
08-Docker安装常用软件

Docker 安装 Mysql
以安装 Mysql 5.7为例:
docker pull mysql:5.7
Mysql 单机
Mysql 5.7安装
启动 Mysql 容器,并配置容器卷映射:
docker run -d -p 3306:3306 \
--privileged=true \
-v /app/mysql/log:/var/log/mysql \
-v /app/mysql/data:/var/lib/mysql \
-v /app/mysql/conf:/etc/mysql/conf \
-e MYSQL_ROOT_PASSWORD=root \
--name mysql \
mysql:5.7
参数说明:
-d -> 后台运行容器并返回容器ID,即启动守护式容器
-p 3306:3306 -> (宿主机端口 : 容器内软件端口)将容器的端口映射到主机的端口
-e -> 为容器添加环境变量
-v 容器挂载
-name 起名
在/app/mysql/conf下新建 my.cnf,通过容器卷同步给mysql实例,解决中文乱码问题:
[client]
default_character_set=utf8
[mysqld]
collation_server = utf8_general_ci
character_set_server = utf8
重启mysql容器,使得容器重新加载配置文件:
docker restart mysql
此时便解决了中文乱码(中文插入报错)问题。
而且因为启动时将容器做了容器卷映射,将mysql的配置(映射到/app/mysql/conf)、数据(映射到/app/mysql/data)、日志(映射到/app/mysql/log)都映射到了宿主机实际目录,所以即使删除了容器,也不会产生太大影响。只需要再执行一下启动Mysql容器命令,容器卷还按相同位置进行映射,所有的数据便都可以正常恢复。
Mysql 主从复制安装
安装主服务器容器实例(端口号3307):
- 启动容器实例
docker run -p 3307:3306 \
--name mysql-master \
--privileged=true \
-v /app/mysql-master/log:/var/log/mysql \
-v /app/mysql-master/data:/var/lib/mysql \
-v /app/mysql-master/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
- 进入
/app/mysql-master/conf,新建my.cnf配置文件:
[mysqld]
## 设置server_id, 同一个局域网中需要唯一
server_id=101
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能
log-bin=mall-mysql-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
- 重启容器实例
docker restart mysql-master
- 进入容器实例内
docker exec -it mysql-master /bin/bash
- 登录mysql,创建数据同步用户
-- 首先使用 mysql -uroot -p 登录mysql
-- 创建数据同步用户
create user 'slave'@'%' identified by '123456';
-- 授权
grant replication slave, replication client on *.* to 'slave'@'%';
flush privileges;
安装从服务器容器实例(端口号3308):
- 启动容器服务:
docker run -p 3308:3306 \
--name mysql-slave \
--privileged=true \
-v /app/mysql-slave/log:/var/log/mysql \
-v /app/mysql-slave/data:/var/lib/mysql \
-v /app/mysql-slave/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
- 进入
/app/mysql-slave/conf目录,创建my.cnf配置文件:
[mysqld]
## 设置server_id, 同一个局域网内需要唯一
server_id=102
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能,以备slave作为其它数据库实例的Master时使用
log-bin=mall-mysql-slave1-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断
## 如:1062错误是指一些主键重复,1032是因为主从数据库数据不一致
slave_skip_errors=1062
