
ormb(OCI-Based Registry for ML/DL Model Bundle)是基于镜像仓库的机器学习模型分发组件,旨在帮助企业像管理容器镜像一样管理机器学习模型。它不仅提供版本化的模型管理能力,还可利用符合 OCI 标准的容器镜像仓库存储和分发机器学习模型。通过 Harbor 2.0,它可以实现在多个镜像仓库间的同步,满足更多企业级需求。
基于这个项目,才云之后会继续开源基于 Harbor 实现的模型仓库,提供更多能力。其中包括但不限于模型的格式转换、模型自动压缩等高级特性。
端到端的示例
我们以图像识别作为示例,介绍一下如何利用 ormb 进行机器学习模型的分发。
在这一示例中,我们会在本地利用 Fashion MNIST 训练一个简单的 CNN 图像识别模型,并利用 ormb 将其推送到远端镜像仓库中。随后,在服务器上,我们同样利用 ormb 将模型拉取下来,利用第三方的模型服务器对外提供服务。最后,我们再利用 RESTful 的接口调用这一服务,查看结果。
下方是模型训练的代码,我们将训练好的模型保存为 SavedModel 格式,并将模型提供在 ormb 示例中:
# 建立模型,设定 Optimizer,进行训练
model = keras.Sequential([
keras.layers.Conv2D(input_shape=(28,28,1),
filters=8,
kernel_size=3,
strides=2,
activation='relu',
name='Conv1'),
keras.layers.Flatten(),
keras.layers.Dense(10,
activation=tf.nn.softmax,
name='Softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=epochs)
test_loss, test_acc = model.evaluate(test_images,
test_labels)
import tempfile
# 保存模型到当前目录的 model 子目录下
MODEL_DIR = "./model"
version = 1
export_path = os.path.join(MODEL_DIR, str(version))
tf.keras.models.save_model(
model,
export_path,
overwrite=True,
include_optimizer=True,
save_format=None,
signatures=None,
options=None
)接下来,我们将在本地训练好的模型推送到远端镜像仓库中:
# 将模型保存在本地文件系统的缓存中
$ ormb save ./model gaocegege/fashion_model:v1
ref: gaocegege/fashion_model:v1
digest: 6b08cd25d01f71a09c1eb852b3a696ee2806abc749628de28a71b507f9eab996
