
SequoiaSQL 是巨衫数据库开源的一个分布式 SQL 存储引擎,目前支持 SequoiaDB 3.0 作为后端数据库,并计划扩展到多个数据库,如 MongoDB/Redis 等。
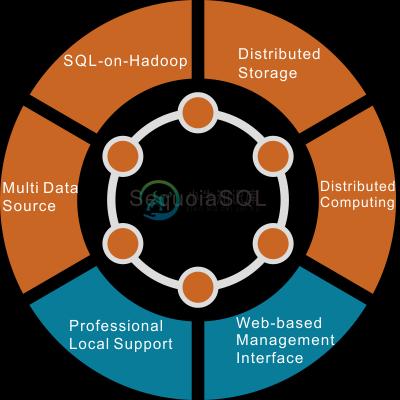
SequoiaSQL 此前是 SequoiaDB 数据库的 SQL 解析模块,在经过 1.0~3.0 的发展,SequoiaSQL 组件也实现了 PostgreSQL、MySQL 的兼容。在未来,还会实现 MairaDB 的兼容支持,并且实现更多存储引擎的兼容对接。
Building
1.下载 boost-1.59.0 和 mysql-5.7.18.
2.将组件代码复制到存储目录
# mkdir -p mysql-5.7.18/storage/sequoiadb # cp sequoiasql-mysql/* mysql-5.7.18/storage/sequoiadb
3.构建组件
# cd mysql-5.7.18 # cmake . -DWITH_BOOST=../thirdparty/boost/boost_1_59_0/ -DCMAKE_INSTALL_PREFIX=/opt/mysql -DMYSQL_DATADIR=/opt/mysql/data -DWITH_SDB_DRIVER=/opt/sequoiadb -DCMAKE_BUILD_TYPE=Release # make -j 4 # make install
-
【sequoiadb|巨杉数据库】SequoiaSQL 概述 SequoiaDB 采用计算存储分离架构,SequoiaSQL 是 SequoiaDB 的 SQL 层计算引擎。SequoiaSQL 作为数据库实例的统称,支持以下四种关系型数据库实例,并且完全兼容4种SQL访问形式。 支持数据库实例类型 可创建实例 MySQL SequoiaSQL-MySQL 实例 PostgreSQL Sequoi
-
SequoiaSQL 和 Spark 的安装配置放在在这里不赘述。 Thrift server 最好是配合 Hive 元数据库使用。所以这里讲一下如何配置,并启动 Thrift server ,最后可以用 beeline 命令行比较方便清爽的使用 Spark SQL 。下面是配置步骤。 1. Postgresql JDBC 驱
-
Sequoiadb是支持sql的,SequoiaSql是解析sql语言,Sequoiadb来执行SequoiaSql解析出的语言并执行相关命令,SequoiaSql相当于客户端,Sequoiadb相当于后端。用户可以通过JDBC驱动连接SequoiaSql进行应用程序开发。 之前的文章介绍了Sequoiadb对接SequoiaSql应用开发实践,本文将介绍更加简单的一种方式进行对接
-
一面 11.1 分布式存储 阿里天池比赛,问了一些模块的优化 问存储项目 问TinyKV 项目 操作系统:cpu cache,false sharing,gdb C++:移动语义,std::map,rbtree和b+tree区别。 perf 观察程序性能 算法题:二叉树的路径和 二面 11.2 leader 面 开局先选方向:DB,分布式,操作系统,体系结构,计算机网络。选了分布式,狂问raft
-
之前的秋招面经:深信服 Go 开发面经(已 offer) bg:专升本+ACM银牌+三个项目(一个毕设的KV分离LSM-Tree,一个6824的分布式KV,一个OJ) 某小厂,存储方向技术积累还不错,避免定位就不写具体名字了。自己也一直比较憧憬做 infra 吧,不想写 CRUD 业务,所以就投了。面试内容都是事后回忆,可能有遗漏或记错的 一面 50min 自我介绍 项目实现细节、设计考量、优化(
-
一、介绍 HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。 二、HDFS 设计原理 2.1 HDFS 架构 HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成: NameNode : 负责执行有关 文件系统命名空间 的操作,例如打开,
-
问题内容: 我正在寻找Java分布式缓存解决方案。我们希望功能喜欢: 我们已经分析了Terracotta这样的框架,它似乎是缓存框架中我们想要的一切……但是,似乎需要一个中央缓存节点,这成为我们的单点故障。 除了推出我们自己的解决方案之外,还有其他想法吗? 问题答案: 我建议使用JBossCache或EhCache(使用分布式缓存侦听器)。我都用过,我都喜欢,它们都适合您的要求。
-
我们已经使用Drools引擎几年了,但是我们的数据已经增长了,我们需要找到一个新的分布式解决方案来处理大量数据。我们有复杂的规则,可以查看几天的数据,这就是为什么Drools非常适合我们,因为我们的内存中只有数据。 你对类似于流口水但分布式/可扩展的东西有什么建议吗? 我确实对这件事进行了研究,但我找不到任何符合我们要求的东西。 谢谢
-
Web 应用程序可能需要为成百上千甚至更多的用户同时提供服务。如果你没有采取必要的措施,在这种负载下,你的网站可能会崩溃或变得没有响应。 假设在主页显示最后 10 条新闻,并且平均每分钟有上千名用户访问此页面。你可能为每个用户通过查询数据库来显示页面视图信息: SELECT TOP 10 Title, NewsDate, Subject, Body FROM News ORDER BY NewsD