
Lexer是一个由 Java 编写的 C 语言词法分析器,词法分析是编译过程的第一个阶段,是编译的基础。这个阶段的任务是从左到右一个字符一个字符地读入源程序,即对构成源程序的字符流进行扫描然后根据构词规则识别单词(也称单词符号或符号)。
主要特点有:
支持识别十进制数、八进制数、标识符、关键字、分割符、操作符等多种词素
支持文件导入和源代码编写两种输入方式
采用Swing GUI类库,算法和UI通过回调接口实现松耦合
运行效果:
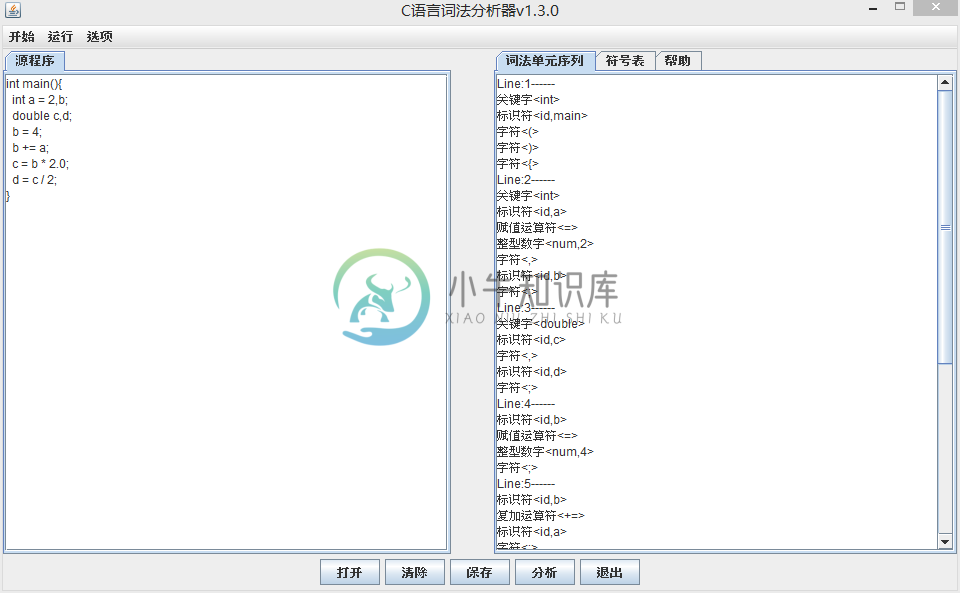
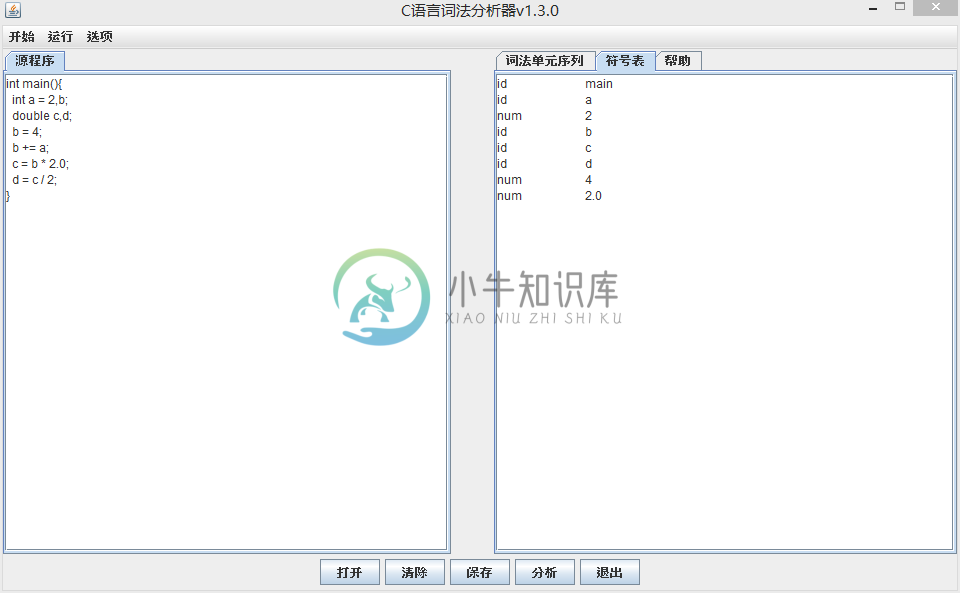
-
系列文章目录 LLVM系列第一章:编译LLVM源码 LLVM系列第二章:模块Module LLVM系列第三章:函数Function LLVM系列第四章:逻辑代码块Block LLVM系列第五章:全局变量Global Variable LLVM系列第六章:函数返回值Return LLVM系列第七章:函数参数Function Arguments LLVM系列第八章:算术运算语句Arithmetic S
-
动机 项目研发过程中经常会需要将业务逻辑外置,需要将业务逻辑和代码分离。一般面对这样的需求有以下几种解决办法: 引入一个规则引擎,比如Drools。 利用java的javax.script.ScriptEngineManager调用javascript脚本。 利用antlr这样的开源项目定义自己的业务领域语言。 笔者在开发过程中经常需要对字符串进行分析,比如:从一个字符串中取出第一个符合标识符的单
-
在上一章的旅程中,我们讨论了词法分析器的实现思路,我们也为词法分析器的实现做了许多准备工作。现在,就让我们来实现词法分析器吧。 1. 词法分析器的类定义 词法分析器的类定义如下: class Lexer { public: // Constructor explicit Lexer(const string &inputFilePath); sqlparser2021-01-18 09:03:38
-
nextToken--获取第一个有效的单词 nextTokenIdent(); 啥意思 from 表名 表名叫identify Token token = lexer.token(); IDENTIFY 就是普通的一列
-
前言 说到词法分析,我想很多同学第一时间想到的可能是 Babel、Acorn 等工具。不可否认,它们都很强大 。 但是,具体到今天这个话题 ES Module 语句的词法分析而言,es-module-lexer 会胜过它们很多! 那么,今天我们将围绕以下 2 点,深入浅出一番 es-module-lexer: 认识 es-module-lexer 实际场景下如何应用 es-module-lexe
-
lexer概述 Lexer:Lexer主要不停扫描源文件,根据文法将源文件转成token。主要的方法为nextToken(计算下一个token)和token(计算当前的探针下的token)和token(在token缓冲池中寻找特定位置的token) Scanner: Scanner是Lexer的实现类。主要的属性有:tokens(token工具类),token,prevToken, savedTo
-
因为词法规则可以使用递归,所以词法解析器在技术上和语法解析器一样强大。那意味着我们甚至可以在词法分析器中匹配语法结构。或者,在另一个极端,我们可以把字符当作记号,使用语法分析器去把语法结构应用到字符流(这种被称为无扫描语法分析器)。这导致什么在词法分析器中匹配和什么在语法分析器中匹配的界线在哪里并不是很明显。幸运的是,有几条经验法则可以让我们做出判断: 在词法分析器中匹配和丢弃任何语法分析器根本不
