

-
有两个(好吧,三个。。。请参见下面的“更新3”,了解第三个)单独的事情: 1)您的代码返回两个树(两个ROOT),但您只希望得到一个。发生这种情况是因为raw_parse_sents需要一个句子列表,而不是一个句子,如果您给它一个字符串,它将解析字符串中的每个字符,就像它自己的句子一样,并返回一个一个字符树的列表。所以要么传递raw_parse_sents一个列表,要么使用raw_parse。在
-
第一篇csdn 最近在跑一个网络模型,在linux系统下安装stanford使遇到了一点问题,还好最后成功装好了,在这分享一下安装的过程叭~ 1、先安装java运行环境 在命令行下运行以下两句: sudo apt-get install default-jre sudo apt-get install default-jdk 2、下载stanford corenlp包 去stanfordcoren
-
Traceback (most recent call last): File "D:/pythonProject/company/新活动发现/tg/实体识别/ner.py", line 4, in <module> nlp = StanfordCoreNLP('D:/stanford_nlp/stanford-corenlp-4.2.0', lang='zh')#处理中文需指定lan
-
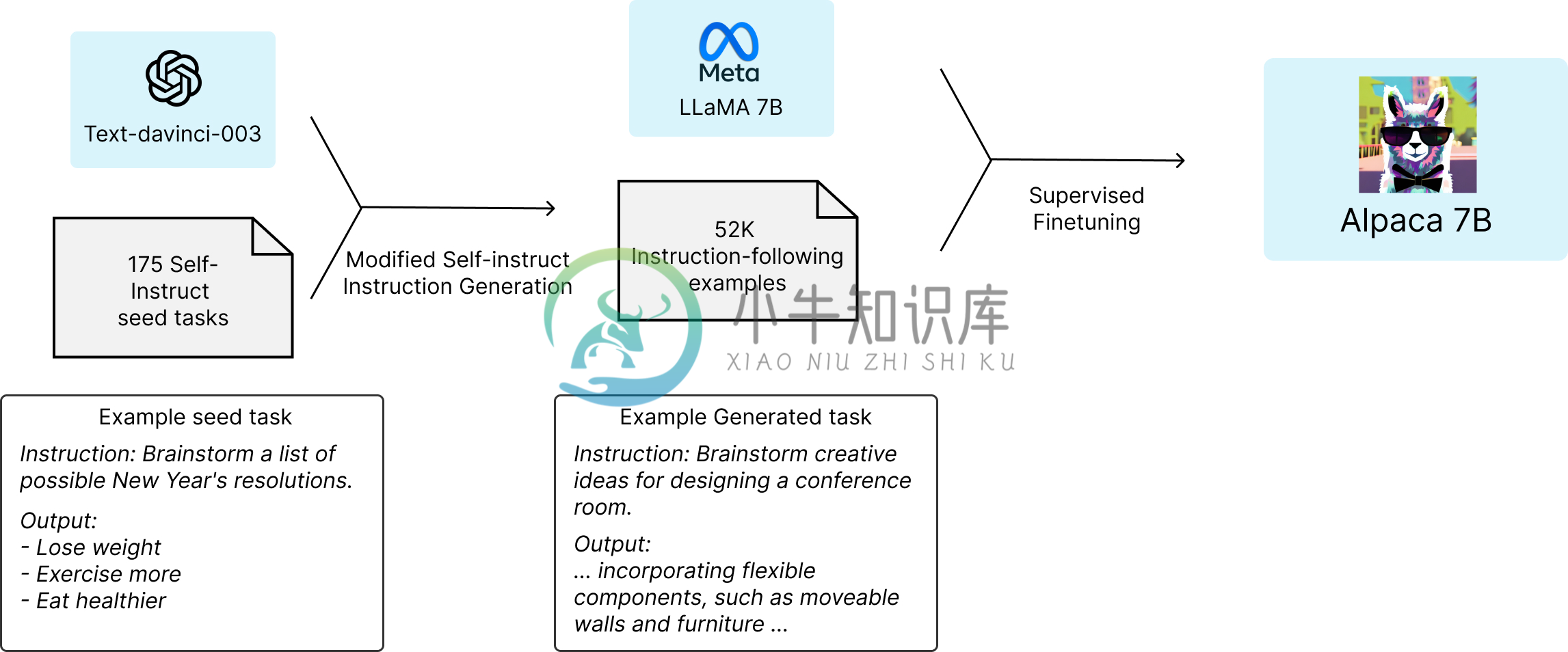
LLaMA 语言模型全称为 "Large Language Model Meta AI",是 Meta 的全新大型语言模型(LLM),这是一个模型系列,根据参数规模进行了划分(分为 70 亿、130 亿、330 亿和 650 亿参数不等)。 值得注意的是,其中 LaMA-13B(130 亿参数的模型)尽管模型参数相比 OpenAI 的 GPT-3(1750 亿参数) 要少了十几倍,但在性能上反而可
-
Lit-LLaMA 是一个基于 nanoGPT 的 LLaMA 语言模型的实现,支持量化、LoRA 微调、预训练。 设计原则 简单:单一文件实现,没有样板代码 正确:在数值上等同于原始模型 优化:在消费者硬件上或大规模运行 开源:无附加条件 设置 克隆仓库 git clone https://github.com/Lightning-AI/lit-llamacd lit-llama 安装依赖项 p