size: 162.1 KiB
format: SavedModel
v1: saved
# 将保存在缓存中的模型推送到远端仓库中
$ ormb push gaocegege/fashion_model:v1
The push refers to repository [gaocegege/fashion_model]
ref: gaocegege/fashion_model:v1
digest: 6b08cd25d01f71a09c1eb852b3a696ee2806abc749628de28a71b507f9eab996
size: 162.1 KiB
format: SavedModel
v1: pushed to remote (1 layer, 162.1 KiB total)以 Harbor 为例,在 Harbor 镜像仓库中,我们可以看到这一模型的元数据等信息:
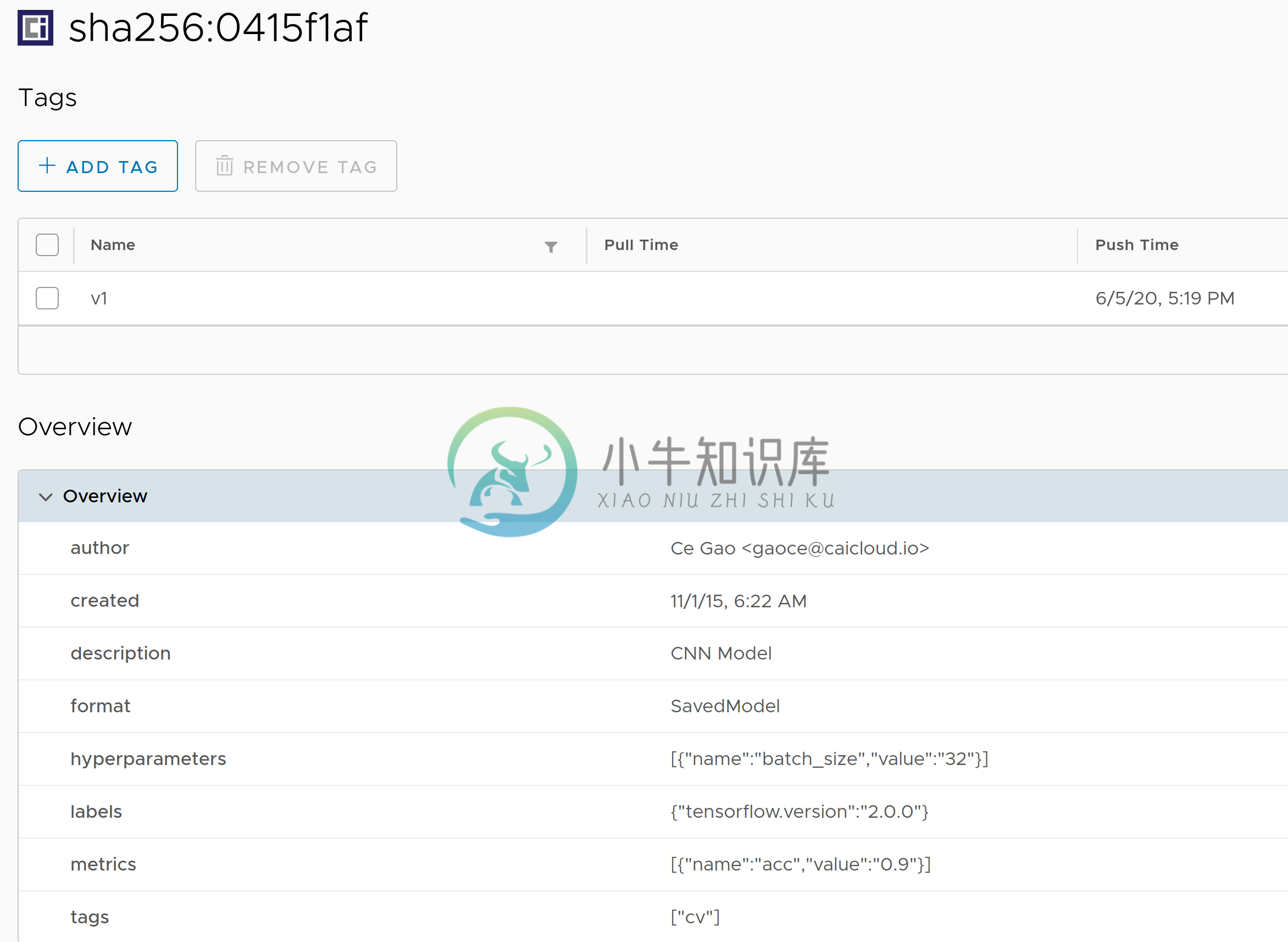
随后,我们可以在服务器上将模型下载下来,模型下载过程与推送到镜像仓库的方法类似:
# 从远端仓库拉取到服务器的本地缓存
$ ormb pull gaocegege/fashion_model:v1
v1: Pulling from gaocegege/fashion_model
ref: gaocegege/fashion_model:v1
digest: 6b08cd25d01f71a09c1eb852b3a696ee2806abc749628de28a71b507f9eab996
size: 162.1 KiB
Status: Downloaded newer model for gaocegege/fashion_model:v1
# 将本地缓存的模型导出到当前目录
$ ormb export gaocegege/fashion_model:v1
ref: localhost/gaocegege/fashion_model:v1
digest: 6b08cd25d01f71a09c1eb852b3a696ee2806abc749628de28a71b507f9eab996
size: 162.1 KiB
$ tree ./model
model
└── 1
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
2 directories, 3 files接下来,我们就可以利用 TFServing 将模型部署为 RESTful 服务,并利用 Fashion MNIST 数据集的数据进行推理:
$ tensorflow_model_server --model_base_path=$(pwd)/model --model_name=fashion_model --rest_api_port=8501
2020-05-27 17:01:57.499303: I tensorflow_serving/model_servers/server.cc:358] Running gRPC ModelServer at 0.0.0.0:8500 ...
