(99.9%+)延迟读取的延迟
缺点
-
具有区域复制的表的双/三 MemStore 使用(取决于区域复制计数)&gt; 1
-
增加块缓存使用率
-
日志复制的额外网络流量
-
副本的额外备份 RPC
为了从多个副本服务区域数据,HBase 在区域服务器中以辅助模式打开区域。以辅助模式打开的区域将与主要区域副本共享相同的数据文件,但是每个辅助区域副本将具有其自己的 MemStore 以保留未刷新的数据(仅主要区域可以执行刷新)。同样为了提供来自次要区域的读取,数据文件块也可以高速缓存在用于次要区域的块高速缓存中。
75.4。代码在哪里?
此功能分两个阶段提供,第 1 阶段和第 2 阶段。第一阶段及时完成 HBase-1.0.0 版本。这意味着使用 HBase-1.0.x,您可以使用为阶段 1 标记的所有功能。阶段 2 在 HBase-1.1.0 中提交,这意味着 1.1.0 之后的所有 HBase 版本都应包含阶段 2 项。
75.5。传播对区域副本的写入
如上所述,写入仅转到主要区域副本。为了将写入从主要区域副本传播到辅助副本,有两种不同的机制。对于只读表,您不需要使用以下任何方法。禁用和启用表应使所有区域副本中的数据可用。对于可变表,您必须仅使用以下机制之一:storefile refresher 或 async wal replication。推荐后者。
75.5.1。 StoreFile 复习
第一种机制是存储文件刷新,它在 HBase-1.0 +中引入。存储文件刷新是每个区域服务器的一个线程,它定期运行,并对辅助区域副本的主区域的存储文件执行刷新操作。如果启用,则刷新器将确保辅助区域副本及时查看来自主区域的新刷新,压缩或批量加载文件。但是,这意味着只能从辅助区域副本中读回刷新的数据,并且在刷新运行之后,使辅助数据库滞后于主数据库更长时间。
要打开此功能,应将hbase.regionserver.storefile.refresh.period配置为非零值。请参阅下面的配置部分
75.5.2。 Asnyc WAL 复制
第二种写入传播的机制是通过“异步 WAL 复制”功能完成的,仅在 HBase-1.1 +中可用。这类似于 HBase 的多数据中心复制,但是来自区域的数据被复制到辅助区域。每个辅助副本始终以与主区域提交它们相同的顺序接收和观察写入。从某种意义上说,这种设计可以被认为是“群集内复制”,而不是复制到不同的数据中心,数据会转到次要区域,以保持次要区域的内存状态为最新状态。数据文件在主区域和其他副本之间共享,因此不会产生额外的存储开销。但是,辅助区域将在其存储库中具有最近的非刷新数据,这会增加内存开销。主要区域也将 flush,compaction 和 bulk load 事件写入其 WAL,这些事件也通过 wal 复制到辅助节点进行复制。当他们观察到 flush / compaction 或 bulk load 事件时,辅助区域会重放事件以获取新文件并删除旧文件。
以与主数据库相同的顺序提交写入可确保辅助数据不会偏离主要区域数据,但由于日志复制是异步的,因此数据在辅助区域中可能仍然是陈旧的。由于此功能可用作复制端点,因此预计性能和延迟特性与群集间复制类似。
默认情况下,异步 WAL 复制禁用。您可以通过将hbase.region.replica.replication.enabled设置为true来启用此功能。当您使用区域复制&gt;创建表时,Asyn WAL 复制功能将添加名为region_replica_replication的新复制对等体作为复制对等体。 1 是第一次。启用后,如果要禁用此功能,则需要执行两项操作:_ 在hbase-site.xml中将配置属性hbase.region.replica.replication.enabled设置为 false(请参阅下面的配置部分)_ 禁用名为region_replica_replication的复制对等体在使用 hbase shell 或Admin类的集群中:
hbase> disable_peer 'region_replica_replication'
75.6。存储文件 TTL
在上面提到的两种写传播方法中,主存储文件将在辅助节点中独立于主区域打开。因此,对于主要压缩的文件,辅助节点可能仍然会引用这些文件进行读取。这两个功能都使用 HFileLinks 来引用文件,但是没有保护(尚未)保证文件不会过早删除。因此,作为保护,您应该将配置属性hbase.master.hfilecleaner.ttl设置为更大的值,例如 1 小时,以保证您不会收到转发到副本的请求的 IOExceptions。
75.7。 META 表区域的区域复制
目前,没有为 META 表的 WAL 执行异步 WAL 复制。元表的辅助副本仍然会从持久存储文件中刷新自己。因此,需要将hbase.regionserver.meta.storefile.refresh.period设置为某个非零值以刷新元存储文件。请注意,此配置的配置与hbase.regionserver.storefile.refresh.period不同。
75.8。记忆核算
