
Parca 是一个针对应用程序和基础设施的持续分析项目。持续分析以分析 CPU、内存使用情况,直至行号。节省基础设施成本、提高性能并提高可靠性。
持续分析是以系统的方式对程序进行剖析(如CPU、内存、I/O等)的行为。Parca 收集、存储并提供可在一段时间内查询的配置文件。它有一个强大的多维数据模型、存储和查询引擎,专门为剖析数据设计。
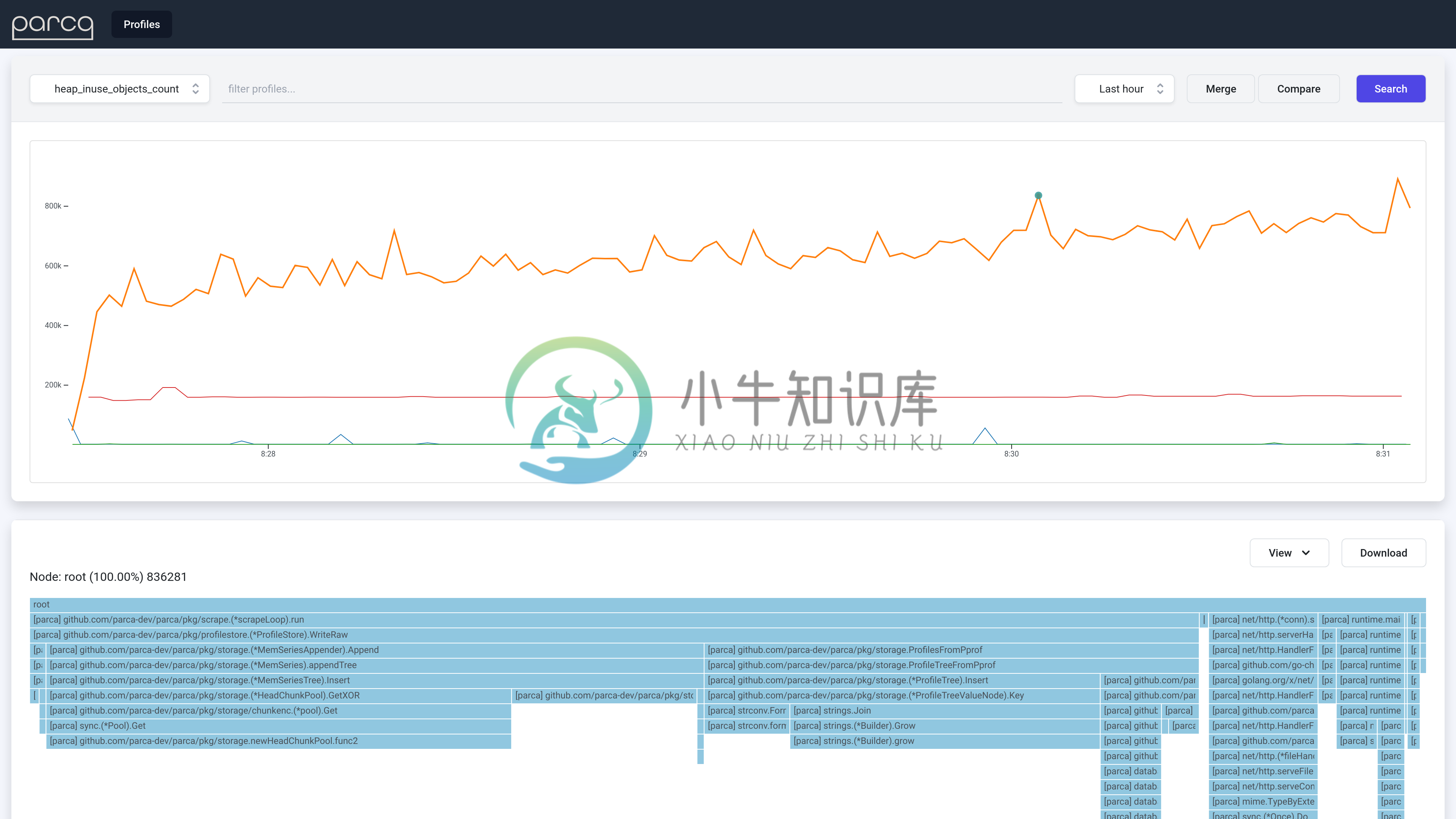
特性:
-
eBPF Profiler:单个 profiler,使用 eBPF,以非常低的开销自动从 Kubernetes 或 systemd 跨整个基础架构发现目标。支持 C、C++、Rust、Go 等。
-
Open Standards:使用基于 eBPF 的 profiler 生成 pprof 格式的配置文件,并摄取任何 pprof 格式的配置文件,允许广泛的语言采用和与现有工具的互操作性。
-
优化的存储和查询:有效地存储分析数据,同时保留原始数据,并允许通过基于标签的搜索对数据进行切片和切块。聚合分析数据基础架构范围内的数据,及时查看单个配置文件或在任何维度上进行比较。
优势
- 省钱:许多组织通过轻松优化的代码路径浪费了 20-30% 的资源。Parca 代理旨在通过要求整个基础设施的 0 检测来降低进入门槛。
- 提高性能:使用随时间收集的分析数据,Parca 可以自信地和具有统计意义的确定要优化的热门路径。此外,它还可以显示任何标签维度之间的差异,例如部署、版本和区域。
- 了解事件:分析数据可提供对流程随时间执行的内容的独特见解和深度。内存泄漏,以及导致意外行为的 CPU 或 I/O 中的瞬时峰值,传统上难以排除故障,而通过连续分析则轻而易举。
-
内存池 简介: Nginx里内存的使用大都十分有特色:申请了永久保存,抑或伴随着请求的结束而全部释放,还有写满了缓冲再从头接着写.这么做的原因也主要取决于Web Server的特殊的场景,内存的分配和请求相关,一条请求处理完毕,即可释放其相关的内存池,降低了开发中对内存资源管理的复杂度,也减少了内存碎片的存在. 所以在Nginx使用内存池时总是只申请,不释放,使用完毕后直接destroy整个内存池
-
