
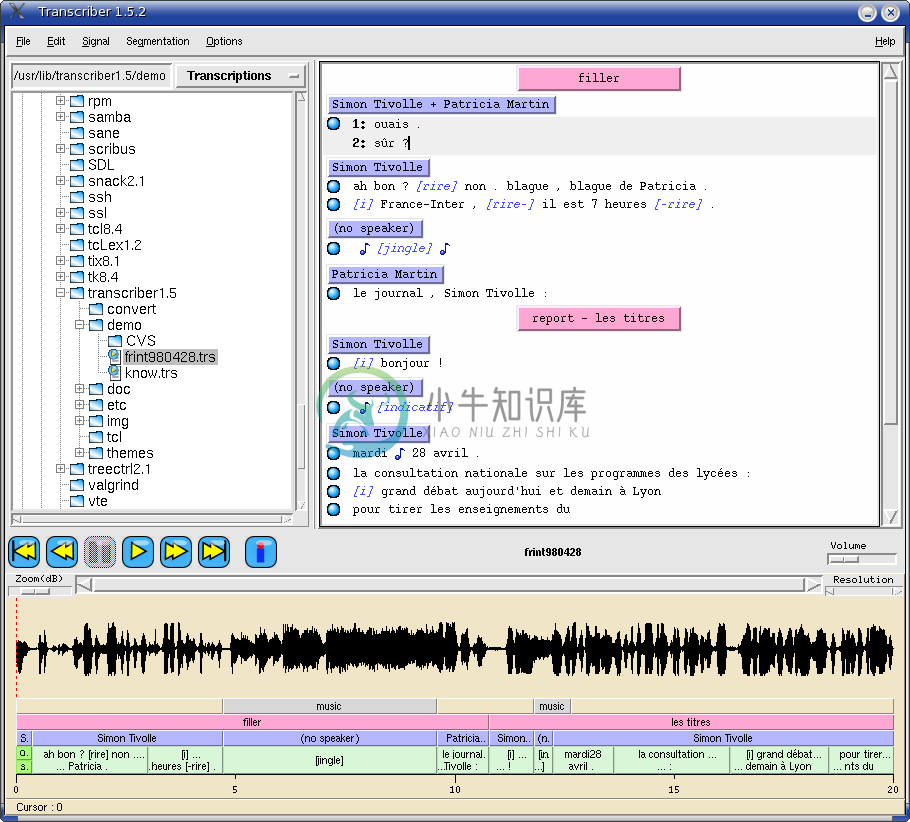
识别修正工具可用Transcriber。它是在语言数据联盟(Linguistic data consortium, LDC)资助下、在Linux系统上用Tcl/Tk脚本语言和扩展的C语言开发的用于语音处理的开源软件。该开源软件是的用于对音频数据分割和标注,以及对字幕的修改。通过对该软件的设置和修改,可以使其适合汉语的字幕修改。
-
Interviews have been used as a means of communication for the longest time possible. This is one of the ways that can be used to extract or get information that is needed when a person wants to come u
-
十二、后处理工具 随着 PostCSS 的不断完善,各种插件如雨后春笋般的涌现出来,其中不乏一些很优秀的插件。 面向未来的 CSS Autoprefixer 根据 caniuse 的数据自动增加前缀,解放双手的利器(??? 推荐? ) postcss-cssnext 支持大量浏览器未实现的标准特性(CSS 变量,嵌套等)(?? 推荐? ) 格式化工具 stylefmt 支持 CSS、SCSS 等多
-
预处理工具 不同的 CSS 预处理工具有着不同的特性、功能以及语法。编码习惯应当根据使用的预处理工具进行扩展, 以适应其特有的功能。推荐在使用 SCSS 时遵守以下指导。 将嵌套深度限制在1级。对于超过2级的嵌套,给予重新评估。这可以避免出现过于详实的 CSS 选择器。 避免大量的嵌套规则。当可读性受到影响时,将之打断。推荐避免出现多于20行的嵌套规则出现。 始终将@extend语句放在声明块的第
-
本文向大家介绍易语言做语音朗读工具方法,包括了易语言做语音朗读工具方法的使用技巧和注意事项,需要的朋友参考一下 怎么自己动手做一个语音朗读的小工具呢 1、打开易语言,新建一个易语言窗口程序 2、在右边添加一个媒体播放组件和一个编辑框组件,一个按钮组件。 3、在左边模块菜单添加精易模块 4、在左边属性改下如下属性内容 5、双击启动窗口,写入如下代码 6、双击按钮组件,写入如下代码 7、点击运行,并静
-
目前需要用whsiper做语音转录服务,whisper限制25M的大小,请问该如何做这个事情? 目前的需求是 Android iOS Web 都需要这个功能, 目前有几种方案: 方案1 做一个音频分割服务器,然后在做一个转录服务。前端拿到语音文件之后,把语音文件传给音频分割服务器,分割服务器根据波形进行分割,分割完之后传给转录接口。 问题: 这样做的话是不是会造成语音上传多次导致时间较长的问题,因
-
我正在开发一个功能,当按下一个按钮时,它将启动语音识别,同时将记录用户所说的话。代码如下: 我一步一步地制作了这个应用程序,起初这个应用程序没有录音功能,语音识别效果非常好。 在我多次测试并认为语音识别正常后,我开始使用合并录音功能。 然后,我进行了测试,一旦按下按钮\u start,甚至在我试图说话之前,就会立即出现ERROR3音频信息。 我播放录音。语音也被正确记录和保存。 发生什么事了?为什
-
我正在为基于Xamarin的简单语音识别移动应用程序评估“Bing语音API”及其新兄弟“语音服务”(仍处于预览模式)。 我使用API REST取得了很好的效果,但它的限制持续时间为15秒,这使得它很难应用于连续语音识别和唤醒词。 由于这个原因,我还研究了Bing语音和基于web socket(也称为客户端库)的语音服务SDK。它们在桌面应用程序上运行良好,但似乎与Xamarin不兼容(见下图)。