辅助区域副本引用主要区域副本的数据文件,但它们有自己的存储库(在 HBase-1.1 +中)并且也使用块缓存。但是,一个区别是次要区域副本在其存储器存在压力时无法刷新数据。它们只能在主区域执行刷新时释放 memstore 内存,并且此刷新将复制到辅助节点。由于在某些区域中托管主副本的区域服务器和其他区域的辅助副本,因此辅助副本可能会导致额外刷新到同一主机中的主区域。在极端情况下,没有内存可用于添加来自主要来自 wal 复制的新写入。为了解除阻塞这种情况(并且由于辅助服务器不能自行刷新),允许辅助服务器通过执行文件系统列表操作来执行“存储文件刷新”,以从主服务器获取新文件,并可能删除其 memstore。仅当最大辅助区域副本的 memstore 大小至少比主副本的最大 memstore 大hbase.region.replica.storefile.refresh.memstore.multiplier(默认值为 4)时,才会执行此刷新。需要注意的是,如果执行此操作,则辅助节点可以观察跨列族的部分行更新(因为列族是独立刷新的)。默认情况下应该不经常执行此操作。如果需要,可以将此值设置为较大的数值以禁用此功能,但请注意,它可能会导致复制永久阻止。
75.9。辅助副本故障转移
当辅助区域副本首次联机或故障转移时,它可能已从其 memstore 中进行了一些编辑。由于辅助副本的恢复处理方式不同,因此辅助副本必须确保它在分配后开始提供请求之前不会及时返回。为此,辅助节点等待直到它观察到从主节点复制的完全刷新周期(开始刷新,提交刷新)或“区域打开事件”。在此情况发生之前,辅助区域副本将通过抛出 IOException 来拒绝所有读取请求,并显示消息“区域的读取被禁用”。但是,其他副本可能仍然可以读取,因此不会对具有 TIMELINE 一致性的 rpc 造成任何影响。为了促进更快的恢复,辅助区域将在打开时触发主要的刷新请求。如果需要,配置属性hbase.region.replica.wait.for.primary.flush(默认启用)可用于禁用此功能。
75.10。配置属性
要使用高可用性读取,应在hbase-site.xml文件中设置以下属性。没有用于启用或禁用区域副本的特定配置。相反,您可以在创建表时或使用 alter table 更改每个表的区域副本数量以增加或减少。以下配置用于使用异步 wal 复制和使用 3 的元副本。
75.10.1。服务器端属性
<property>
<name>hbase.regionserver.storefile.refresh.period</name>
<value>0</value>
<description>
The period (in milliseconds) for refreshing the store files for the secondary regions. 0 means this feature is disabled. Secondary regions sees new files (from flushes and compactions) from primary once the secondary region refreshes the list of files in the region (there is no notification mechanism). But too frequent refreshes might cause extra Namenode pressure. If the files cannot be refreshed for longer than HFile TTL (hbase.master.hfilecleaner.ttl) the requests are rejected. Configuring HFile TTL to a larger value is also recommended with this setting.
</description>
</property>
<property>
<name>hbase.regionserver.meta.storefile.refresh.period</name>
<value>300000</value>
<description>
The period (in milliseconds) for refreshing the store files for the hbase:meta tables secondary regions. 0 means this feature is disabled. Secondary regions sees new files (from flushes and compactions) from primary once the secondary region refreshes the list of files in the region (there is no notification mechanism). But too frequent refreshes might cause extra Namenode pressure. If the files cannot be refreshed for longer than HFile TTL (hbase.master.hfilecleaner.ttl) the requests are rejected. Configuring HFile TTL to a larger value is also recommended with this setting. This should be a non-zero number if meta replicas are enabled (via hbase.meta.replica.count set to greater than 1).