-
在高级的分析器程序中,你可能同时需要多个语法和词法分析器。 依照规则行事不会有问题。不过,你需要小心确定所有东西都正确的绑定(hooked up)了。首先,保证将 lex() 和 yacc() 返回的对象保存起来: lexer = lex.lex() # Return lexer object parser = yacc.yacc() # Return parser obje
-
一个高级语言程序在计算机中一般以文件形式存在,文件是一堆字节的集合,而它要表达的含义显然不是一堆字节,最小单位是一个个词,因此编译一个程序,一开始的工作就是词法分析 龙书的词法分析部分,掺杂了很多自动机相关的东西,其实这些在计算理论有更详细的描述,在编译原理里面讲大概是希望能让零基础的人看懂,可惜这样一来内容就比较臃肿,而且好像也讲的不是很系统反而让人看糊涂,就好像算法导论里面讲NP一样,虽然没有
-
词法解析、语法解析 这一节我们分析下PHP的解析阶段,即 PHP代码->抽象语法树(AST) 的过程。 PHP使用re2c、bison完成这个阶段的工作: re2c: 词法分析器,将输入分割为一个个有意义的词块,称为token bison: 语法分析器,确定词法分析器分割出的token是如何彼此关联的 例如: $a = 2 + 3; 词法分析器将上面的语句分解为这些token:$a、=、2、+、3
-
有一个读入整数序列的语法,它的玄机是由输入的部分指定有多少个整数组合在一起,所以我们必须等到运行时才能知道有多少整数被匹配。这里是示例输入文件idata.txt的内容: 2 9 10 3 1 2 3 第1个数字表示匹配后续两个数字9和10;紧跟10的数字3表示匹配接下来的三个数字。我们的目的是设计一个语法IData.g,把9和10组合在一起,把1、2和3组合在一起。在语法上执行以下命令后显示的语
-
2. 词法分析 Python程序由解析器读取。输入到解析器中的是由词法分析器生成的词符流。本章讲述词法分析器如何把一个文件拆分成词符。 Python程序的文本使用7比特ASCII字符集。 2.3版中新增:可以使用编码声明指出字符串字面值和注释使用一种不同于ASCII的编码。 为了和旧的版本兼容,如果发现8比特字符,Python只会给出警告。修正这些警告的方法是声明显式的编码,或者对非字符的二进制数
-
上一篇文章讲到了状态机和词法分析的基本知识,这一节我们来分析Jsoup是如何进行词法分析的。 代码结构 先介绍以下parser包里的主要类: Parser Jsoup parser的入口facade,封装了常用的parse静态方法。可以设置maxErrors,用于收集错误记录,默认是0,即不收集。与之相关的类有ParseError,ParseErrorList。基于这个功能,我写了一个PageEr
-
主要内容:安装包,示例,应用Surv()和survfit()函数生存分析涉及预测特定事件发生的时间。 它也被称为失败时间分析或分析死亡时间。 例如预测癌症患者的生存天数或预测机械系统出现故障的时间。 R中的软件包:用于进行生存分析。该包中含有函数,它将输入数据作为R公式,并在所选变量中创建一个生存对象进行分析。然后使用函数来创建分析图。 安装包 语法 在R中创建生存分析的基本语法是 - 以下是使用的参数的描述 - time - 是直到事件发生的后续时间。 ev