
Annoy 是 Spotify 开源的高维空间求近似最近邻的库,在 Spotify 使用它进行音乐推荐。最邻近搜索(Nearest Neighbor Search, NNS)又称为“最近点搜索”(Closest point search),是一个在尺度空间中寻找最近点的优化问题。
Annoy 能够使用静态文件作为索引,意味着可以跨进程共享索引。它还创建了大量的基于只读文件的数据结构,这些数据结构被嵌入内存中,以便许多进程可以共享相同的数据。Annoy 的另一个好处是它试图最小化内存占用,因此索引非常小。
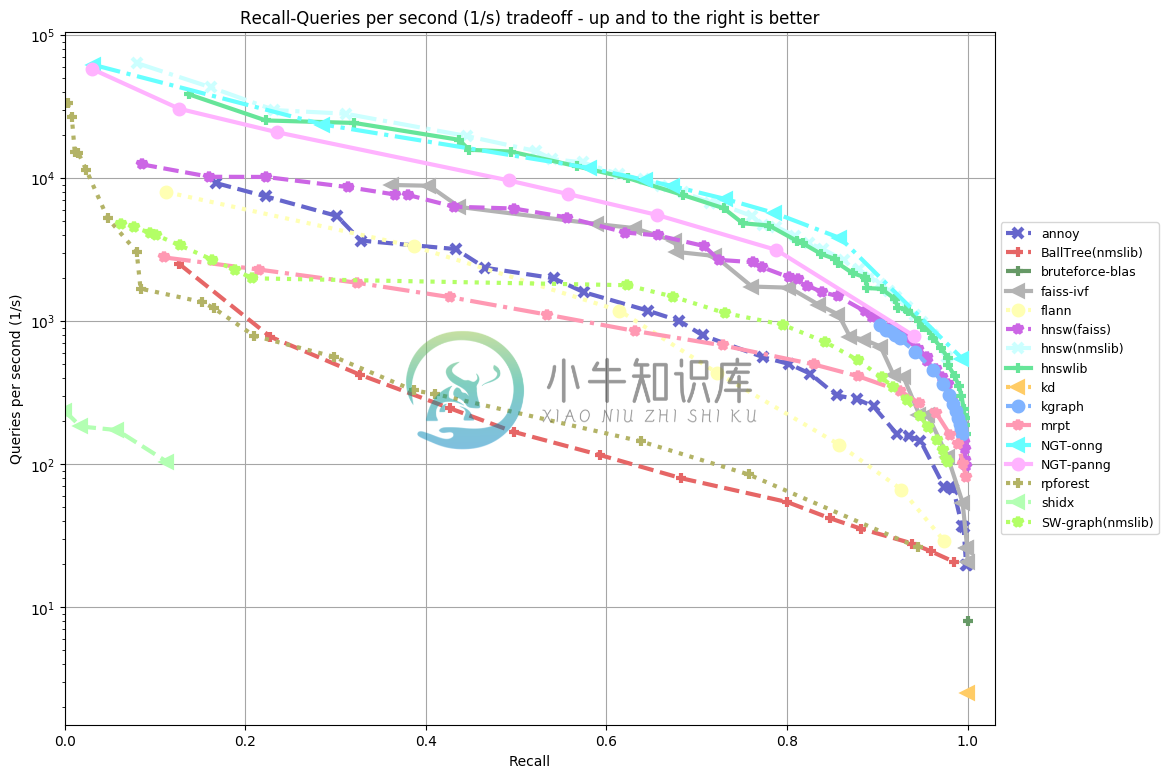
特性:
- 欧几里德距离, 曼哈顿距离, 余弦距离, 汉明距离或 点(内)积距离
- 余弦距离等价于归一化向量的欧氏距离=sqrt(2-2*cos(u,v)
- 如果你的维度不多(比如<100),效果会更好,即使达到 1000 个维度,它也表现得非常出色
- 内存使用量小
- 允许你在多个进程之间共享内存
- 索引创建与查找是分开的(特别是在创建树后,就无法添加更多项目)
- 原生 Python 支持
- 在磁盘上生成索引,以便为不适合内存的大型数据集建立索引
-
annoy 是 高维空间求近似最近邻的框架,速率快,轻便实用。 GitHub地址:https://github.com/spotify/annoy 配合腾讯词向量,可以快速查找语义接近的向量: tencent_annoy_index = AnnoyIndex(self.size,metric='angular') #存储 tencent_annoy_index.add_item(index, qu
-
annoy 是我需要安装目标 package 的一个依赖包,每次安装都发生报错,因此单独拎出来手动安装。 直接通过 pip install annoy 发生报错:error: command 'gcc' failed with exit status 1,这种报错很可能是因为 gcc 库版本过低造成,仅通过 pip install annoy 无法自动更新 gcc 库,之后尝试另外几种方式安装 a
-
校验者: @DataMonk2017 @Veyron C @舞空 翻译者: @那伊抹微笑 sklearn.neighbors 提供了 neighbors-based (基于邻居的) 无监督学习以及监督学习方法的功能。 无监督的最近邻是许多其它学习方法的基础,尤其是 manifold learning (流行学习) 和 spectral clustering (谱聚类)。 neighbors-bas
-
我在计算最近的邻居。为此,我需要传递一个参数来限制与邻居的最大距离。比如半径1000米内最近的邻居是哪些? 我做了以下工作: 我用以下数据创建了我的表: 之后,我执行了以下查询: 第一个问题,巴西的SRID是4326吗?4269是什么? 第二个问题,通过执行以下SQL 这不会返回任何结果。据我所知,这个SQL将进一步指出最大距离的半径,对吗? 如果你把1000个结果放在100000000,我的所有