</description>
</property>
<property>
<name>hbase.region.replica.replication.enabled</name>
<value>true</value>
<description>
Whether asynchronous WAL replication to the secondary region replicas is enabled or not. If this is enabled, a replication peer named "region_replica_replication" will be created which will tail the logs and replicate the mutations to region replicas for tables that have region replication > 1\. If this is enabled once, disabling this replication also requires disabling the replication peer using shell or Admin java class. Replication to secondary region replicas works over standard inter-cluster replication.
</description>
</property>
<property>
<name>hbase.region.replica.replication.memstore.enabled</name>
<value>true</value>
<description>
If you set this to `false`, replicas do not receive memstore updates from
the primary RegionServer. If you set this to `true`, you can still disable
memstore replication on a per-table basis, by setting the table's
`REGION_MEMSTORE_REPLICATION` configuration property to `false`. If
memstore replication is disabled, the secondaries will only receive
updates for events like flushes and bulkloads, and will not have access to
data which the primary has not yet flushed. This preserves the guarantee
of row-level consistency, even when the read requests `Consistency.TIMELINE`.
</description>
</property>
<property>
<name>hbase.master.hfilecleaner.ttl</name>
<value>3600000</value>
<description>
The period (in milliseconds) to keep store files in the archive folder before deleting them from the file system.</description>
</property>
<property>
<name>hbase.meta.replica.count</name>
<value>3</value>
<description>
Region replication count for the meta regions. Defaults to 1.
</description>
</property>
<property>
<name>hbase.region.replica.storefile.refresh.memstore.multiplier</name>
<value>4</value>
<description>
The multiplier for a “store file refresh” operation for the secondary region replica. If a region server has memory pressure, the secondary region will refresh it’s store files if the memstore size of the biggest secondary replica is bigger this many times than the memstore size of the biggest primary replica. Set this to a very big value to disable this feature (not recommended).
</description>
</property>
<property>
<name>hbase.region.replica.wait.for.primary.flush</name>
<value>true</value>
<description>
Whether to wait for observing a full flush cycle from the primary before start serving data in a secondary. Disabling this might cause the secondary region replicas to go back in time for reads between region movements.
</description>
</property>
还要记住的一点是,区域副本放置策略仅由作为默认平衡器的StochasticLoadBalancer强制执行。如果在 hbase-site.xml(hbase.master.loadbalancer.class中)使用自定义负载均衡器属性,则区域的副本最终可能会托管在同一服务器中。
75.10.2。客户端属性
确保为将使用区域副本的所有客户端(和服务器)设置以下内容。
<property>
<name>hbase.ipc.client.specificThreadForWriting</name>
<value>true</value>
<description>
Whether to enable interruption of RPC threads at the client side. This is required for region replicas with fallback RPC’s to secondary regions.
</description>
</property>
<property>
<name>hbase.client.primaryCallTimeout.get</name>
<value>10000</value>
<description>
The timeout (in microseconds), before secondary fallback RPC’s are submitted for get requests with Consistency.TIMELINE to the secondary replicas of the regions. Defaults to 10ms. Setting this lower will increase the number of RPC’s, but will lower the p99 latencies.
</description>
</property>
<property>
<name>hbase.client.primaryCallTimeout.multiget</name>
<value>10000</value>
<description>
The timeout (in microseconds), before secondary fallback RPC’s are submitted for multi-get requests (Table.get(List<Get>)) with Consistency.TIMELINE to the secondary replicas of the regions. Defaults to 10ms. Setting this lower will increase the number of RPC’s, but will lower the p99 latencies.
</description>
</property>
<property>
<name>hbase.client.replicaCallTimeout.scan</name>
<value>1000000</value>
<description>
The timeout (in microseconds), before secondary fallback RPC’s are submitted for scan requests with Consistency.TIMELINE to the secondary replicas of the regions. Defaults to 1 sec. Setting this lower will increase the number of RPC’s, but will lower the p99 latencies.
</description>
</property>
<property>
<name>hbase.meta.replicas.use</name>
<value>true</value>
<description>
Whether to use meta table replicas or not. Default is false.
