
OrientDB 是一款高性能的文档、图数据库,在关系查找、遍历方面有很大的速度优势,特别是处理传统关系型数据库中的join操作,图数据库具有无法比拟的优点。虽然OrientDB官方提供了Java的SDK,但是还是有一定的学习成本,需要手撸操作脚本,本仓库对OrientDB的Java SDK进行了二次封装,以更加自然的语言操作OrientDB,降低学习成本,使得项目能更快的集成OrientDB。
特性
更简单的API :话不多说上例子感受,假如我们要保存一个People对象到图数据库,先看看原生的SDK例子:
public static void main(String[] args) { //使用原生JDK保存一个“人”顶点到图数据库 People people1 = new People("张三", "男", 18); try (ODatabaseSession session = OrientSessionFactory .getInstance() .getSession()) { //在图数据库创建Class:People if (session.getClass("People") == null) { session.createVertexClass("People"); } OVertex vertex = session.newInstance(); vertex.setProperty("name", people1.getName()); vertex.setProperty("age", people1.getAge()); vertex.save(); } }
原生的SDK将顶点封装成了Overtex对象,首先需要先获取会话ODatabaseSession,并且创建对应的顶点类,然后将实体相关的属性需要调用setProperty方法存入进去,并且保存,还要要留意关闭会话,对于属性多、数量多的实体简直是灾难,下面我们来看看使用OrientDB API:
public static void main(String[] args) { //创建实体对象 People people2 = new People("李四", "男", 21); //将实体对象包装成ResourceNode对象,其提供了对顶点的操作,对边的操作在ResourceRelation里 ResourceNode<People> li = new GraphResourceNode<>(people2); //直接调用save方法进行保存 li.save(); } @Getter @Setter @ToString //实现Vertex语义接口,表明该实体是一个图数据库的顶点对象 public class People implements Vertex { private String name; private String sex; private Integer age; public People(String name, String sex, Integer age) { this.name = name; this.sex = sex; this.age = age; } public People() { } }
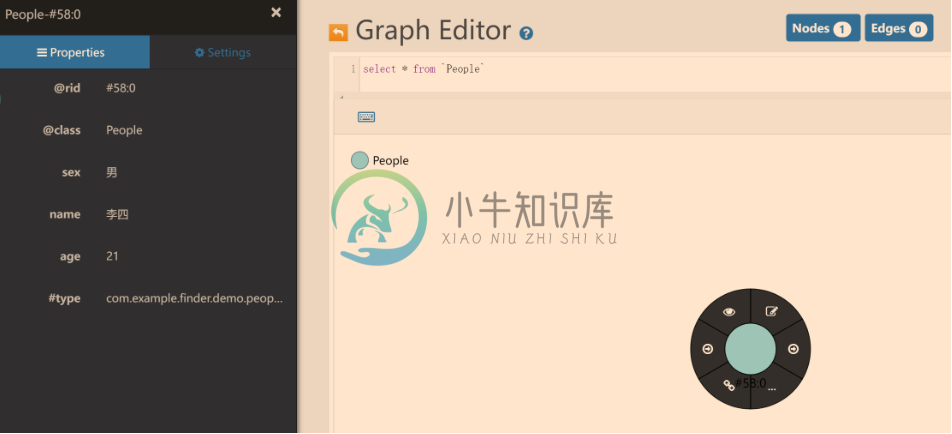
如上图,通过上面的语句就将实体对象People1存入了OrientDB。
更优雅的查询 :原生SDK的查询难免会跟OrientDB的SQL语句或者Match语句打交道,而且国内的中文文档很少和相关博客也很少,学习成本进一步加大,因此OrientDB API对常用查询操作进行了封装,做到完全透明化,下面我们来看一个示列:使用原生SDK进行查询:
public static void main(String[] args) { try (ODatabaseSession session = OrientSessionFactory .getInstance() .getSession()) { OResultSet resultSet = session.query("select * from People where name = ?", "李四"); People people=new People(); while(resultSet.hasNext()){ OResult result= resultSet.next(); people.setName(result.getProperty("name")); people.setAge(result.getProperty("age")); } resultSet.close(); } }
原生JDK使用起来跟JDBC差不多,体验差,下面看看OrientDB API查询:
public static void main(String[] args) { //创建资源图对象,其提供了很多对图的直接操作。使用OrientDB存储库(后续可以拓展Neo4j等存储库) ResourceGraph graph = new ResourceGraph(new OrientDBRepository()); //调用extractNode方法取出指定节点 ResourceNode<People> peopleResourceNode = graph.extractNode(QueryParamsBuilder .newInstance() .addParams("name", "李四") .getParams()); //获取节点对应的属性实体 People people = peopleResourceNode.getSource(); }
更人性化的遍历 : 单一的查询肯定不能满足实际的需要,OrientDB提供了图的遍历,支持更复杂的查询,通过遍历我们能找到与任意一个节点有某种关系的其他节点,使用原生SDK如下:
public static void main(String[] args) { try (ODatabaseSession session = OrientSessionFactory .getInstance() .getSession()) { //从顶点#74:0出发,深度优先遍历7层以内的同学,并且进行分页 OResultSet resultSet = session.query("select * from (traverse * from #74:0 MAXDEPTH 7 STRATEGY DEPTH_FIRST) where (@class = \"Classmate\") skip 0 limit 10"); List<ClassMates> classMates=new ArrayList<>(); while(resultSet.hasNext()){ ClassMates classMate=new ClassMates(null); OResult result= resultSet.next(); classMate.setDate(result.getProperty("date")); //... classMates.add(classMate); } resultSet.close(); } }
使用OrientDB API
public static void main(String[] args) { //创建资源图对象,其提供了很多对图的直接操作。使用OrientDB存储库(后续可以拓展Neo4j等存储库) ResourceGraph graph = new ResourceGraph(new OrientDBRepository()); //直接调用traverse方法,参数分别是,出发节点、深度、遍历策略、分页配置、目标实体类型 PagedResult<ResourceNode<? extends Vertex>> result = graph.traverse(graph.extractNode("#74:0"), QueryParamsBuilder .newInstance() .getParams(), 7, TraverseStrategy.DEPTH_FIRST, new PageConfig(1, 10, true), ClassMates.class); result .getSources() .forEach(item -> System.out.println(item.getSource())); }
无需语句,透明化,更人性化。
-
orientdb object api供orientdb的class和java的class mapping映射,面向对象操作 pom.xml <dependency> <groupId>com.orientechnologies</groupId> <artifactId>orientdb-object</artifactId> <version>3.0.30</versi
-
我想为OrientDB的二进制API编写 PHP适配器. 但是我需要一些在PHP中具有原始套接字通信经验的人的帮助 – 我似乎无法超越将PHP连接到OrientDB的第一个障碍. 如果有人使用套接字来体验这个,我将不胜感激: 如果我们可以通过第一个障碍并实际发送一个数据包(该页面底部的简化示例 – 请向下滚动到最后),我当然可以编写适配器. 如果我这样做,这当然会作为开源发布. 希望有人可以帮助我
-
OrientDB入门 OrientDB是什么? 用一句话概括:一种Nosql数据库,支持文档、Key/Value,文档,图多种模型。 基础概念 记录 是读取和存储的最小单元。有四种类型: * 文档(Document) * 字节流(RecordBytes) * 顶点(Vertex) * 边(Edge) 文档 文档是OrientDB中最灵活的记录类型。文档默认有类型,通过约束的模式来定义,但是也可以使
-
