
保证消息处理
Storm 通过 Trident 对保证消息处理提供了不同的 level ,包括 best effort(尽力而为),at least once (至少一次)和exactly once(至少一次). 这张页面描述如何保证至少处理一次.
What does it mean for a message to be "fully processed"?(一条信息被完全处理是什么意思)
一个 tuple 从 spout 流出,可能会导致数以千计的 tuple 被创建.例如,下面 streaming word count的 topology(拓扑):
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("sentences", new KestrelSpout("kestrel.backtype.com",
22133,
"sentence_queue",
new StringScheme()));
builder.setBolt("split", new SplitSentence(), 10)
.shuffleGrouping("sentences");
builder.setBolt("count", new WordCount(), 20)
.fieldsGrouping("split", new Fields("word"));
这个topology从 Kestrel queue 读取一行行的句子, 将句子按照空格分割成一个个的单词,然后再发送之前计算的单词数量. 从 Spout 中流出的一个tuple 会触发创建许多 tuples: 一个tuple 对应句子的中 word,一个tuple对应每个 word 的 count。消息树像下面这样:
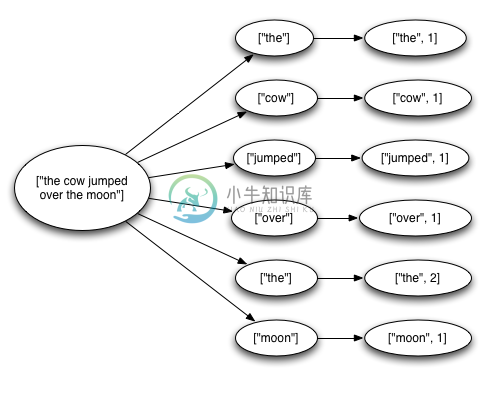
当 tuple tree 用完后且每个在 tree中的消息都被处理后,Storm 就认为从 spout 流出的 tuple 被完全处理了.
当一个 tuple tree 没有在特定的时间内完全处理,tuple就被认为是失败的。可以在指定的 topology(拓扑)上使用 Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS 来配置这个超时时间,并且默认为30秒。
What happens if a message is fully processed or fails to be fully processed?(如果消息完全处理或未能完全处理,会发生什么)
为了理解这个问题,我们来看一下 tuple 从 spout 流出后的声明周期。作为参考,这里是spouts实现的接口 (有关更多信息,请参阅J Javadoc ):
public interface ISpout extends Serializable {
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
void close();
void nextTuple();
void ack(Object msgId);
void fail(Object msgId);
}
首先 Storm 请求一个 Spout 中的 tuple,使用 Spout 中的 nextTuple 方法. Spout 使用 SpoutOutputCollector 提供的 open 方法,发送 tuple 输出到 output streams的其中一个.当发送 tuple 的时候, Spout 会提供一个 "message id",用于以后标识 tuple .例如,KestrelSpout 从kestrel queue中读取消息,在发送消息的时候会提供一个 "message id"。发送一个 message 到 SpoutOutputCollector 像下面这样:
_collector.emit(new Values("field1", "field2", 3) , msgId);
下一步,tuple被发送到消费的 bolts中,Storm 开始监控创建的 the tree of messages。如果 Storm 检测到 tuple被完全处理,Storm 会在原来的 Spout 上根据message id 调用 ack 方法.同样的,如果处理 tuple超时了,Storm会调用在 Spout 上调用 fail 方法.由于 tuple ack或者fail,都原来创建这个tuple 的 Spout task调用.所以如果一个 Spout 在集群上运行很多任务,tuple 不会被多个 Spout 任务 acked 或者 failed.
我们再通过 KestrelSpout 来看看 Spout 需要保证消息处理那些情况.当 KestrelSpout 从 Kestrel queue中读取消息的时候,它只是 "open" 了message.这意味着消息并没有真正从队列出来,而是处于一种 “pending” 状态,承认message 已经完成.在这种 pending 状态的时候,message不会将消息发送到队列的其他用 consumer.此外,如果客户端断开所有 pending 状态的消息,那么客户端将把消息放回到队列.当一条 message opened后,Kestrel 向客户端提供消息,并提供一个唯一性的id标识消息. 当发送 tuple 到 SpoutOutputCollector的时候,就用Kestrel 提供的id 作为 “message id”。当 KestrelSpout 调用 ack或者fail的时候,KestrelSpout会向Kestrel 发送一条ack 或者 fail消息,包括 message id,以让Kestrel 将消息从队列中取出,或者放回去.
What is Storm's reliability API?
用户想要保证Storm的可靠性,需要做两件事.第一,当你在 tuple tree 中创建新的 link 的时候,你需要告诉 Storm.第二,当你处理完一个独立的 tuple,也需要告诉Storm。 做到这两件事情,Storm可以检测到 tree of tuples 什么时候完全处理了,并且可以适当的 ack 或者 fail spout tuples。Storm 的API提供了一个简单的方法来完成这两项任务.