</description>
</property>
注意 HBase-1.0.x 用户应该使用hbase.ipc.client.allowsInterrupt而不是hbase.ipc.client.specificThreadForWriting。
75.11。用户界面
在主用户界面中,表的区域副本也与主要区域一起显示。您可以注意到区域的副本将共享相同的开始和结束键以及相同的区域名称前缀。唯一的区别是附加的 replica_id(编码为十六进制),区域编码的名称将不同。您还可以在 UI 中看到显式显示的副本 ID。
75.12。创建具有区域复制的表
区域复制是每个表的属性。默认情况下,所有表都有REGION_REPLICATION = 1,这意味着每个区域只有一个副本。您可以通过在表描述符中提供REGION_REPLICATION属性来设置和更改表的每个区域的副本数。
75.12.1。贝壳
create 't1', 'f1', {REGION_REPLICATION => 2}
describe 't1'
for i in 1..100
put 't1', "r#{i}", 'f1:c1', i
end
flush 't1'
75.12.2。 Java 的
HTableDescriptor htd = new HTableDescriptor(TableName.valueOf(“test_table”));
htd.setRegionReplication(2);
...
admin.createTable(htd);
您还可以使用setRegionReplication()和 alter table 来增加,减少表的区域复制。
75.13。阅读 API 和用法
75.13.1。贝壳
您可以使用 Consistency.TIMELINE 语义在 shell 中进行读取,如下所示
hbase(main):001:0> get 't1','r6', {CONSISTENCY => "TIMELINE"}
您可以模拟暂停或变为不可用的区域服务器,并从辅助副本执行读取操作:
$ kill -STOP <pid or primary region server>
hbase(main):001:0> get 't1','r6', {CONSISTENCY => "TIMELINE"}
使用扫描也是类似的
hbase> scan 't1', {CONSISTENCY => 'TIMELINE'}
75.13.2。 Java 的
您可以按如下方式设置获取和扫描的一致性并执行请求。
Get get = new Get(row);
get.setConsistency(Consistency.TIMELINE);
...
Result result = table.get(get);
您还可以传递多个获取:
Get get1 = new Get(row);
get1.setConsistency(Consistency.TIMELINE);
...
ArrayList<Get> gets = new ArrayList<Get>();
gets.add(get1);
...
Result[] results = table.get(gets);
和扫描:
Scan scan = new Scan();
scan.setConsistency(Consistency.TIMELINE);
...
ResultScanner scanner = table.getScanner(scan);
您可以通过调用Result.isStale()方法检查结果是否来自主区域:
Result result = table.get(get);
if (result.isStale()) {
...
}
75.14。资源
-
有关设计和实施的更多信息,请参阅 jira 问题: HBASE-10070
-
HBaseCon 2014 讲话: HBase 使用时间轴一致区域副本读取高可用性还包含一些细节和幻灯片。
76.存储中型物体(MOB)
数据有多种尺寸,保存 HBase 中的所有数据(包括图像和文档等二进制数据)是理想的选择。虽然 HBase 在技术上可以处理大小超过 100 KB 的单元格的二进制对象,但 HBase 的正常读取和写入路径针对小于 100KB 的值进行了优化。当 HBase 处理超过此阈值的大量对象(此处称为中等对象或 MOB)时,由于分割和压缩引起的写入放大,性能会降低。使用 MOB 时,理想情况下,您的对象将介于 100KB 和 10MB 之间(参见 FAQ )。 HBase **FIX_VERSION_NUMBER **增加了对更好地管理大量 MOB 的支持,同时保持了性能,一致性和低运营开销。 MOB 支持由 HBASE-11339 完成的工作提供。要利用 MOB,您需要使用 HFile 版本 3 。 (可选)为每个 RegionServer 配置 MOB 文件读取器的缓存设置(请参阅配置 MOB 缓存),然后配置特定列以保存 MOB 数据。客户端代码无需更改即可利用 HBase MOB 支持。该功能对客户端是透明的。
MOB 压缩
在 MemStore 刷新后,MOB 数据被刷新到 MOB 文件中。一段时间后会有很多 MOB 文件。为了减少 MOB 文件数量,有一个周期性任务可以将小型 MOB 文件压缩成大型 MOB 文件(MOB 压缩)。
76.1。为 MOB 配置列
您可以在表创建或更改期间配置列以支持 MOB,无论是在 HBase Shell 中还是通过 Java API。两个相关的属性是布尔IS_MOB和MOB_THRESHOLD,它是一个对象被认为是 MOB 的字节数。只需要IS_MOB。如果未指定MOB_THRESHOLD,则使用默认阈值 100 KB。
使用 HBase Shell 为 MOB 配置列
hbase> create 't1', {NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 102400}
hbase> alter 't1', {NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 102400}
示例 23.使用 Java API 为 MOB 配置列
...
