
kvstore 一种用C++实现的高性能的基于proxy进行分片的redis集群解决方案。
架构:
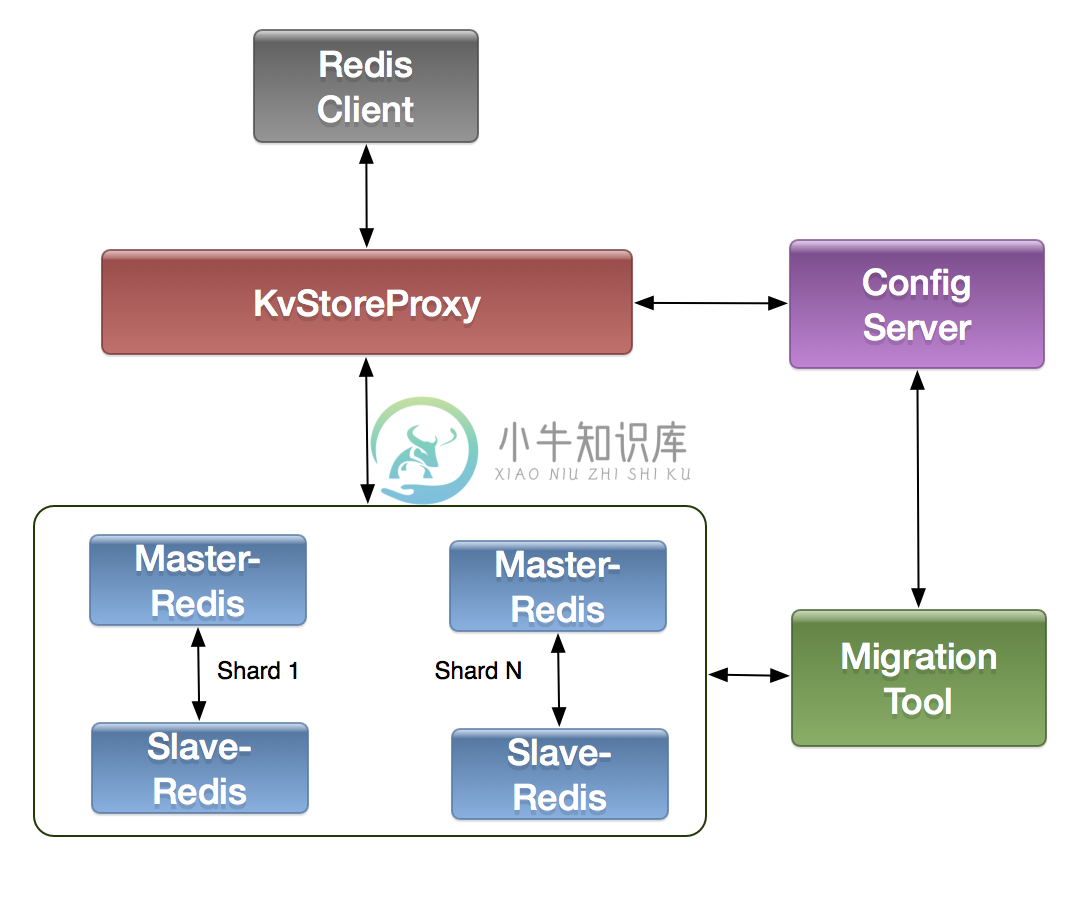
特性:
-
多线程处理客户端请求
-
管道支持
-
重新分片而不重新启动集群
-
支持大多数redis命令,有关详细命令,请参见not-support-redis-cmd
-
支持两种模式:
- cache模式
-用作纯缓存,具有Redis分片,但无复制,因此可以节省一半内存。为了实现高可用性,Redis节点将在失败时从分片节点中删除
- data-store模式
-用作数据源,具有redis分片和复制功能。为了实现高可用性,当旧的主节点发生故障时,从属Redis节点将升级为主节点
-
前言 此工具主要是作用是针对ceph中各种kv存储进行操作和展示的工具. 先看一下help列表 [root@test-1 ceph]# ceph-kvstore-tool --help Usage: ceph-kvstore-tool <leveldb|rocksdb|bluestore-kv> <store path> command [args...] Commands: list [pr
-
在splunk中KV Store提供了一种方法可以用来保存并恢复数据。 KV Store的工作机制: 将数据以键值对的形式存储在collection中。 Collection:由一条条数据记录组成的一个容器,类似于数据库中的表。 Collection中的Key类似于数据库表中的列名。 列举一些常用的collection相关的命令: #创建collection curl -k -u admin:ad
-
ceph-kvstore-tool 使用说明 参考链接: https://github.com/ceph/ceph/blob/master/doc/man/8/ceph-kvstore-tool.rst http://www.idcat.cn/ceph-kvstore-tool%E5%B7%A5%E5%85%B7%E7%AE%80%E5%8D%95%E4%BB%8B%E7%BB%8D.html h
-
最近kvstore 很不稳定,一次三个同组的searh head 出现"starting" 的状态,当我用splunk show kvstore-status 检查的时候。 检查log: 1: /opt/spunk/var/log/splunkd.log 当时: https://abc.com:8089是captain (splunk show shcluster-status) 05-25-20
-
Note: the project:kvstore_example is just a demo, no performance, no crash recovery, no reliability. env: Linux/java8 build: mvn clean install start kvstore start example cd kvstore_admin/kv_store_adm
-
Tendermint abci 项目主页 这篇文章以 ABCI 示例 KVStore 应用及默认的 socket 连接为例说明 ABCI 应用的启动及 abci-cli 客户端与其交互的过程,以加深开发 ABCI 应用的模式及源码组织方式的理解。 整体流程说明 ABCI 应用服务端:在命令行执行 abci-cli kvstore 启动应用后,它会在 46658 端口等待客户端的 TCP 连接。 a
-
0 简介 Ceph是一个复杂的分布式存储系统,有很多组件组成,不光学习成本比较高,而且运维难度也是相当的大。但近几年,它却很受大家的欢迎,越来越多的互联网企业开始采用ceph来构建自己的存储。这是为什么呢?我想源自于它优秀的设计、规范的项目管理以及活跃的社区。Ceph本身提供了很多工具(之所以称它们为高级工具,是因为要使用它们必须对Ceph有较为深入的理解),它们在处理Ceph故障时,非常有用,接
-
创建了一个注解 KVIndex。 感觉上应该是这样子的: 有一个数据库: KVStore, 里面存了好多好多数据,这些数据都是某一种类型的,数据一个类的实例就相当于一条记录,一个类就相当于一个表。 KVIndex 就是给某个表添加索引。 比如单元测试里面ArrayKeyIndexType,就存储在KVStore里面,一个数据库里面有了一张ArrayKeyIndexType的表。 这个表的某些字段需
-
KVstore对比文章 http://blog.csdn.net/cadem/article/details/72516810?locationNum=8&fps=1