-
介绍 KNN算法全名为k-Nearest Neighbor,就是K最近邻的意思。KNN 也是一种分类算法。但是与之前说的决策树分类算法相比,这个算法算是最简单的一个了。算法的主要过程为: 1、给定一个训练集数据,每个训练集数据都是已经分好类的。 2、设定一个初始的测试数据a,计算a到训练集所有数据的欧几里得距离,并排序。 3、选出训练集中离a距离最近的
-
k近邻(k-Nearest Neighbors)采用向量空间模型来分类,是一种常用的监督学习方法。它的工作原理为:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个“邻居”的信息来进行预测。通常,在分类任务中可使用“投票法”,即选择这k个样本中出现最多的类别标记作为预测结果;在回归任务中可使用“平均法”,即将这k个样本的实值输出标记的平均值作为预测结果;还可基于距离
-
@subpage tutorial_py_knn_understanding_cn 了解kNN的基本知识。 @subpage tutorial_py_knn_opencv_cn 现在让我们在OpenCV中使用kNN进行数字识别(OCR)
-
问题内容: 应用程序如何执行邻近搜索?例如,用户输入邮政编码,然后应用程序按距离排序列出20英里内的所有企业。 我想在PHP和MySQL中构建类似的东西。这种方法正确吗? 获取我感兴趣的位置的地址并将其存储在数据库中 使用Google的地理编码服务对所有地址进行地理编码 编写包含Haversine公式的数据库查询以进行邻近搜索和排序 这个可以吗?在第3步中,我将计算每个查询的接近度。有一个PROX
-
主要内容:KNN算法原理,KNN算法流程,KNN预测分类本节继续探机器学习分类算法——K 最近邻分类算法,简称 KNN(K-Nearest-Neighbor),它是有监督学习分类算法的一种。所谓 K 近邻,就是 K 个最近的邻居。比如对一个样本数据进行分类,我们可以用与它最邻近的 K 个样本来表示它,这与俗语“近朱者赤,近墨者黑”是一个道理。 在学习 KNN 算法的过程中,你需要牢记两个关键词,一个是“少数服从多数”,另一个是“距离”,它们是实现 KN
-
一些async fn状态机可以安全地越过线程发送,而其他则不能。判断一个async fn Future是不是Send,由非Send类型是否越过一个.await据点决定的。当可以越过了.await据点,编译器会尽力去估计这个是/否。但是今天的许多地方,这种分析都太保守了。 例如,考虑一个简单的非Send类型,也许包含一个Rc: use std::rc::Rc; #[derive(Default)]