
Kache缓存框架专注于优化高IO的Web应用中数据持久化层次的读写性能,并保证数据实时性,提高缓存数据库的空间利用率。
Kache强调业务与缓存解耦,通过方法为粒度进行动态代理实现旁路缓存,内部拥有特殊的参数编码器,屏蔽键值编码细节,以四个基本的CRUD注解和Status枚举或方法名匹配的形式对Kache表达方法的作用而面向抽象实现自动化处理。
Kache的缓存实现为Guava Cache+Redis+Lua,减少网络IO的消耗,且缓存分为索引缓存+元缓存,并在缓存存入时进行"Echo"操作,仅将尚未空缺的缓存存入而减少重复的序列化。在集中于热点的大数据量场景下,可以做到“接近无序列化程度”的缓存存入。
Kache适用广泛,组件实现都面向抽象,默认的实现都可以通过在Kache通过建造者模式时填入自定义的组件进行替换,可以做到MongoDB、IndexDB甚至是MySQL的缓存实现。并且提供额外的策略接口,允许用户对分布式、单机等环境进行对应的策略实现。
使用
该Kache为原生JDK进行组件管理以支持Kotlin或scala等jdk语言使用,若是使用Spring框架请移步至:https://gitee.com/Kould/kache-spring
1、Kache依赖引入
2、Kache代理
3、Dao层写入注解
示例:
1.pom文件引入:
<dependency> <groupId>io.gitee.kould</groupId> <artifactId>Kache</artifactId> </dependency>
2.对Mapper进行Kache的代理
Kache kache = Kache.builder().build(); // 需要对Kache进行init与destroy以保证脚本的缓存载入与连接释放 kache.init(); kache.destroy(); // 对Mapper进行动态代理,获取到拥有缓存旁路功能的新Mapper // 示例: ArticleMapper proxy = kache.getProxy(articleMapper, Article.class);
3.其对应的Dao层的Dao方法添加注释:
- 持久化方法注解:@DaoMethod
- Type:方法类型:
- value = Type.SELECT : 搜索方法
- value = Type.INSERT : 插入方法
- value = Type.UPDATE : 更新方法
- value = Type.DELETE : 删除方法
- Status:方法参数状态 默认为Status.BY_Field:
- status = Status.BY_FIELD : 非ID查询方法
- status = Status.BY_ID : ID查询方法
- Class<?>[] involve:仅在Type.SELECT Status.BY_Field时生效:用于使该条件搜索方法的索引能够被其他缓存Class影响
- Type:方法类型:
