
FinRL 是一个面向研究人员和从业者的开源深度强化学习 (DRL) 框架。
使命:有效地实现交易自动化。
愿景:在过去的十年中,人工智能社区已经积累了一个开源的代码海洋。将这些知识和工程特性应用于金融,将启动一个范式的转变,从传统的交易常规到自动化的机器学习方法,甚至是金融业的 RLOps。
FinRL(网站)是第一个探索深度强化学习在金融领域巨大潜力的开源项目,旨在帮助从业者使用深度强化学习(DRL)来制定交易策略。
FinRL 生态系统是一个统一的框架,包括各种市场、最先进的算法、金融任务(投资组合管理、加密货币交易、高频交易)、实时交易等。
FinRL 具有三层:应用程序、drl 代理和市场环境。
对于交易任务(顶部),代理(中间)与环境(底部)交互,做出顺序决策。
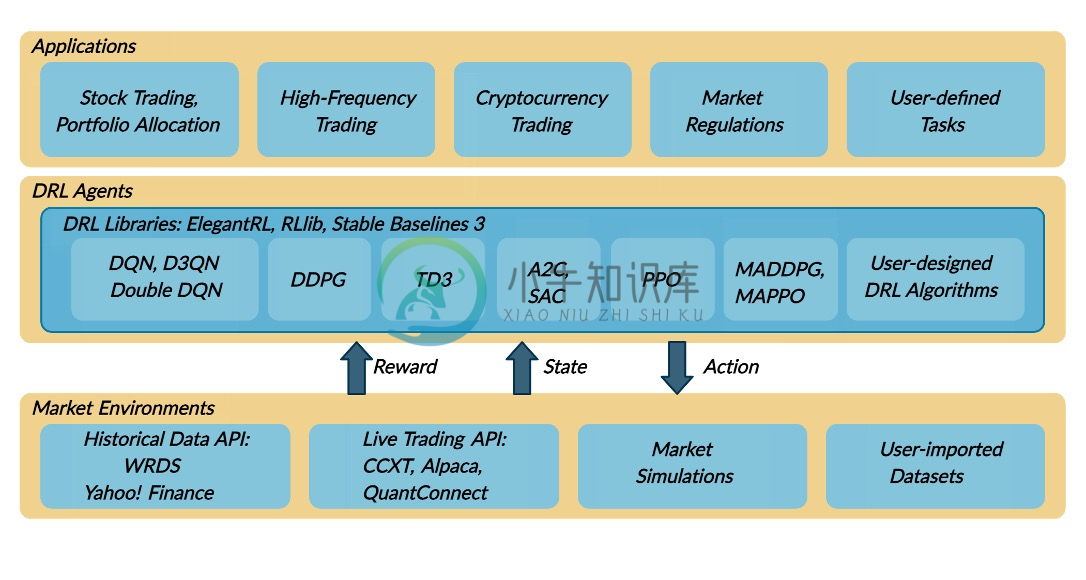
Contributions
- FinRL 是第一个展示在量化金融中应用 DRL 算法的巨大潜力的开源框架。我们围绕 FinRL 框架构建了一个生态系统,为快速发展的 AI4Finance 社区提供了种子。
- 应用层为用户提供接口来定制 FinRL 到他们自己的交易任务。提供自动回测工具和性能指标,以帮助量化交易者以高周转率迭代交易策略。有利可图的交易策略是可重复的,并且以对初学者友好的方式提供了动手教程。也可以根据快速变化的市场调整训练好的模型。
- 代理层提供了最先进的 DRL 算法,这些算法适用于通过微调的超参数进行融资。用户可以添加新的 DRL 算法。
- 环境层不仅包括历史数据 API 的集合,还包括实时交易 API。它们被重新配置为标准的 OpenAI 健身房风格环境。此外,它结合了市场摩擦,并允许用户自定义交易时间粒度。
-
finRL源解读 required = { ‘yfinance’, ‘pandas’, ‘matplotlib’, ‘stockstats’, ‘stable-baselines’, ‘gym’} 数据处理 获取股票日价格以及加入各种指标作为state,如果是多只股票,排列方式为根据每日每只股票排列。index累加。 分成训练集和测试集 建模 state_space: state_spac
-
1、创建agent agent = DRLAgent(env = env_train) SAC_PARAMS = { "batch_size": 128, "buffer_size": 1000000, "learning_rate": 0.0001, "learning_starts": 100, "ent_coef": "auto_0.1", "
-
FinRL-Meta: 一个金融强化学习框架 论文地址:https://arxiv.org/pdf/2211.03107.pdf 1. 引言 在金融领域,预测股票趋势和制定交易策略是一项具有挑战性的任务。数据驱动强化学习已经成为一种流行的方法来解决这个问题。然而,建立高质量市场环境和基准是一个挑战。为了解决这个问题,我们介绍了一个名为FinRL-Meta的开源库。 FinRL-Meta是一个基于P
-
深入了解 “FinRL:量化金融中自动化股票交易的深度强化学习库” 论文 论文地址: 一、引言 介绍量化交易中的深度强化学习应用 简述FinRL库的目标和功能 想象一下,你是一位初学者,想要涉足量化金融世界,却发现训练一个实用的DRL交易代理需要进行容易出错和费力的开发和调试。这时候,FinRL库就像救世主一样出现在你面前! 二、论文做了什么事 提出了一种基于深度强化学习的自动化股票交易框架 设计
-
1、env(gym.env) 创建一个gym.env为父类的 金融环境 2、DRLAgent() 创建一个类 用于导入stable_baselines3里面的强化学习模型 如(A2C,SAC..等等) 3、model.learn 通过stable_baselines3导入的强化学习模型 用learn函数进行训练模型 4、tensorboard 通过stable_baselines3 中包含的 te