## relay_log配置中继日志
relay_log=mall-mysql-relay-bin
## log_slave_updates表示slave将复制事件写进自己的二进制日志
log_slave_updates=1
## slave设置只读(具有super权限的用户除外)
read_only=1
- 修改完配置需要重启slave容器实例
docker restart mysql-slave
在主数据库中查看主从同步状态:
- 进入主数据库容器:
docker exec -it mysql-master /bin/bash
- 进入Mysql
mysql -uroot -p
- 查看主从同步状态
show master status;
主要查看返回结果的文件名File、当前位置Position
进入从数据库容器,配置主从复制:
- 进入从数据库容器:
docker exec -it mysql-slave /bin/bash
- 进入数据库
mysql -uroot -p
- 配置从数据库所属的主数据库:
-- 格式:
-- change master to master_host='宿主机ip',master_user='主数据库配置的主从复制用户名',master_password='主数据库配置的主从复制用户密码',master_port=宿主机主数据库端口,master_log_file='主数据库主从同步状态的文件名File',master_log_pos=主数据库主从同步状态的Position,master_connect_retry=连接失败重试时间间隔(秒);
change master to master_host='192.168.xxx.xxx',master_user='slave',master_password='123456',master_port=3307,master_log_file='mall-mysql-bin.000001',master_log_pos=769,master_connect_retry=30;
- 查看主从同步状态:
# \G 可以将横向的结果集表格转换成纵向展示。
# slave status的字段比较多,纵向展示比友好
show slave status \G;
除了展示刚刚配置的主数据库信息外,主要关注 Slave_IO_Running、Slave_SQL_Running。目前两个值应该都为 No,表示还没有开始。
- 开启主从同步:
start slave;
- 再次查看主从同步状态,
Slave_IO_Running、Slave_SQL_Running都变为Yes。
主从复制测试:
- 在主数据库上新建库、使用库、新建表、插入数据
create database db01;
use db01;
create table t1 (id int, name varchar(20));
insert into t1 values (1, 'abc');
- 在从数据库上使用库、查看记录
show databases;
use db01;
select * from t1;
---------------------------------------------------
Docker安装Redis
以 Redis 6.0.8 为例:
docker pull redis:6.0.8
单机版安装
实际应用版Redis
配置文件、数据文件都和容器卷进行映射。
步骤:
- 宿主机创建目录
/app/redis - 在
/app/redis下创建文件redis.conf,主要修改以下几项配置
# 开启密码验证(可选)
requirepass snow
# 允许redis外地连接,需要注释掉绑定的IP
# bind 127.0.0.1
# 关闭保护模式(可选)
protected-mode no
# 注释掉daemonize yes,或者配置成 daemonize no。因为该配置和 docker run中的 -d 参数冲突,会导致容器一直启动失败
daemonize no
# 开启redis数据持久化, (可选)
appendonly yes
即最后的配置文件为:
- 启动docker容器:(因为要使用自定义的配置文件,所以需要指定容器运行的命令为
redis-server 容器内配置文件路径)
docker run -d -p 6379:6379 --name redis --privileged=true \
-v /app/redis/redis.conf:/etc/redis/redis.conf \
-v /app/redis/data:/data \
redis:6.0.8 \
redis-server /etc/redis/redis.conf
参数说明:
–privileged=true -> privileged关键字是docker 0.6版本中引入docker 使用该参数 container内的root拥有真正的root权限。 否则,container内的root只是外部的一个普通用户权限。