Computers in the future may have as few as 1,000 vacuum tubes and weigh only 1.5 tons. — Popular Mechanics (1949) 在本章中,我们将学习如下内容: 使用版本控制 使用提交钩子 使用 Rake 部署变更 配置 Puppet 的文件服务器 从 cron 运行 Puppet 使用自动签名 预签
-
ngrok运行全球分布式隧道服务器,为您的应用程序提供快速,低延迟的流量。 地点 ngrok运行世界各地数据中心的隧道服务器。数据中心在给定区域内的位置可能改变而不通知(例如,欧洲服务器可能从法兰克福移动到伦敦)。 us - United States (Dallas) eu - Europe (Frankfurt) ap - Asia/Pacific (Singapore) au - Austr
-
链接 集成EntityFramework 集成NHibernate 集成EntityFramework Core 集成EntityFramework MySQL 集成Dapper
-
自由软件项目依赖于选择性捕获和信息集成的技术。对这些技术的使用越是熟练,并说服别人去使用这些技术,你的项目就越成功。随着项目的成长,这一点愈发正确。好的信息管理系统应该能够防止开源项目在布鲁克法则的重压下崩塌[12] ,也就是说向一个已经延期的项目增加人力,只能使项目延期更多。佛雷德·布鲁克观察到,项目的复杂性同参与人员数量的平方成正比。当项目中只有少数几个人时,大家可以容易的互相交谈,但当有上百
-
是否有其他机制可以将入口控制器暴露给外部世界?
-
9.2 ABP基础设施层 - 集成Dapper 9.2.1 简介 Dapper 是基于.NET的一种对象关系映射工具。Abp.Dapper简单的将Dapper集成到ABP。它作为第二个ORM可以与EF 6.x, EF Core 或者 Nhibernate 工作。 9.2.2 安装 在开始之前,你需要安装Abp.Dapper以及 EF 6.x, EF Core 或者 NHibernate 这3个当中
-
9.2 ABP基础设施层 - 集成NHibernate ABP可以与任何ORM框架协同工作,它内置了对NHibernate的集成支持。本文将介绍如何在ABP中使用NHibernate。本文假定你已经初步掌握了NHibernate。 译者注:怎么才算初步掌握了NHibernate呢?译者认为应当懂得使用NHibernate进行CRUD,懂得使用Fluent模式进行映射。 9.2.1 Nuget包 要