-
先说结论。别用Fin RL了,就那个bug和国内体验,建议直接上手ElegantRL,粗看了下,只要是有开发基础和简单的深度学习经验的,全看得懂,无门槛,更何况还有一堆demo和tutorial。 先挖个坑,后面来填
-
我正在写学士论文。 我的主题是强化学习。设置: Unity3D (C#) 自己的神经网络框架 通过测试来训练正弦函数,确认网络工作正常。它可以近似。好有些价值观达不到他们的期望值,但这已经足够好了。当用单个值训练它时,它总是收敛的。 这是我的问题: 我试着教我的网络一个简单游戏的Q值函数,接球:在这个游戏中,它只需要接住一个从随机位置和随机角度落下的球。1如果接住-1如果失败 我的网络模型有 1
-
本节将讨论优化与深度学习的关系,以及优化在深度学习中的挑战。在一个深度学习问题中,我们通常会预先定义一个损失函数。有了损失函数以后,我们就可以使用优化算法试图将其最小化。在优化中,这样的损失函数通常被称作优化问题的目标函数(objective function)。依据惯例,优化算法通常只考虑最小化目标函数。其实,任何最大化问题都可以很容易地转化为最小化问题,只需令目标函数的相反数为新的目标函数即可
-
我计划编写一个国际象棋引擎,它使用深度卷积神经网络来评估国际象棋的位置。我将使用位板来表示棋盘状态,这意味着输入层应该有12*64个神经元用于位置,1个用于玩家移动(0表示黑色,1表示白色)和4个神经元用于铸币权(wks、bks、wqs、bqs)。将有两个隐藏层,每个层有515个神经元,一个输出神经元的值介于-1表示黑色获胜,1表示白色获胜,0表示相等的位置。所有神经元都将使用tanh()激活函数
-
主要内容 课程列表 基础知识 专项课程学习 参考书籍 论文专区 课程列表 课程 机构 参考书 Notes等其他资料 MDP和RL介绍8 9 10 11 Berkeley 暂无 链接 MDP简介 暂无 Shaping and policy search in Reinforcement learning 链接 强化学习 UCL An Introduction to Reinforcement Lea
-
强化学习(Reinforcement Learning)的输入数据作为对模型的反馈,强调如何基于环境而行动,以取得最大化的预期利益。与监督式学习之间的区别在于,它并不需要出现正确的输入/输出对,也不需要精确校正次优化的行为。强化学习更加专注于在线规划,需要在探索(在未知的领域)和遵从(现有知识)之间找到平衡。 Deep Q Learning.
-
问题内容: 我目前正在从事一个项目,该项目依赖于几个数学/统计/财务工具,我希望将其包含在一个(也许几个)库中。我想拥有的是: 统计量度-模式,方差等 概率分布+可用的抽样 期权定价等财务模型 有谁知道哪个库可能有用? 问题答案: 我在Java和Clojure中进行了大量数值工作,因此希望我的观点会有所帮助。 对于1.和2.,有一些可供探索的选项: 并行Colt-非常全面的高性能数学库。非常适合您
-
探索和利用。马尔科夫决策过程。Q 学习,策略学习和深度强化学习。 我刚刚吃了一些巧克力来完成最后这部分。 在监督学习中,训练数据带有来自神一般的“监督者”的答案。如果生活可以这样,该多好! 在强化学习(RL)中,没有这种答案,但是你的强化学习智能体仍然可以决定如何执行它的任务。在缺少现有训练数据的情况下,智能体从经验中学习。在它尝试任务的时候,它通过尝试和错误收集训练样本(这个动作非常好,或者非常
-
强化学习(RL)如今是机器学习的一大令人激动的领域,也是最老的领域之一。自从 1950 年被发明出来后,它被用于一些有趣的应用,尤其是在游戏(例如 TD-Gammon,一个西洋双陆棋程序)和机器控制领域,但是从未弄出什么大新闻。直到 2013 年一个革命性的发展:来自英国的研究者发起了 Deepmind 项目,这个项目可以学习去玩任何从头开始的 Atari 游戏,在多数游戏中,比人类玩的还好,它仅