集群存储算法
分布式存储算法
分布式存储的常见算法:
- 哈希取余算法分区
- 一致性哈希算法分区
- 哈希槽算法分区
哈希取余算法
算法描述:hash(key) % N(其中,key是要存入Redis的键名,N是Redis集群的机器台数)。用户每次读写操作,都是根据传入的键名经过哈希运算,对机器台数取余决定该键存储在哪台服务器上。
优点:简单直接有效,只需要预估好数据规划好节点,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡+分而治之的作用。
缺点:原来规划好的节点,如果进行了扩容或者缩容,导致节点有变动,映射关系需要重新进行计算。在服务器个数固定不变时没问题,如果需要弹性扩容或者故障停机的情况下,原来取模公式中的 N就会发生变化,此时经过取模运算的结果就会发生很大变化,导致根据公式获取的服务器变得不可控。
一致性哈希算法
算法背景:一致性哈希算法是为了解决哈希取余算法中的分布式缓存数据变动和映射问题。当服务器个数发生变化时,尽量减少影响到客户端与服务器的映射关系。
算法描述:
一致性哈希算法必然有个hash函数并按照算法产生Hash值,这个算法的所有可能哈希值会构成一个全量集,这个集合可以成为一个Hash区间[0, 2^32 - 1],这是一个线性空间。但是在这个算法中,我们通过适当的逻辑控制将它首尾相连(0 = 2^32),这样让它逻辑上形成了一个环形空间。
它也是按照使用取模的方式。前面的哈希取余算法是对节点个数进行取模,而一致性哈希算法是对 2^32取模。
简单来说,一致性Hash算法将整个哈希值空间组成一个虚拟的圆环。如假设某个哈希函数H的值空间为 0到2^32 - 1(即哈希值是一个32位无符号整形),整个哈希环如下图:整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4…直到2^32 - 1,也就是说0点左侧的第一个点代表 2^32 - 1。0 和 2^32 - 1在零点钟方向重合,我们把这个由 2^32个点组成的圆环称为Hash环。

有了哈希环之后,还需要进行节点映射,将集群中各个IP节点映射到环上的某一个位置。
将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希。这样每台机器就能确定其在哈希环上的位置。
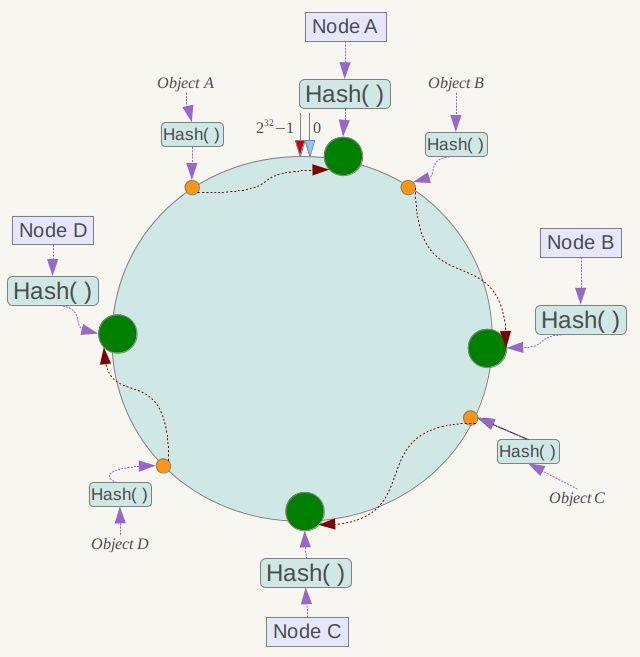
假如4个节点NodeA、B、C、D,经过IP地址的哈希函数计算(hash(ip)),使用IP地址哈希值后在环空间的位置如下:

key落到服务器的落键规则。当我们需要存储一个key键值对时,首先计算key的hash值(hash(key)),将这个key使用相同的函数hash,计算出哈希值并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储字该节点上。
假如我们有ObjectA、B、C、D四个数据对象,经过哈希计算后,在环空间上的位置如下:根据一致性hash算法,数据A会被定位到NodeA上,B被定位到NodeB上,C被定位到NodeC上,D被定位到NodeD上。
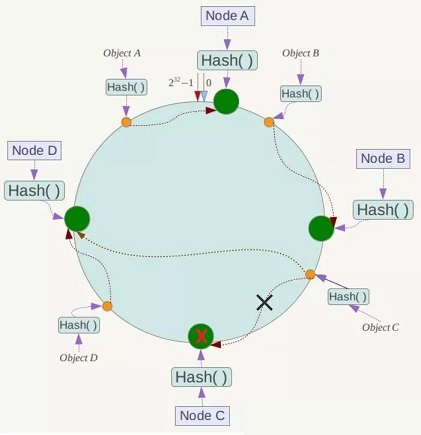
假设NodeC宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重新定位到NodeD。
一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间的数据,其他不会受到影响。
即:假设NodeC宕机,只会影响到Hash定位到NodeB到NodeC之间的数据,并且这些数据会被转移到NodeD进行存储。
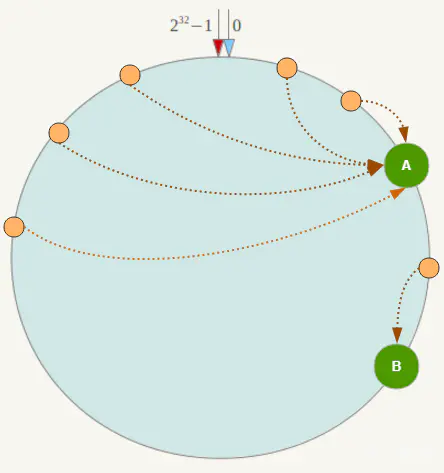
假如需要扩容增加一台节点NodeX,NodeX的hash(ip)位于NodeB和NodeC之间,那受到影响的就是NodeB 到 NodeX 之间的数据。重新将B到X的数据录入到X节点上即可,不会导致Hash取余全部数据重新洗牌的后果。

但是Hash环会存在数据倾斜问题。
一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象都集中到某一台或某几台服务器)。
为了解决数据倾斜问题,一致性哈希算法引入了虚拟节点机制。
对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以先确定每个物理节点关联的虚拟节点数量,然后在IP或主机名后面加上编号。
例如,可以对NodeA节点虚拟出 NodeA#1、NodeA#2、NodeA#3,对NodeB虚拟出NodeB#1、NodeB#2、NodeB#3的节点,形成六个虚拟节点。

优点:加入和删除节点时,只会影响哈希环中顺时针方向相邻节点,对其他节点无影响。
缺点:数据的分布和节点的位置有关,因为这些节点不是均匀分布在哈希环上的,所以在数据进行存储时达不到均匀部分的效果。