-
alpaca是alpaca-llama工具的一部分,主要应用在词法分析算法上面,将描述词法的正则表达式集转换成为相应的DFA,然后采用DOT格式输出。
-
wx:if 预期: any 用法: 根据表达式的值的 truthiness 来有条件地渲染元素。在切换时元素及它的数据绑定 / 组件被销毁并重建。 注意:如果元素是 <block/>, 注意它并不是一个组件,它仅仅是一个包装元素,不会在页面中做任何渲染,只接受控制属性。 WARNING 当和 wx:if 一起使用时,wx:for 的优先级比 wx:if 更高。详见列表渲染教程 参考: 条件渲染 -
-
问题内容: 我想通过标签上的参数将调用发送回指令,然后在指令内部适当时调用该方法。例如,当单击按钮时,调用父控制器上的方法。 我有一个简单的问题,它无法正常工作 html文件: javascript文件: 问题答案: 棘手的棘手角度,在HTML中声明参数时,需要使用蛇形大小写而不是驼峰形匹配。 作品: 不起作用:
-
属性 值发生变化后,必须立刻上报最新的值。此外,属性可以选择周期性上报,或一次性上报。 周期性上报时,每个属性的上报周期可以不同,最短周期不得低于一小时,周期要注意并发性问题,如果某一产品定在每天晚上8点准时上报属性,就有可能导致云端处理不过来而丢包,造成严重的并发性问题。 另外,因为属性在云端也需要维持一个最新属性值,所以重要的属性采用request通信方式已保证状态同步,可用在APP设备列表的
-
blue-highlight.directive.ts yellow-highlight.directive.ts app.module.ts 让我们看看我们如何在模块的唯一组件中使用它。 app.component.ts 我们允许将多个指令用在同一模块中的相同元素上。Angular将按顺序进行每个转换每个指令。 因为我们已经在数组中定义了两个指令,并且数组是有序集合的项,当编译器找到具有属性的元
-
我正在分析Agner Fog的《优化汇编语言中的子例程:x86平台的优化指南》。尤其是我正在努力理解第12.7章。还有一个问题我无法理解。作者写道: PM处理器中的指令解码遵循4-1-1模式。示例12.6b中循环中每条指令的(融合)μops模式为2-2-2-2-2-1-1-1。这不是最优的,解码需要6个时钟周期。这超过了失效时间,因此我们可以得出结论,在示例12.6b中,指令解码是瓶颈。总执行时间