[evhttp_server.cc : 238] NET_LOG: Entering the event loop ...
2020-05-27 17:01:57.501354: I tensorflow_serving/model_servers/server.cc:378] Exporting HTTP/REST API at:localhost:8501 ...
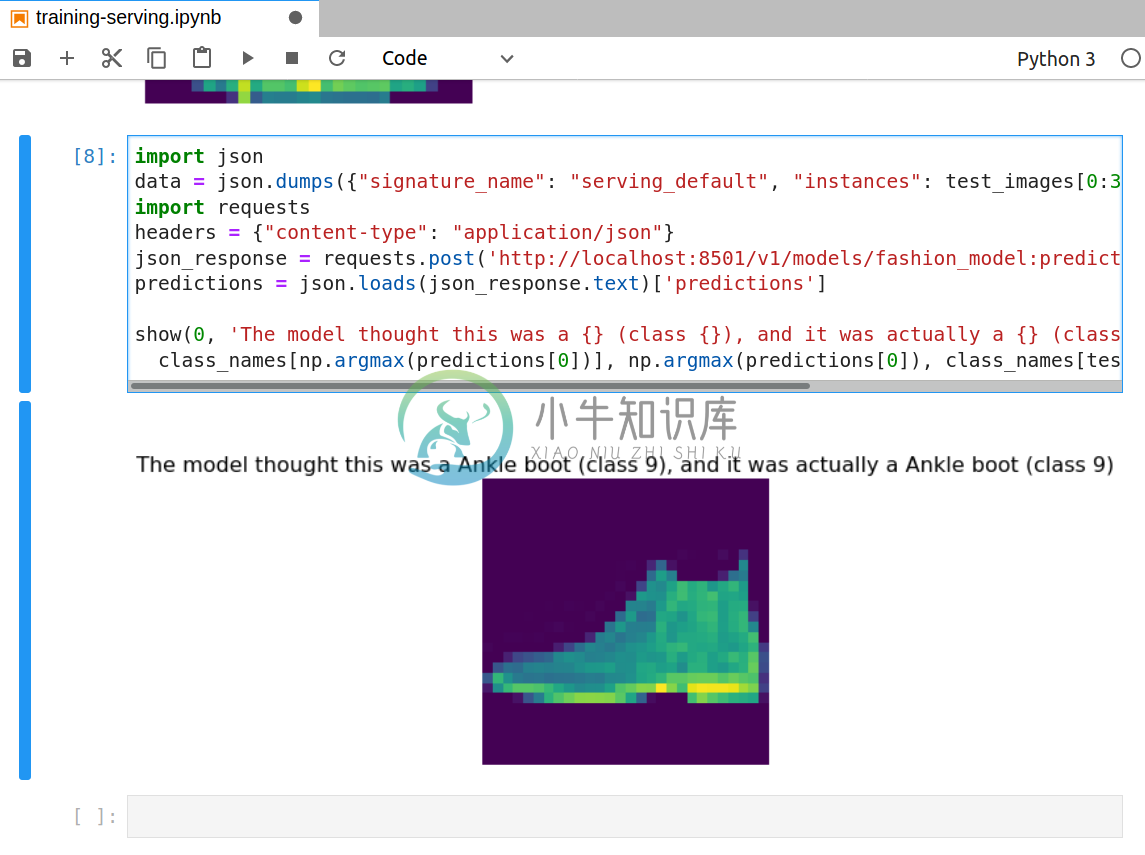
或者,我们也可以使用 Seldon Core 将模型服务直接部署在 Kubernetes 集群上,具体可以参见我们提供的文档:
apiVersion: machinelearning.seldon.io/v1alpha2
kind: SeldonDeployment
metadata:
name: tfserving
spec:
name: mnist
protocol: tensorflow
predictors:
- graph:
children: []
implementation: TENSORFLOW_SERVER
modelUri: demo.goharbor.io/tensorflow/fashion_model:v1
serviceAccountName: ormb
name: mnist-model
parameters:
- name: signature_name
type: STRING
value: predict_images
- name: model_name
type: STRING
value: mnist-model
name: default
