
UIMA C++ 框架产生的目的是为了构建一个 UIMA 兼容的 C++ 分析引擎,该 UIMACPP SDK 直接支持 C++ 编程语言,并间接支持 Perl、Python、Tcl 语言。
该项目目前还是 Apache 组织的一个孵化项目。
UIMA 是非结构化信息管理体系结构(Unstructured Information Management Architecture,UIMA)在字处理文档、电子邮件、视频和其他非结构化信息中搜索特定的文本甚至概念。从而发现、组织和传送有用的知识给客户。在分析非结构化的信息的过程中,应用的算法有统计的方法、基于规则的自然语言处 理(NLP)、信息修复(IR)、机器学习(Machine Learning)和本体论(Ontologies)等。IBM的UIMA 就是一种Framework,该Frmaework便于开发者实现、描述、组合、布署UIMA的组件和应用。
-
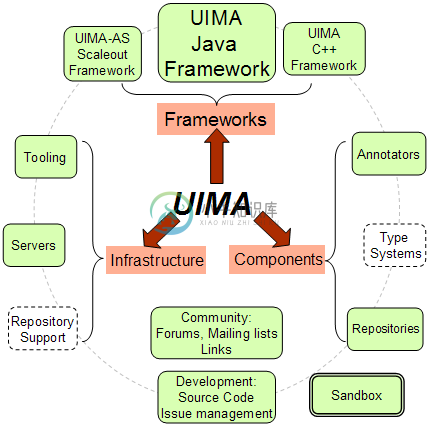
UIMA (Unstructured Information Management applications) 是一个软件系统,用来分析大量的非结构化信息从而发掘中对最终用户有用的知识点,一个最典型的 UIM 应用就是从文本文件中提取有用信息,例如人员、地址和组织等相关信息。 下面是 UIMA 的结构图: 在线参考文档:http://tool.oschina.net/apidocs/apidoc?api=uima
-
UIMA Java 框架产生的目的是为了构建一个 UIMA 兼容的 Java 分析引擎。 UIMA 是非结构化信息管理体系结构(Unstructured Information Management Architecture,UIMA)在字处理文档、电子邮件、视频和其他非结构化信息中搜索特定的文本甚至概念。从而发现、组织和传送有用的知识给客户。在分析非结构化的信息的过程中,应用的算法有统计的方法、
-
网站是否具有吸引力对于访客的回头率具有非常重要的促进作用,从吸引力分析中了解访客喜好,增加网站吸引力从而提升用户粘性。
-
主要内容:一、InnoDB启动,二、源码分析,三、总结一、InnoDB启动 在MySql中,InnoDB的启动流程其实是很重要的。一些更细节的问题,就藏在了这其中。在前面分析过整个数据库启动的流程,本篇就具体分析一下InnoDB引擎启动所做的各种动作。在这期间,分析一下对数据库索引的处理过程。在前面的分析中已经探讨过,今天重点分析一下数据引擎的启动和加载流程。 在MySql中,方向是朝着插件化发展,所以InnoDB本身也是做为一个插件进行引用的。通过
-
本文向大家介绍深入分析PHP引用(&),包括了深入分析PHP引用(&)的使用技巧和注意事项,需要的朋友参考一下 引用是什么 在 PHP 中引用意味着用不同的名字访问同一个变量内容。这并不像 C 的指针,替代的是,引用是符号表别名。注意在 PHP 中,变量名和变量内容是不一样的,因此同样的内容可以有不同的名字。最接近的比喻是 Unix 的文件名和文件本身——变量名是目录条目,而变量内容则是文件本身。
-
我用cmd删除了映射 在我的配置文件中,我定义了如下索引:, 并尝试创建一个新的映射,但我得到了错误 {“error”:{“root_cause”:[{“type”:“index_not_found_exception”,“reason”:“no-this index”,“resource.type”:“index_or_alias”,“resource.id”:“logstash_log*”,“