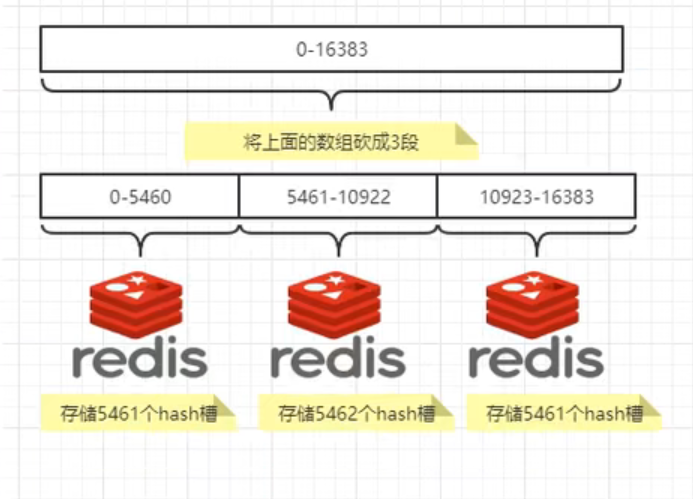
哈希槽分区
哈希槽分区是为了解决一致性哈希算法的数据倾斜问题。
哈希槽实质上就是一个数组,数组 [0, 2^14 - 1]形成的 hash slot空间。
目的是为了解决均匀分配的问题。在数据和节点之间又加入了一层,把这层称之为槽(slot),用于管理数据和节点之间的关系。就相当于节点上放的是槽,槽里面放的是数据。
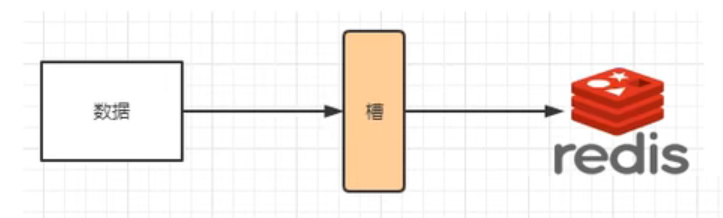
槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动。
哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配。
一个集群只能有 16394个槽,编号 0 - 16383(2^14 - 1)。这些槽会分配给集群中所有的主节点,分配策略没有要求。可以指定哪些编号的槽分配给哪个主节点,集群会记录节点和槽的对应关系。
解决了节点和槽的关系后,接下来就需要对key求哈希值,然后对16384取余,根据余数决定key落到哪个槽里。
slot = CRC16(key) % 16384
以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。
Redis集群存储策略
Redis集群使用的就是哈希槽。Redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置在哪个槽,集群的每个节点负责一部分hash槽。
哈希槽数量16384(2^14)的决定原因:
CRC16算法产生的hash值有 16bit,该算法可以产生 2^16 = 65536个值。但是为了心跳方便和数据传输最大化,槽的数量只能有 2^14个。
- 如果槽位数量为65535个,那么发送心跳信息的消息头将达到 8k,发送的心跳包过于庞大。在消息头中最占空间的是
myslots[CLUSTER_SLOTS/8]。当槽位为65536时,这块的大小是 :
65536 ÷ 8 ÷ 1024 = 8Kb
每秒中redis节点需要发送一定数量的ping消息作为心跳,如果槽位为65536,那么这个ping消息头就会太大浪费带宽。
- redis集群的主节点数量基本不可能超过1000个。集群节点越多,心跳包的消息体内携带的数据越多。如果节点超过1000个,也会导致网络拥堵。因此redis作者不建议redis cluster节点超过1000个。对于节点数在1000以内的redis cluster集群,16384个槽位足够了,没有必要扩展到65536个。
- 槽位越小,节点少的情况下压缩比越高,容易传输。Redis主节点的配置信息中它锁负责的哈希槽是通过一张bitmap的形式来保存的,在传输过程中会对bitmap进行压缩,但是如果bitmap的填充率
slots / N(N为节点数)很高的话,bitmap的压缩率就很低。如果节点数很少,而哈希槽数很多的话,bitmap的压缩率就很低。
原文:
正常的心跳数据包带有节点的完整配置,使得可以用幂等方式用旧的节点替换旧节点,以便更新旧的配置。这意味着它们包含原始节点的插槽配置,该节点使用 2k 的空间和 16k 的插槽,而不是使用 8k 的空间(使用65k的插槽)。
同时,因为其他设计折衷,Redis集群的主节点不太可能扩展到1000个以上
Redis集群中内置了16384个哈希槽,redis会根据节点数量大致均等的将哈希槽映射到不同的节点。当需要在Redis集群中放置一个Key-Value时,redis先对key使用 CRC16 算法算出一个结果,然后把结果对 16384 取余,这样每个key都会对应一个编号在0-16383之间的哈希槽,也就是映射到某个节点上。
@Test
public void test() {
// import io.lettuce.core.cluster.SlotHash;
System.out.println(SlotHash.getSlot('A')); // 计算结果6373,存入上图的Node2
System.out.println(SlotHash.getSlot('B')); // 计算结果10374,存入上图的Node2
System.out.println(SlotHash.getSlot('C')); // 计算结果14503,存入上图的Node3
System.out.println(SlotHash.getSlot('Hello')); // 计算结果866,存入上图的Node1
}
3主3从Redis集群
搭建
使用docker搭建3主3从的Redis集群,每台主机都对应一台从机。
启动6台redis容器
# 启动第1台节点
# --net host 使用宿主机的IP和端口,默认
# --cluster-enabled yes 开启redis集群
# --appendonly yes 开启redis持久化
# --port 6381 配置redis端口号
docker run -d --name redis-node-1 --net host --privileged=true -v /app/redis-cluster/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381