在 tuple tree中指定一个link 的方法叫做 anchoring. 当你发送一个新的 tuple 的时候就会执行 Anchoring 操作.我们使用下面的 bolt 作为一个例子.这个 bolt 将句子 tuple 分割成一个个 word tuple.
public class SplitSentence extends BaseRichBolt {
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
_collector.emit(tuple, new Values(word));
}
_collector.ack(tuple);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
通过指定输入 tuple 作为emit 的第一个参数,每一个word tuple 就会被 anchored.由于 word tuple 被 anchor,如果 word tuple 下游处理失败,tuple tree 的根节点会重新处理.相比之下,我们看一下 word tuple像下面这样发送.
_collector.emit(new Values(word));
这种方式发送 word tuple 会导致 unanchored. 如果tuple在处理下游的时候失败,根节点的 tuple不会重新处理.根据你的 topology(拓扑)需要来保证容错保证,有时候发送一个 unanchored tuple 也比较适合.
输出的tuple可以 anchor 多个input tuple,当join和聚合的时候,这是比较有用的.一个 multi-anchored 的tuple处理失败后,多个tuple都会被重新处理.通过指定一系列 tuples,而不是单个tuple来完成 Multi-anchoring.例如:
List<Tuple> anchors = new ArrayList<Tuple>();
anchors.add(tuple1);
anchors.add(tuple2);
_collector.emit(anchors, new Values(1, 2, 3));
Multi-anchoring 会添加 output tuple 到 multiple tuple trees.这就可能会破坏树形结构,创建了tuple DAGs,像这样:
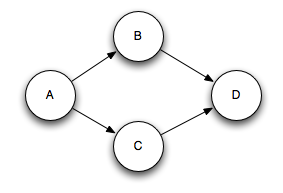
Storm 的实现适用于DAG和树(pre-release 只适用于trees,称为“tuple tree”)
Anchoring 是你如何指定 tuple tree的方式--在Storm可靠性 API 在 tuple tree中完成一个tuple后,会执行下一部分的处理. 在OutputCollector上使用ack和fail方法的时候来完成.如果你回顾了SplitSentence例子,你可以看到当所有的word tuple发送出去后,input tuple会被ack.
你可以使用 OutputCollector 的 fail 方法,立即设置 tuple tree的根节点spout tuple为失败状态.例如,你的应用可能数据库异常,需要显式的 fail input tuple。通过显式的failing,spout tuple 可以比等待tuple超时速度更快.
你处理的每个tuple 必须acked或者failed.Storm使用内存监控每个tuple,所以如果你必须fail或者ack每个tuple,这个任务最终会out of memory.
许多bolts都会像下面这种模式读取 input tuple,发送 tuples.在 execute 方法结束后acking tuple。bolts 有过滤或者一些简单的功能.Storm有一个接口叫做BasicBolt,可以封装这些模式.SplitSentence示例可以写成BasicBolt,如下所示:
public class SplitSentence extends BaseBasicBolt {
public void execute(Tuple tuple, BasicOutputCollector collector) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
collector.emit(new Values(word));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
该实现比以前的实现更简单,语义上相同。发送到 BasicOutputCollector 的 tuple 将自动 anchor 到输入元组,并且在执行方法完成时自动acked。
相比之下,执行聚合或join的bolt可能会延迟ack input tuple。聚合和join会多重anchor output tuples。这些事情不在 IBasicBolt 的简单模式之上.
How do I make my applications work correctly given that tuples can be replayed?(如果重新处理 tuples,我如何使我的应用程序正常工作?)
与软件设计一样,答案是“depend”。如果你真的想要使用 Trident 保证 exactly once 语义.在某些情况下,像许多分析行为一样,丢弃数据是允许的,所以通过设置 ackers bolts 数量为0 Config.TOPOLOGY_ACKERS ,来禁用容错.但在某些情况下,你想要确保所有的 tuple 至少处理一次,没有任何内容被丢弃.This is especially useful if all operations are idenpotent or if deduping can happen aferwards.(废话可以不看)
How does Storm implement reliability in an efficient way?(Storm 如何以有效的方式实现可靠性?)
Storm 对于 Spout 的 tuple 都有一组特殊的 acker 任务用来跟踪 DAG tuples。当一个acker 任务看到一个 DAG 完成后,就会发送一个消息到到创建这个 spout tuple 的任务.你可以通过 Config.TOPOLOGY_ACKERS 来设置 acker tasks的数量.Storm TOPOLOGY_ACKERS 配置默认是一个worker 一个任务.