replicas: 1算法工程师迭代新版本的模型时,可以打包新的版本,利用 ormb 拉取新的镜像后重新部署。ormb 可以配合任何符合 OCI Distribution Specification 的镜像仓库使用,这意味着 ormb 支持公有云上的镜像仓库和 Harbor 等开源镜像仓库项目。
我们也可以利用 Harbor 提供的 Webhook 功能,实现模型服务的持续部署。通过在 Harbor UI 中注册一个 Webhook,所有对 Harbor 的推送模型请求事件都会被转发到我们定义的 HTTP Endpoint 上。而我们可以在 Webhook 中实现对应的部署逻辑,比如根据新的模型来更新 Seldon 部署模型服务的版本,实现模型服务的持续部署等。
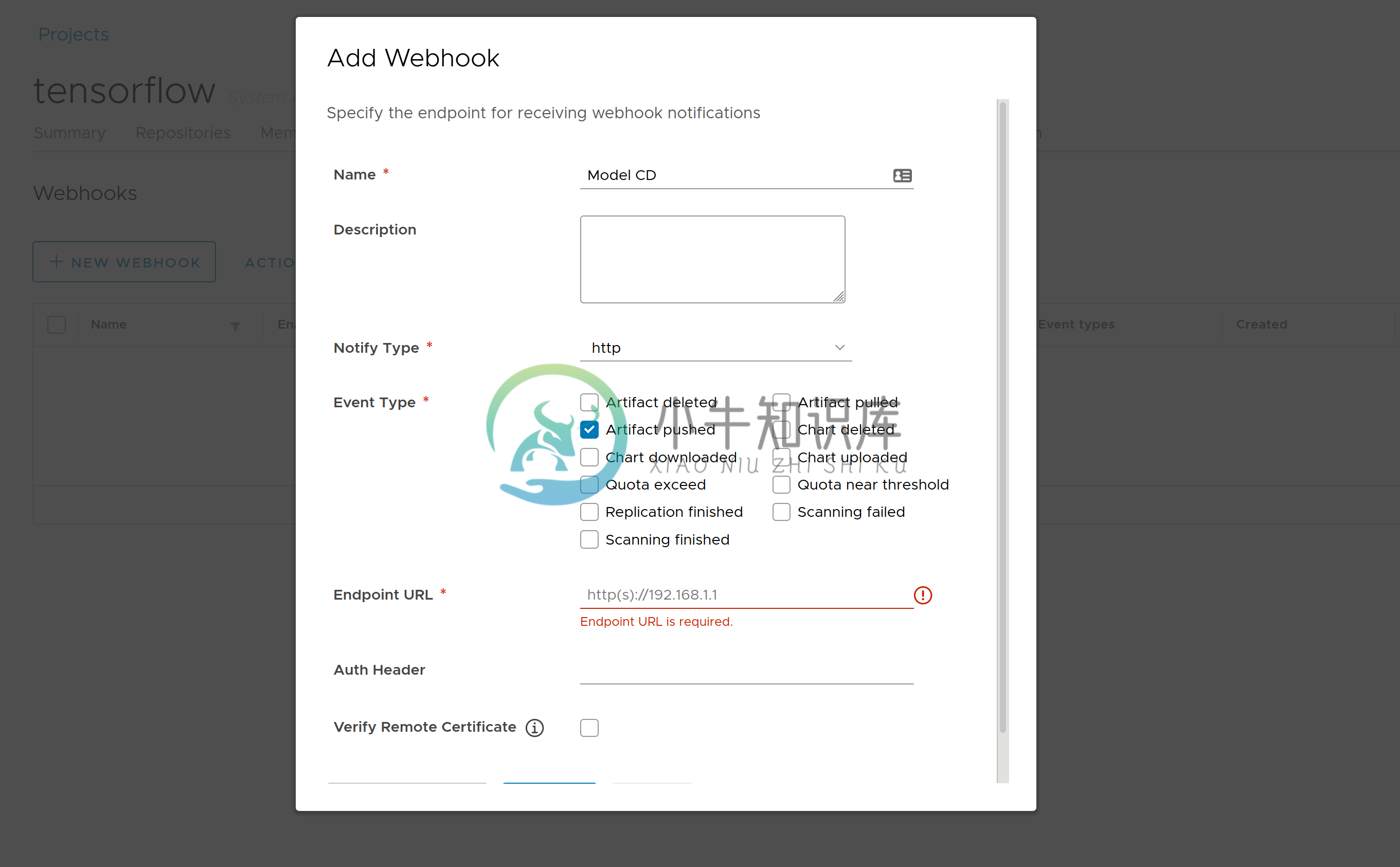
-
本文向大家介绍机器学习:知道哪些传统机器学习模型相关面试题,主要包含被问及机器学习:知道哪些传统机器学习模型时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 常见的机器学习算法: 1).回归算法:回归算法是试图采用对误差的衡量来探索变量之间的关系的一类算法。回归算法是统计机器学习的利器。 常见的回归算法包括:最小二乘法(Ordinary Least Square),逐步式回归(Stepwis
-
机器学习无疑是当前数据分析领域的一个热点内容。很多人在平时的工作中都或多或少会用到机器学习的算法。
-
机器学习原理
-