# 启动第2台节点
docker run -d --name redis-node-2 --net host --privileged=true -v /app/redis-cluster/share/redis-node-2:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382
# 启动第3台节点
docker run -d --name redis-node-3 --net host --privileged=true -v /app/redis-cluster/share/redis-node-3:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383
# 启动第4台节点
docker run -d --name redis-node-4 --net host --privileged=true -v /app/redis-cluster/share/redis-node-4:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384
# 启动第5台节点
docker run -d --name redis-node-5 --net host --privileged=true -v /app/redis-cluster/share/redis-node-5:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385
# 启动第6台节点
docker run -d --name redis-node-6 --net host --privileged=true -v /app/redis-cluster/share/redis-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386
构建主从关系:
- 进入节点1(或其中任意一个节点):
docker exec -it redis-node-1 /bin/bash
- 构建主从关系:
# 宿主机IP:端口
redis-cli --cluster create 192.168.xxx.xxx:6381 192.168.xxx.xxx:6382 192.168.xxx.xxx:6383 192.168.xxx.xxx:6384 192.168.xxx.xxx:6385 192.168.xxx.xxx:6386 --cluster-replicas 1
- redis尝试自动进行主从节点分配
- 因为我们的docker容器IP相同,所以会出现警告,可以直接忽略该警告
[WARNING] Some slaves are in the same host as their master
- redis自动分配结果完成后,需要输入
Yes确认配置信息:
M: f451eb48bbc0a7c31c7da022ffe80cc1696e0f37 192.168.xxx.xxx:6381
slots:[0-5460] (5461 slots) master
M: 05984211b8c38222a73abeff1d4e459c0fe1efbc 192.168.xxx.xxx:6382
slots:[5461-10922] (5462 slots) master
M: 1fc935c12b1d34a7df50aed643c195eb29bb3435 192.168.xxx.xxx:6383
slots:[10923-16383] (5461 slots) master
S: f8d0de47114bf33438747acd713cce4e412ae721 192.168.xxx.xxx:6384
replicates 1fc935c12b1d34a7df50aed643c195eb29bb3435
S: de0b393c17e452d856f6de2b348e9ca4e5aa4002 192.168.xxx.xxx:6385
replicates f451eb48bbc0a7c31c7da022ffe80cc1696e0f37
S: 0c0767e13a09ee48541738d4163592cd9842c143 192.168.xxx.xxx:6386
replicates 05984211b8c38222a73abeff1d4e459c0fe1efbc
Can I set the above configuration? (type 'yes' to accept):
- 输入
Yes确认后,redis会向其他节点发送信息加入集群,并分配哈希槽:
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.....