-
Redis键迁移 在使用Redis的过程中,很多时候我们会遇到需要进行键迁移的问题,需要将指定Redis中的指定数据迁移到其他Redis当中,键迁移有三种方法,我们来进行一一介绍。 一、move move key db move命令由于在Redis内部进行数据迁移,Redis内部可以有多个数据库,彼此在数据上相互隔离,move key db就是把指定的键从源数据库移动到目标数据库当中,但是不建
-
前言: 最近生产环境出现一个异常,设备系统卡一天写入量达到270多G,这样的压力下一个系统卡使用不了多久就会挂掉。os组同事使用blacktrace命令发现系统卡上有一个进程名称为rocksdb的进程在频繁的刷入数据,直接咬定这270G数据是我们ceph写入的。最终发现,ceph mon的数据库是放在系统卡里的,为了有效卸锅,特地调研了一下该工具(这个工具好像默认是不装的,需要单独安装一下) 首先
-
问题内容: 在启动时,我正在为我们的数据库考虑扩展解决方案。MySQL至少使我感到困惑(至少对我而言),MySQL具有MySQL群集,复制和MySQL群集复制(来自5.1.6版),它是MySQL群集的异步版本。MySQL手册解释了其集群FAQ中的一些差异,但是很难确定何时使用它们中的一个。 我将不胜感激那些熟悉这些解决方案之间的区别以及优点和缺点以及何时建议使用每种解决方案的人的任何建议。 问题答
-
本文向大家介绍socket.io与pm2(cluster)集群搭配的解决方案,包括了socket.io与pm2(cluster)集群搭配的解决方案的使用技巧和注意事项,需要的朋友参考一下 socket.io与cluster 在线上系统中,需要使用node的多进程模型,我们可以自己实现简易的基于cluster模式的socket分发模型,也可以使用比较稳定的pm2这样进程管理工具。在常规的http服务
-
null 哪些管理费用?正如我所知,您可以黑ElasticSearch通过内部TCP API而不是REST与他通信。还有其他管理费用吗?它们只关于复制(您可以关闭初始加载复制)吗?或者关于索引自动合并?也许是由于ElasticSearch试图自动合并索引,并使它们变得如此之大,以至于不能支持FS缓存? 为什么Lucene API更灵活?AFAIK,ElasticSearch有所有相同的索引和其他特
-
软件介绍: 这是由北邮学生所开发的一个服务器集群解决方案,软件实现。实际上这是系列软件的第一个版本,纯为练手,但绝对可用。 按照系统提示安装后会安装一个高可用的6机以上服务器集群,包括两个负载均衡节点,两个数据库节点和多个WEB节点,安装比较复杂建议安装时与开发人员联系一下,QQ:330504591,并确认联网安装 开发和测试时都是使用了ubuntu12.04系统,所以建议在几台空的ubuntu1
-
我有两个ActiveMQ Artemis实例,只需使用命令/.Artemis创建Artemis/server1和 /.Artemis创建Artemis/server2 以下是服务器1的broker.xml: 下面是服务器2的broker.xml: 同样在server2中,Bootstrap.xml中的更改更改了web绑定端口 我正在用StaticClusteredQueueExample和这个示例
-
我们有一个与hawtio集成的camel应用程序,并部署在openshift环境中。这个应用程序已经被扩展成两个pod,并通过openshift路由向外界公开。 因此,通过 hawtio 致动器 url,当我们在运行时更改骆驼路由时,它已反映在任一 pod 上,而不是在两者中。我们正在寻找一种解决方案,我们可以通过hawtio url更新两个豆荚上的骆驼路线。 有人面临类似的问题吗?请提供建议。
-
本文向大家介绍详解nginx惊群问题的解决方式,包括了详解nginx惊群问题的解决方式的使用技巧和注意事项,需要的朋友参考一下 对于nginx的惊群问题,我们首先需要理解的是,在nginx启动过程中,master进程会监听配置文件中指定的各个端口,然后master进程就会调用fork()方法创建各个子进程,根据进程的工作原理,子进程是会继承父进程的全部内存数据以及监听的端口的,也就是说worker
-
本文向大家介绍MySQL slave_net_timeout参数解决的一个集群问题案例,包括了MySQL slave_net_timeout参数解决的一个集群问题案例的使用技巧和注意事项,需要的朋友参考一下 【背景】 对一套数据库集群进行5.5升级到5.6之后,alter.log 报warning异常。 数据库业务压力 qps 1 tps 几乎为0 4-10 秒或者更久会有写入操作