HColumnDescriptor hcd = new HColumnDescriptor(“f”);
hcd.setMobEnabled(true);
...
hcd.setMobThreshold(102400L);
...
76.2。配置 MOB 压缩策略
默认情况下,将特定日期的 MOB 文件压缩为一个大型 MOB 文件。为了更多地减少 MOB 文件数,还支持其他 MOB 压缩策略。
每日策略 - 压缩 MOB 文件一天进入一个大型 MOB 文件(默认策略)每周策略 - 紧凑 MOB 文件一周到一个大型 MOB 文件 montly 策略 - 紧凑 MOB 文件一个月到一个大 MOB 文件
使用 HBase Shell 配置 MOB 压缩策略
hbase> create 't1', {NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 102400, MOB_COMPACT_PARTITION_POLICY => 'daily'}
hbase> create 't1', {NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 102400, MOB_COMPACT_PARTITION_POLICY => 'weekly'}
hbase> create 't1', {NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 102400, MOB_COMPACT_PARTITION_POLICY => 'monthly'}
hbase> alter 't1', {NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 102400, MOB_COMPACT_PARTITION_POLICY => 'daily'}
hbase> alter 't1', {NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 102400, MOB_COMPACT_PARTITION_POLICY => 'weekly'}
hbase> alter 't1', {NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 102400, MOB_COMPACT_PARTITION_POLICY => 'monthly'}
76.3。配置 MOB 压缩可合并阈值
如果一个 mob 文件的大小小于这个值,它被认为是一个小文件,需要在 mob compaction 中合并。默认值为 1280MB。
<property>
<name>hbase.mob.compaction.mergeable.threshold</name>
<value>10000000000</value>
</property>
76.4。测试 MOB
提供实用程序org.apache.hadoop.hbase.IntegrationTestIngestWithMOB以帮助测试 MOB 功能。该实用程序运行如下:
$ sudo -u hbase hbase org.apache.hadoop.hbase.IntegrationTestIngestWithMOB \
-threshold 1024 \
-minMobDataSize 512 \
-maxMobDataSize 5120
-
**threshold**是细胞被认为是 MOB 的阈值。默认值为 1 kB,以字节为单位表示。 -
**minMobDataSize**是 MOB 数据大小的最小值。默认值为 512 B,以字节为单位表示。 -
**maxMobDataSize**是 MOB 数据大小的最大值。默认值为 5 kB,以字节为单位表示。
76.5。配置 MOB 缓存
因为可以随时存在大量 MOB 文件,与 HFiles 的数量相比,MOB 文件并不总是保持打开状态。 MOB 文件读取器缓存是一个 LRU 缓存,它保持最近使用的 MOB 文件打开。要在每个 RegionServer 上配置 MOB 文件读取器的缓存,请将以下属性添加到 RegionServer 的hbase-site.xml,自定义配置以适合您的环境,然后重新启动或滚动重新启动 RegionServer。
示例 24.示例 MOB 缓存配置
<property>
<name>hbase.mob.file.cache.size</name>
<value>1000</value>
<description>
Number of opened file handlers to cache.
A larger value will benefit reads by providing more file handlers per mob
file cache and would reduce frequent file opening and closing.
However, if this is set too high, this could lead to a "too many opened file handers"
The default value is 1000.
</description>
</property>
<property>
<name>hbase.mob.cache.evict.period</name>
<value>3600</value>
<description>
The amount of time in seconds after which an unused file is evicted from the
MOB cache. The default value is 3600 seconds.
</description>
</property>
<property>
<name>hbase.mob.cache.evict.remain.ratio</name>
<value>0.5f</value>
<description>
A multiplier (between 0.0 and 1.0), which determines how many files remain cached
after the threshold of files that remains cached after a cache eviction occurs
which is triggered by reaching the `hbase.mob.file.cache.size` threshold.
The default value is 0.5f, which means that half the files (the least-recently-used
ones) are evicted.
</description>
</property>
76.6。 MOB 优化任务
76.6.1。手动压缩 MOB 文件
要手动压缩 MOB 文件,而不是等待配置触发压缩,请使用compact或major_compact HBase shell 命令。这些命令要求第一个参数为表名,并将列族作为第二个参数。并将压缩类型作为第三个参数。
hbase> compact 't1', 'c1’, ‘MOB’
hbase> major_compact 't1', 'c1’, ‘MOB’
这些命令也可通过Admin.compact和Admin.majorCompact方法获得。