>>> Performing Cluster Check (using node 192.168.xxx.xxx:6381)
M: f451eb48bbc0a7c31c7da022ffe80cc1696e0f37 192.168.xxx.xxx:6381
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 1fc935c12b1d34a7df50aed643c195eb29bb3435 192.168.xxx.xxx:6383
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 05984211b8c38222a73abeff1d4e459c0fe1efbc 192.168.xxx.xxx:6382
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 0c0767e13a09ee48541738d4163592cd9842c143 192.168.xxx.xxx:6386
slots: (0 slots) slave
replicates 05984211b8c38222a73abeff1d4e459c0fe1efbc
S: f8d0de47114bf33438747acd713cce4e412ae721 192.168.xxx.xxx:6384
slots: (0 slots) slave
replicates 1fc935c12b1d34a7df50aed643c195eb29bb3435
S: de0b393c17e452d856f6de2b348e9ca4e5aa4002 192.168.xxx.xxx:6385
slots: (0 slots) slave
replicates f451eb48bbc0a7c31c7da022ffe80cc1696e0f37
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
查看集群状态:
- 进入容器节点1(或集群中其他节点):
docker exec -it redis-node-1 /bin/bash
- 使用
redis-cli连接到6381节点:
redis-cli -p 6381
- 使用
redis的相关命令查看集群状态:
cluster info
其中,分配的哈希槽数量 cluster_slots_assigned为16384,集群节点数量cluster_known_nodes为6
- 查看集群节点信息
cluster nodes
Redis集群读写出错
当使用 redis-cli连接redis集群时,需要添加 -c参数,否则可能会出现读写出错。
示例:
- 进入容器节点1
docker exec -it redis-node-1 /bin/bash
- 使用
redis-cli连接,不加-c参数时
redis-cli -p 6381
- 此时向redis中添加键值对,可能会成功,也可能会失败
set k1 v1
报错:k1经过计算得到的哈希槽为12706,但是当前连接的redis-server为6381(即节点1),它的哈希槽为:[0,5460](在创建构建主从关系时redis有提示,也可以通过 cluster nodes查看),所以会因为存不进去而报错。
执行 set k2 v2可以成功,因为k2计算出的哈希槽在[0-5460]区间中。
- 使用
-c参数的redis-cli命令连接即可
redis-cli -p 6381 -c
- 此时可以正常的插入所有数据
set k1 v1
会有提示信息,哈希槽为12706,重定向到6383(即节点3,哈希槽[10923, 16383]):
集群信息检查
检查查看集群信息:
- 进入容器节点1
docker exec -it redis-node-1 /bin/bash
- 进行集群信息检查
# 输入任意一台主节点地址都可以进行集群检查
redis-cli --cluster check 192.168.xxx.xxx:6381
返回的检查结果:
当前集群中各个节点存储的key的数量
192.168.xxx.xxx:6381 (f451eb48...) -> 0 keys | 5461 slots | 1 slaves.
192.168.xxx.xxx:6383 (1fc935c1...) -> 1 keys | 5461 slots | 1 slaves.
192.168.xxx.xxx:6382 (05984211...) -> 0 keys | 5462 slots | 1 slaves.
[OK] 1 keys in 3 masters.
0.00 keys per slot on average.