@Repository public interface TagMapper extends BaseMapper<Tag> { @Select("select t.* from klog_article_tag at " + "right join klog_tag t on t.id = at.tag_id " + "where t.deleted = 0 AND at.deleted = 0 " + "group by t.id order by count(at.tag_id) desc limit #{limit}") @DaoMethod(value = Type.SELECT,status = Status.BY_FIELD) // 通过条件查询获取数据 List<Tag> listHotTagsByArticleUse(@Param("limit") int limit); @DaoMethod(Type.INSERT) // 批量新增方法(会导致数据变动) Integer insertBatch(Collection<T> entityList); }
自定义配置或组件:
// 以接口类型作为键值替换默认配置或增加额外配置 // 用于无额外参数的配置或组件加载 load(Class<?> interfaceClass, Object bean); // 示例:注入MyBatis-Plus的包装类对象Page的PageDetails对象 private final Kache kache = Kache.builder() .load(PageDetails.class, new PageDetails<>(Page.class, "records", List.class)) .build();
原理 | Principle
Kache的原型的描述文章:
基于上述文章的主要变化为:
代理对象的转移:
Service层缓存对于Dao层缓存来说产生一个问题:
- 缓存更新问题:Service支持DTO概念时,针对有一种PO却产生有不同的形态的缓存,最容易导致的问题是缓存删除、更新、新增时带来的一致性问题,对于PO结果有Page类对象封装的缓存更甚,对于缓存的利用率较低
而Dao缓存则能够去弥补上面所述的问题,是高性能的缓存所必不可少的
但于此同时Dao又会导致一系列实际开发上的问题
- 标准Dao的开发并不偏向业务化、不符合原先缓存Key逻辑
- Dao层有着一系列持久层框架带来的默认实现,难以对其命名规范的同一化
- Service层对Dao层耦合大、Dao的修改对系统稳定性是致命性的
可见与原先的缓存设计有着很大的冲突
于是使用了两层的AOP:
- ServiceAop获取Service方法信息摘要、通过ThreadLocal传递给DaoAop
- DaoAop获取Service层方法进行编码为Key,使用Key获取缓存的结果
以此避免同一Service方法下调用同一Dao方法但不同参数而引起的缓存冲突问题
Aop转变为框架:
- 主要通过注解的形式+切点的形式提供更好的兼容性
- 注解提高代码的可读性,且可以应对多种不同包名的这种细节性问题
- 一些框架的默认实现无法修改代码,则可以通过默认提供的切点来修改包名而兼容
- 降低对原项目的耦合,使更多第三方项目也能使用上
- 修复原本设计带来的一系列不足点的耦合问题
- 通过注解降低其业务代码侵入性,并简化使用
二级缓存设计:
- 即使是NoSQL所带来的提升也仍然会导致网络IO的占用,为了更多的性能提升以及无用IO损耗则加入了进程间缓存的概念。
- 使用了二级缓存调度器,允许用户通过自定义二级缓存调度器去调度两个缓存的使用。
