
Lit-LLaMA 是一个基于 nanoGPT 的 LLaMA 语言模型的实现,支持量化、LoRA 微调、预训练。
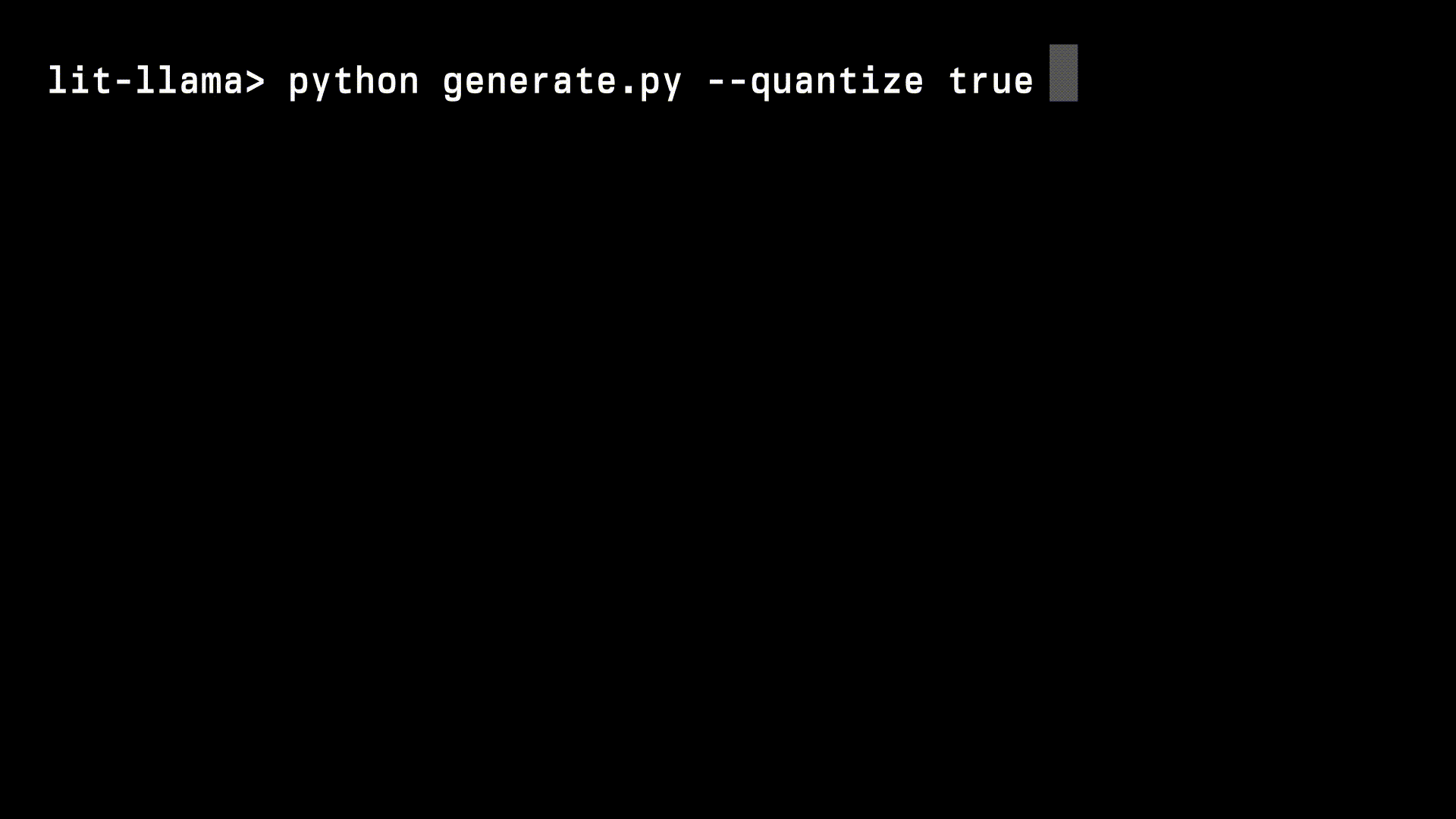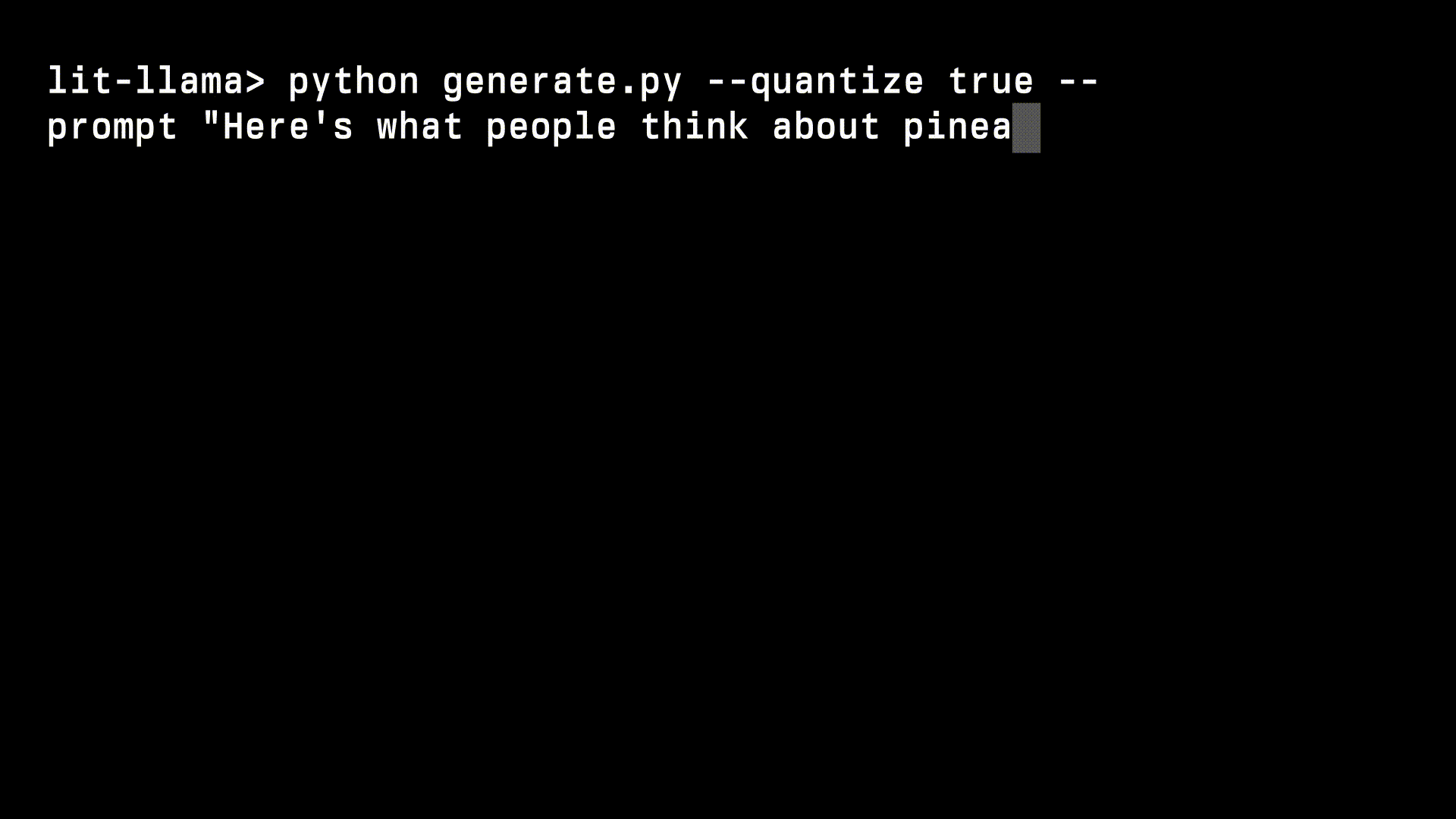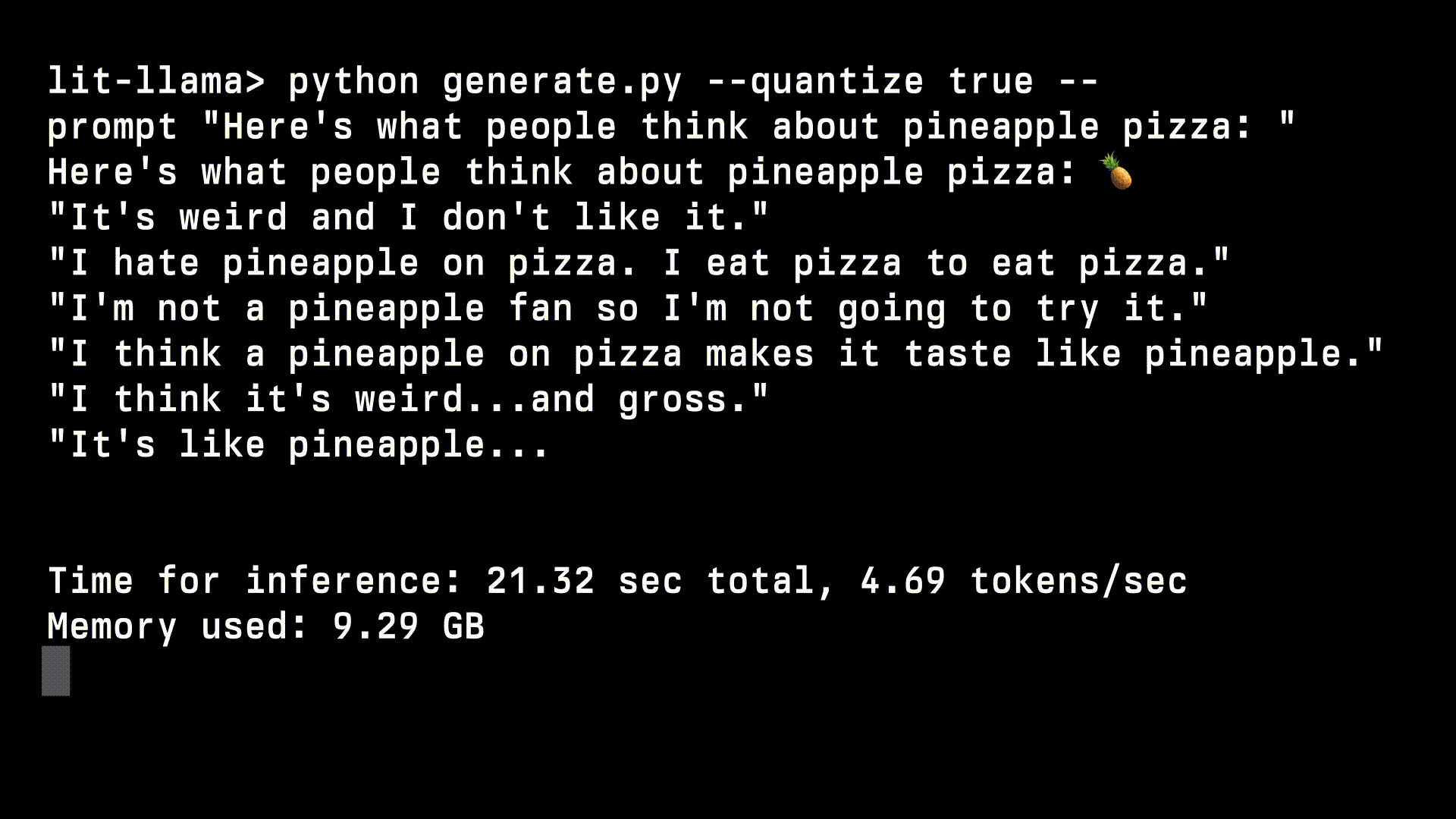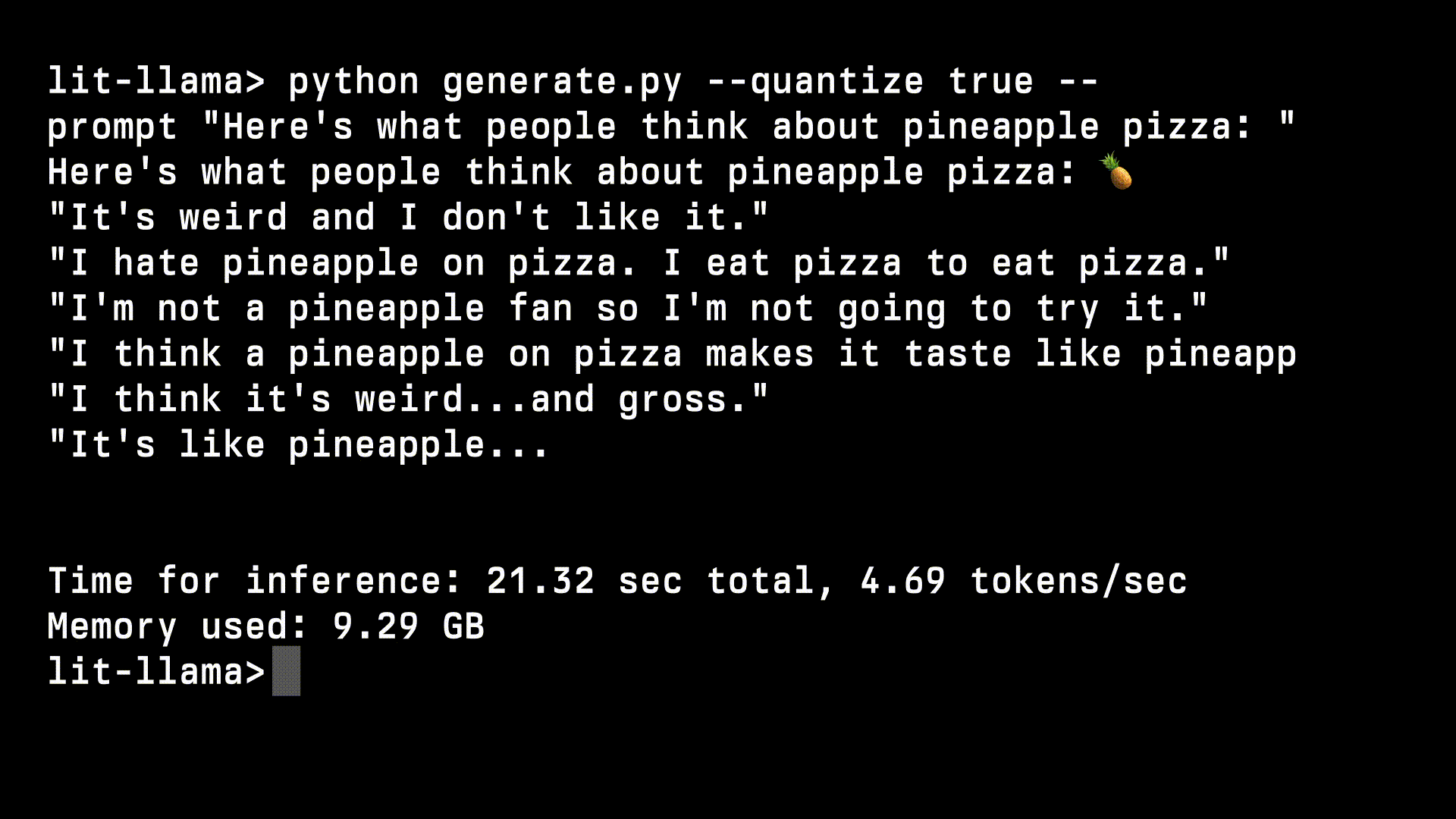
设计原则
- 简单:单一文件实现,没有样板代码
- 正确:在数值上等同于原始模型
- 优化:在消费者硬件上或大规模运行
- 开源:无附加条件
设置
克隆仓库
git clone https://github.com/Lightning-AI/lit-llama cd lit-llama
安装依赖项
pip install -r requirements.txt