理解Storm 可靠性实现最好的方式就是看 tuple 和 tuple DAG的声明周期.当 topology中创建了一个 tuple,也可以在一个 spout或者bolt,会给予一个 64 bit 的id.这个id是 ackers用来跟踪 tuple DAG里的每个 spout tuple。
spout 中的每个 tuple 都知道他们id,并存在于 tuple tree中.当你发送一个新的 tuple 到bolt 的时候,来自于 tuple anchors(锚点)的spout tuple ids会被复制到新的 tuple.当一个tuple被ack后,就会发送一条消息到 acker tasks,告知 tuple tree应该如何改变. 实际上,告诉acker的是“我已经完成了tree中的这个 spout tuple ,这里是 tree中 anchored(锚定) 我的 tuples”。
例如, tuples D和E是基于 tuple C创建的,下面是当 tuple C 被acked后,tree是如何改变的.
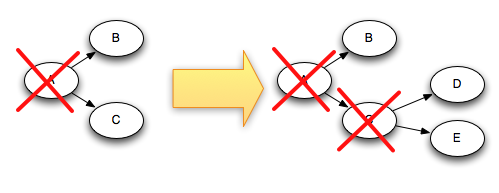
由于 tuple C 从 tree中移除的同时, tuple "D"和"E"都加入到tree中,所以 tree 永远不可能完成.
Storm 跟踪 tuple trees 有一些细节.如前面所述,你可以在 topology中定义任意数量的 acker 任务。这导致了以下问题:当一个元组在 topology 中被 acked后,它如何知道是哪个 acker 任务发送的该消息?
Storm 使用 mod hash的模式将spout tuple id映射到acker task.由于每一个tuple都会带有tree中id,所以他们知道和那个 acker task 进行通信.
Storm的另一个细节就是如何让 Acker 任务跟踪他们正在跟踪的每个 spout tuple的 spouts 任务。当一个spout任务发出一个新的元组时,它只需向相应的acker发送一条消息,告诉它它的任务id是负责这个新的元素的负责人。然后当acker看到树已经完成时,它知道要发送那个任务id。
Acker tasks 不会显式的跟踪 tuple trees。对于具有成千上万个节点(或者更多)的大型 tuple tree,跟踪所有的 tuple trees 会占用很多内存.相反,ackers采用不同的策略,只需要每个 spout tuple 固定空间(大约20字节).这种跟踪算法是Storm工作的关键,也是重大突破之一.
一个acker task 存储spout tuple id映射到一组值的map,第一个值是创建这个 spout tuple 的任务id.第二个值是称为 “ack val”的64位数. ack val 表示整个tuple tree的状态,无论多大或多小,它简化了在树中创建或者acked 的所有tuple ids 的xor.
当acker任务看到“ack val”已经变为0时,它知道元组树已经完成。由于 tuple ID是随机64位数,因此“ack val” 突然变为0的机会非常小。从数学角度来看,每秒10K acks,就要花5万年,直到出错。即使如此,如果该 tuple 在拓扑中发生故障,则只会导致数据丢失。
现在,您了解可靠性算法,让我们回顾一下所有故障情况,并了解如何在每种情况下避免数据丢失:
- 一个tuple没有acked,因为对应的任务挂掉: 在这种情况下,失败的元组会超时并重新处理.
- Acker 任务挂掉: 这种情况下acker 跟踪的所有的 spout tuples 都会超时并重新处理
- Spout 任务挂掉: 在这种情况下,spout 的来源负责重新播放消息.例如,当客户端断开连接时,像Kestrel和RabbitMQ这样的队列会将所有挂起的消息放回队列。
正如你所看到的,Storm的可靠性机制是完全分布式,可扩展的和容错的。
Tuning reliability(调整可靠性)
Acker任务是轻量级的,所以在 topology(拓扑)中您不需要非常多的任务。您可以通过Storm UI(组件ID“__acker”)跟踪其性能。如果吞吐量看起来不正确,则需要添加更多的acker任务.
如果可靠性对您不重要 -- 也就是说,您不关心在失败情况下丢失 tuple,那么您可以通过不跟踪 tuple tree来提高性能。没有跟踪tuple tree 将传递的消息数量减少一半,因为正常情况下,tuple tree 中的每个tuple都有一个确认消息。另外,它需要更少的id来保存在每个下游 tuple 中,从而减少带宽使用。
有三种方法来消除可靠性。第一个是将Config.TOPOLOGY_ACKERS设置为0.在这种情况下,Storm会在 spout 发出一个tuple 后立即在 spout 上调用ack方法。元组树不会被跟踪。
第二种方法是通过消息消除消息的可靠性。您可以通过省略SpoutOutputCollector.emit方法中的消息标识来关闭单个 spout tuple 的跟踪。
最后,如果您不关心topology(拓扑)中下游的tuple的特定子集是否被处理,则可以将其作为无保留的 tuple发出。由于它们没有被锚定到任何 spout tuple,所以如果没有出现,它们不会导致任何 spout tuple失败。