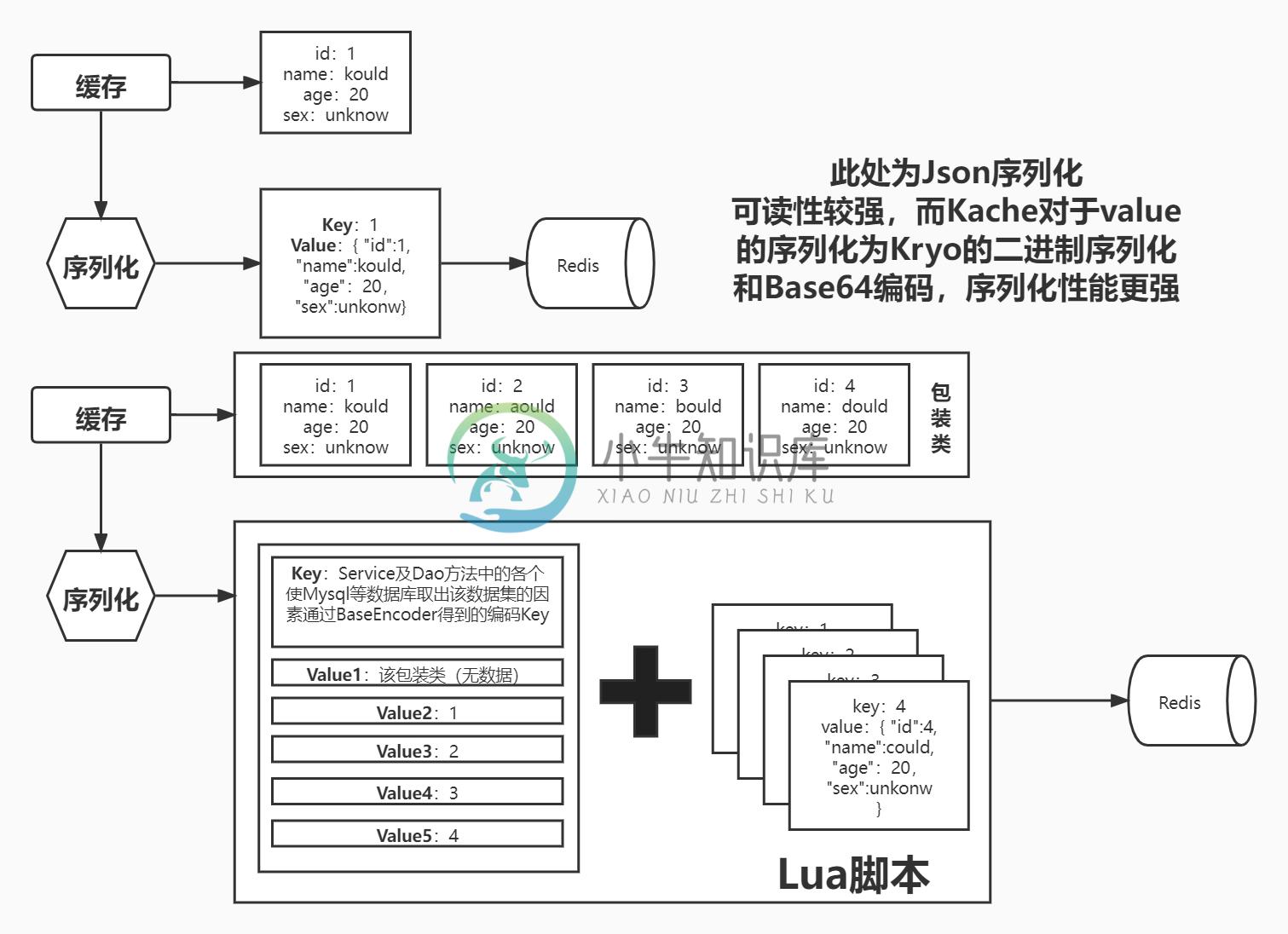
缓存散列化:
- 通过解析结果的持久类数据集,将持久类数据拆分并分别储存,将原包装类除去数据集后与数据集装填入List类型存入,去除实体数据与缓存索引的直接耦合
- 使实体数据原子化,加强数据一致性
- 减少缓存值重复,提高缓存的空间利用率
- 更直观观察到热点数据
- 散列开的单一持久化类有利于id查找
- Kache提供有KacheConfig.Status.BY_ID的状态属性用于标记直接id搜索,而实际的查找流程往往为:分页查询-》单一数据查询
- 如百度中搜索某一关键词后,点击其中提供内容中的一条。
- 散列化可以使在如上种情景下,不存在该关键词的缓存时,获取其分页数据时保存其单一实体缓存,使第二步的单一数据时必定命中缓存(点击其分页内容下),提高其缓存命中率且更加符合实际的应用场景
缓存结构:
-
和RDD相似,DStreams也允许开发者持久化流数据到内存中。在DStream上使用persist()方法可以自动地持久化DStream中的RDD到内存中。如果DStream中的数据需要计算多次,这是非常有用的。像reduceByWindow和reduceByKeyAndWindow这种窗口操作、updateStateByKey这种基于状态的操作,持久化是默认的,不需要开发者调用persist(
-
问题内容: 题 我正在寻找Java内存对象缓存API。有什么建议吗?您过去使用过什么解决方案? 当前 现在,我只是在使用地图: 要求 我需要扩展缓存以包括以下基本功能: 最大尺寸 生存时间 但是,我不需要更复杂的功能,例如: 来自多个进程的访问(缓存服务器) 持久性(到磁盘) 意见建议 内存中缓存: Guava CacheBuilder-活动开发。请参阅此演示文稿。 LRUMap-通过API配置。
-
本文向大家介绍浅谈Webpack 持久化缓存实践,包括了浅谈Webpack 持久化缓存实践的使用技巧和注意事项,需要的朋友参考一下 前言 最近在看 webpack 如何做持久化缓存的内容,发现其中还是有一些坑点的,正好有时间就将它们整理总结一下,读完本文你大致能够明白: 什么是持久化缓存,为什么做持久化缓存? webpack 如何做持久化缓存? webpack 做缓存的一些注意点。 持久化缓存 首
-
我使用JPA(Eclipse Link 2.5)进行持久性。我的Web应用程序包含AJAX页面更新。保存帖子时,发布的内容会在不刷新浏览器的情况下显示。该帖子具有使用OneTo多关系与之关联的标签。这些标签应该在保存后也会显示出来。但是,由于启用了缓存,我无法获取标签。 这是我的代码: 我怎样才能让事情运转起来?如何刷新一个实体及其所有关联的实体?谢了。
-
主要内容:JPA级联持久化示例,输出结果级联持久化用于指定如果实体持久化,则其所有关联的子实体也将被持久化。 以下语法用于执行级联持久性操作 - JPA级联持久化示例 在这个例子中,我们将创建两个相互关联的实体类,但要建立它们之间的依赖关系,我们将执行级联操作。 这个例子包含以下步骤 - 第1步: 在包下创建一个名为的实体类,其中包含属性:,,以及标记为级联规范的类型的对象。 文件: StudentEntity.java - 第2步:
-
在持久性方面,spark中的和有什么区别?