Orient DB 是一个可伸缩的文档数据库,支持 ACID 事务处理。使用 Java 5 实现。 OrientDB 1.3.0 发布了,主要改进内容包括: 新的 eval() 函数用于执行表达式 新的 if() 和 ifnull() 条件判断函数 支持服务器端函数配置 全新命令 DELETE VERTEX 和 DELETE EDGE 可直接在 SQL 命令中执行数据库函数 新的创建集群的命令 增
-
Cassandra vs MongoDB vs CouchDB vs Redis vs Riak vs HBase vs Couchbase vs OrientDB vs Aerospike vs N
http://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis (Yes it's a long title, since people kept asking me to write about this and that too :) I do when it has a point.) While SQL databases are in
-
根因 因为磁盘满了的时候,nexus的orientdb数据库文件损坏了。导致调用API时报错:Exception 241F5D11 in storage plocal:/nexus-data/db/component 解决办法 参考: 进入到nexus db目录下,找到对应的component目录, cd /usr/local/soft/sonatype-work4/nexus3/db/compo
-
问题内容: 我需要一些想法来实现Java的(真正)高性能内存数据库/存储机制。在存储20,000+个Java对象的范围内,每5秒钟左右更新一次。 我愿意接受的一些选择: 纯JDBC /数据库组合 JDO JPA / ORM /数据库组合 对象数据库 其他存储机制 我最好的选择是什么?你有什么经验? 编辑:我还需要能够查询这些对象 问题答案: 您可以尝试使用Prevayler之类的工具(基本上是一个
-
Uragano 旨在提供一个搭建和使用简单的高性能 RPC 框架。Uragano 是基于 netstandard2.0 开发的。Uragano 默认采用 DotNetty 实现远程通信,使用 MessagePack 进行编解码。
-
问题内容: 我在公司中多次设计数据库。为了提高数据库的性能,我只寻找标准化和索引。 如果要求您提高数据库的性能,该数据库包含大约250个表以及一些具有数百万个记录的表,那么您将寻找什么不同的东西? 提前致谢。 问题答案: 优化逻辑设计 逻辑级别是关于查询和表本身的结构。首先尝试最大程度地发挥这一作用。目标是在逻辑级别上访问尽可能少的数据。 拥有最高效的SQL查询 设计支持应用程序需求的逻辑架构(例
-
Kdb+ 是来自 Kx Systems Inc 的高性能列式数据库。 kdb+ 旨在捕获,分析,比较和存储数据 - 所有这些都是高速和大量数据。
-
我们正在快速开发一个应用程序,其中我们需要一次获取超过50K行(在应用程序加载时执行),然后数据将用于应用程序的其他部分进行进一步计算。我们正在使用Firebase实时数据库,我们面临一些严重的性能问题。 它目前需要大约40秒才能加载50K行(目前使用的是免费数据库版本,不确定这是否是原因),但我们也观察到,当多个用户使用该应用程序时,加载50K行开始需要大约1分20秒,Peak达到100%。 您
-
主要内容:一般业务系统运行流程图,一台 4 核 8G 的机器能扛多少并发量呢?,高并发来袭时数据库会先被打死吗?,8 核 16G 的数据库每秒大概可以抗多少并发压力?,数据库架构可以从哪些方面优化?,总结今天给大家分享一个知识点,是关于 MySQL 数据库架构演进的,因为很多兄弟天天基于 MySQL 做系统开发,但是写的系统都是那种低并发压力、小数据量的,所以哪怕上线了也就是这么正常跑着而已。 但是你知道你连接的这个 MySQL 数据库他到底能抗多大并发压力吗?如果 MySQL 数据库扛不住压力
-
我们创建了一个程序,以便在其他程序中更容易地使用数据库。因此,我显示的代码将在多个其他程序中使用。 其中一个程序从我们的一个客户那里获得大约10000条记录,并且必须检查这些记录是否已经存在于我们的数据库中。如果没有,我们将它们插入数据库(它们也可以更改,然后必须更新)。 为了方便起见,我们从整个表中加载所有条目(目前为120,000个),为我们得到的每个条目创建一个类,并将它们全部放入Hashm
-
我有一个基于Java8 Spring Boot 2.3.3的应用程序(使用Hibernate5.4.20),我有一个Postgreql。我想最终了解使用数据库视图和@Sub选择是否更好(对于性能)。 简单概述一下:我有一个实体“Book”和3个实体“BookRank”(用户给书打1到10颗星)、“BookComment”(用户对书的评论)、“BookLike”(用户把书的评论放在一起),每个实体都