
SwooleWorker是基于swoole4开发的一款分布式长连接开发框架。
常驻内存,协程,分布式部署,横向扩容,无感知安全重启,高性能高并发,SwooleWorker可以广泛应用于云计算、物联网(IOT)、车联网、智能家居、网络游戏、互联网+、移动通信等领域。使用SwooleWorker可以使企业 IT 研发团队的效率大大提升,更加专注于开发创新产品。
_____ _ __ __ _ / ____| | | \ \ / / | | ® | (_____ _____ ___ | | __\ \ /\ / /__ _ __| | _____ _ __ \___ \ \ /\ / / _ \ / _ \| |/ _ \ \/ \/ / _ \| '__| |/ / _ \ '__| ____) \ V V / (_) | (_) | | __/\ /\ / (_) | | | < __/ | |_____/ \_/\_/ \___/ \___/|_|\___| \/ \/ \___/|_| |_|\_\___|_| ================================================= SwooleWorker is a distributed long connection development framework based on Swoole4. [Github] https://github.com/xielei/swoole-worker ================================================= Press [Ctrl+C] to exit, send 'help' to show help. > help **************************** HELP **************************** * cmd description... * help display help * exit exit cmd panel * clear clear screen * start [-d] start the service,'-d' daemonize mode * restart [-d] restart the service,'-d' daemonize mode * reload reload worker and task * stop [-f] stop the service,'-f' force stop * status displays the running status of the service **************************************************************** >
系统架构
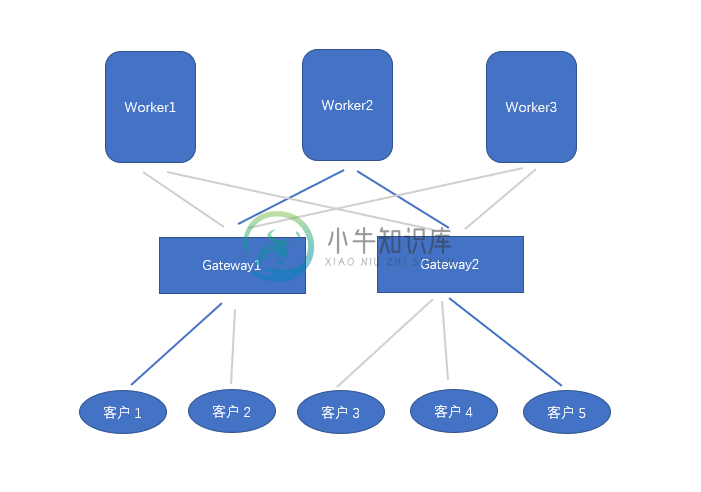
基本接口
- sendToClient(string client,stringclient,stringmessage)
- sendToUid(string uid,stringuid,stringmessage)
- sendToGroup(string group,stringgroup,stringmessage, array $without_client_list = [])
- sendToAll(string message,arraymessage,arraywithout_client_list = [])
- isOnline(string $client)
- isUidOnline(string $uid): bool
- getClientListByGroup(string group,stringgroup,stringprev_client = null): iterable
- getClientCount(): int
- getClientCountByGroup(string $group): int
- getClientList(string $prev_client = null): iterable
- getClientListByUid(string uid,stringuid,stringprev_client = null): iterable
- getClientInfo(string client,intclient,inttype = 255): array
- getUidListByGroup(string group,boolgroup,boolunique = true): iterable
- getUidList(bool $unique = true): iterable
- getUidCount(float $unique_percent = null): int
- getGroupList(bool $unique = true): iterable
- getUidCountByGroup(string $group): int
- closeClient(string client,boolclient,boolforce = false)
- bindUid(string client,stringclient,stringuid)
- unBindUid(string $client)
- joinGroup(string client,stringclient,stringgroup)
- leaveGroup(string client,stringclient,stringgroup)
- unGroup(string $group)
- setSession(string client,arrayclient,arraysession)
- updateSession(string client,arrayclient,arraysession)
- deleteSession(string $client)
- getSession(string $client): ?array
- sendToAddressListAndRecv(array items,floatitems,floattimeout = 1): array
- sendToAddressAndRecv(array address,stringaddress,stringbuffer, float $timeout = 1): string
- sendToAddress(array address,stringaddress,stringbuffer, $timeout = 1)
系统特色
- 分布式部署,横向扩容
- 代码更新无缝重启,用户无感知,数据无差错
- 协程,常驻内存,高性能
安装
推荐composer方式安装
composer require xielei/swoole-worker
-
我们已经成功地使用了MySQL - 使用jdbc独立连接器的kafka数据摄取,但现在在分布式模式下使用相同的连接器(作为kafka connect服务)时面临问题。 用于独立连接器的命令,工作正常 - 现在,我们已经停止了这一项,并以分布式模式启动了kafka connect服务,如下所示 2 个节点当前正在运行具有相同连接服务。 连接服务已启动并正在运行,但它不会加载 下定义的连接器。 应该对
-
我已经在ubuntu上安装了hadoop,它运行在VirtualBox上。当我第一次安装hadoop时,我可以毫无问题地启动hdfs和创建目录。 但是当我重新启动虚拟机后,当尝试在HDFS上运行ls命令时,我得到了“拒绝连接”的错误。然后,我根据Hadoop集群设置在sshd_config中添加了“端口9000”-java.net.connectException:Connection Relec
-
我正在开发debezium mongodb源连接器。我可以通过提供kafka引导服务器地址作为远程机器(部署在Kubernetes中)和远程MongoDB URL在分布式模式下在本地机器中运行连接器吗? 我尝试了这一点,我看到连接器成功启动,没有错误,只有几个警告,但没有数据从MongoDB流动。 使用以下命令运行连接器 遵循以下教程:https://medium.com/tech-that-wo
-
一、MapReduce概述 Hadoop MapReduce 是一个分布式计算框架,用于编写批处理应用程序。编写好的程序可以提交到 Hadoop 集群上用于并行处理大规模的数据集。 MapReduce 作业通过将输入的数据集拆分为独立的块,这些块由 map 以并行的方式处理,框架对 map 的输出进行排序,然后输入到 reduce 中。MapReduce 框架专门用于 <key,value> 键值
-
Dubbo 是阿里巴巴公司开源的一个Java高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring框架无缝集成。不过,略有遗憾的是,据说在淘宝内部,dubbo由于跟淘宝另一个类似的框架HSF(非开源)有竞争关系,导致dubbo团队已经解散(参见http://www.oschina.net/news/55059/druid-1-0-9 中的评论),反到是
-
类型 实现框架 应用场景 批处理 MapReduce 微批处理 Spark Streaming 实时流计算 Storm