注: 内容翻译自 data model etcd设计用于可靠存储不频繁更新的数据,并提供可靠的观察查询。etcd暴露键值对的先前版本来支持不昂贵的快速和观察历史事件(“time travel queries”)。对于这些使用场景,持久化,多版本,并发控制的数据模型是非常适合的。 ectd使用多版本持久化键值存储来存储数据。当键值对的值被新的数据替代时,持久化键值存储保存先前版本的键值对。键值存储事
-
Python 有着海量的可用于数据分析、统计以及机器学习的库,这使得 Python 成为很多数据科学家所选择的语言。 下面我们列出了一些被广泛使用的机器学习及其他数据科学应用的 Python 包。 Scipy 技术栈 Scipy 技术栈由一大批在数据科学中被广泛使用的核心辅助包构成,可用于统计分析与数据可视化。由于其丰富的功能和简单易用的特性,这一技术栈已经被视作实现大多数数据科学应用的必备品了。
-
主要内容 前言 课程列表 推荐学习路线 数学基础初级 程序语言能力 机器学习课程初级 数学基础中级 机器学习课程中级 推荐书籍列表 机器学习专项领域学习 致谢 前言 我们要求把这些课程的所有Notes,Slides以及作者强烈推荐的论文看懂看明白,并完成所有的老师布置的习题,而推荐的书籍是不做要求的,如果有些书籍是需要看完的,我们会进行额外的说明。 课程列表 课程 机构 参考书 Notes等其他资
-
机器学习与人工智能学习笔记,包括机器学习、深度学习以及常用开源框架(Tensorflow、PyTorch)等。 机器学习算法 _图片来自scikit-learn_。 机器学习全景图 _图片来自http://www.shivonzilis.com/_。
-
机器学习与人工智能学习笔记,包括机器学习、深度学习以及常用开源框架(Tensorflow、PyTorch)等。