主从机器信息
>>> Performing Cluster Check (using node 192.168.xxx.xxx:6381)
M: f451eb48bbc0a7c31c7da022ffe80cc1696e0f37 192.168.xxx.xxx:6381
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 1fc935c12b1d34a7df50aed643c195eb29bb3435 192.168.xxx.xxx:6383
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 05984211b8c38222a73abeff1d4e459c0fe1efbc 192.168.xxx.xxx:6382
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 0c0767e13a09ee48541738d4163592cd9842c143 192.168.xxx.xxx:6386
slots: (0 slots) slave
replicates 05984211b8c38222a73abeff1d4e459c0fe1efbc
S: f8d0de47114bf33438747acd713cce4e412ae721 192.168.xxx.xxx:6384
slots: (0 slots) slave
replicates 1fc935c12b1d34a7df50aed643c195eb29bb3435
S: de0b393c17e452d856f6de2b348e9ca4e5aa4002 192.168.xxx.xxx:6385
slots: (0 slots) slave
replicates f451eb48bbc0a7c31c7da022ffe80cc1696e0f37
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
主从扩容缩容
主从扩容
假如因为业务量激增,需要向当前3主3从的集群中再加入1主1从两个节点。
步骤:
- 启动2台新的容器节点
# 启动第7台节点
docker run -d --name redis-node-7 --net host --privileged=true -v /app/redis-cluster/share/redis-node-7:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6387
# 启动第8台节点
docker run -d --name redis-node-8 --net host --privileged=true -v /app/redis-cluster/share/redis-node-8:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6388
- 进入6387(节点7)容器内部
docker exec -it redis-node-7 /bin/bash
- 将6387作为master加入集群
# redis-cli --cluster add-node 本节点地址 要加入的集群中的其中一个节点地址
redis-cli --cluster add-node 192.168.xxx.xxx:6387 192.168.xxx.xxx:6381
- 检查当前集群状态
redis-cli --cluster check 192.168.xxx.xxx:6381
可以发现,6371节点已经作为master加入了集群,但是该节点没有被分配槽位。
- 重新分配集群的槽位
redis-cli --cluster reshard 192.168.xxx.xxx:6381
redis经过槽位检查后,会提示需要分配的槽位数量:
例如,我们现在是4台master,我们想要给node7分配4096个槽位,这样每个节点都是4096个槽位。
输入4096后,会让输入要接收这些哈希槽的节点ID,填入node7的节点ID即可。(就是节点信息中很长的一串十六进制串)。
然后会提示,询问要从哪些节点中拨出一部分槽位凑足4096个分给Node7。一般选择 all,即将之前的3个主节点的槽位都均一些给Node7,这样可以使得每个节点的槽位数相等均衡。
输入all之后,redis会列出一个计划,内容是自动从前面的3台master中拨出一部分槽位分给Node7的槽位,需要确认一下分配的计划。
输入yes确认后,redis便会自动重新洗牌,给Node7分配槽位。
重新分配完成后,可以进行集群信息检查,查看分配结果:
redis-cli --cluster check 192.168.xxx.xxx:6381
可以发现重新洗牌后的槽位分配为:
节点1:[1365-5460](供4096个槽位),,,分配前为[0-5460](共5461个槽位)
节点2:[6827-10922](共4096个槽位),,,分配前为[5461-10922](共5461个槽位)
节点3:[12288-16383](共4096个槽位),,,分配前为[10923-16383](共5462个槽位)
节点7:[0-1364],[5461-6826],[10923-12287](共4096个槽位),从每个节点中匀出来了一部分给了节点7
因为可能有些槽位中已经存储了key,完全的重新洗牌重新分配的成本过高,所以redis选择从前3个节点中匀出来一部分给节点7
为主节点6387分配从节点6388:
redis-cli --cluster add-node 192.168.xxx.xxx:6388 192.168.xxx.xxx:6381 --cluster-slave --cluster-master-id node7节点的十六进制编号字符串
redis便会向6388发送消息,使其加入集群并成为6387的从节点。
检查集群当前状态
redis-cli --cluster check 192.168.xxx.xxx:6381
主从缩容
假如业务高峰期过去,需要将4主4从重新缩容到3主3从。即从集群中移除node8和node7.
首先删除从节点6388:
- 进入容器节点1
docker exec -it redis-node-1 /bin/bash
- 检查容器状态,获取6388的节点编号
redis-cli --cluster check 192.168.xxx.xxx:6381
- 将6388从集群中移除
redis-cli --cluster del-node 192.168.xxx.xxx:6388 6388节点编号
对node7重新分配哈希槽:
- 对集群重新分配哈希槽
redis-cli --cluster reshard 192.168.xxx.xxx:6381
- redis经过槽位检查后,会提示需要分配的槽位数量:
How many slots do you want to move (from 1 to 16384)?
如果我们想直接把node7的4096个哈希槽全部分给某个节点,可以直接输入4096。
输入4096后,会让输入要接收这些哈希槽的节点ID。假如我们想把这4096个槽都分给Node1,直接输入node1节点的编号即可。
然后会提示,询问要从哪些节点中拨出一部分槽位凑足4096个分给Node1。这里我们输入node7的节点编号,回车后输入done。
node7上面没有了哈希槽,此时便可以将node7从集群中移除。(如果node7上面有哈希槽,直接从集群中移除会报错)
redis-cli --cluster del-node 192.168.xxx.xxx:6387 node7节点编号
--------------------------------------------------------
Docker 安装 tomcat
拉取 :

--------------------------------------------------------
自动启动(docker启动的时候自启动)
docker update redis --restart=always
docker update mysql --restart=always