-
nanoGPT 自称是训练/调整中型 GPT 最简单、最快的资料库,目前仍在积极开发中,但文件 train.py在 OpenWebText 上重现了 GPT-2(在一个 8XA100 40GB 节点上训练了大约 4 天)。 因为代码非常简单,所以很容易根据你的需要进行修改、从头开始训练新的模型,或者对预训练的进行微调。 安装 依赖项: pytorch <3 numpy <3 pip install
-
Thx回答。
-
本章介绍 Java 的语言基础。
-
lit a little preprocessor for literate programming Quick Start By default, extracts code from Markdown files: # strip out Markdown content from literate programming# files in the current directory, le
-
本文向大家介绍语言模型相关面试题,主要包含被问及语言模型时的应答技巧和注意事项,需要的朋友参考一下 语言模型的作用之一为消解多音字的问题,在声学模型给出发音序列之后,从候选的文字序列中找出概率最大的字符串序列。 目前使用kenlm(https://github.com/kpu/kenlm)训练bi-gram语言模型。bi-gram表示当前时刻的输出概率只与前一个时刻有关。即 P(X{n} | X{
-
语言模型(language model)是自然语言处理的重要技术。自然语言处理中最常见的数据是文本数据。我们可以把一段自然语言文本看作一段离散的时间序列。假设一段长度为$T$的文本中的词依次为$w_1, w_2, \ldots, w_T$,那么在离散的时间序列中,$w_t$($1 \leq t \leq T$)可看作在时间步(time step)$t$的输出或标签。给定一个长度为$T$的词的序列$
-
Go是一门类似C的编译型语言,但是它的编译速度非常快。这门语言的关键字总共也就二十五个,比英文字母还少一个,这对于我们的学习来说就简单了很多。先让我们看一眼这些关键字都长什么样: break default func interface select case defer go map struct chan e
-
前面一节我们为大家介绍了什么是 Gradle?Gradle 是一个构建工具,它的构建脚本是基于 Groovy 或是 Kotlin 语言编写的。 今天我们就来看下 Groovy 的基础语法。Groovy 结合了 Java、Python、Ruby 等当下几大流行语言的优点。它可以说是从 Java 中衍生出来的,为什么这么说呢?因为它的语法和 Java 非常的相似,它的文件也是可以编译为 .class