
Spider Admin Pro
Github: https://github.com/mouday/spider-admin-pro
Gitee: https://gitee.com/mouday/spider-admin-pro
Pypi: https://pypi.org/project/spider-admin-pro
简介
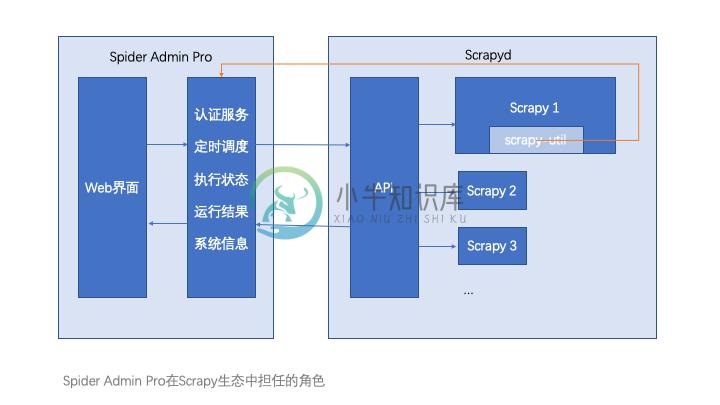
Spider Admin Pro 是Spider Admin的升级版
- 简化了一些功能;
- 优化了前端界面,基于Vue的组件化开发;
- 优化了后端接口,对后端项目进行了目录划分;
- 整体代码利于升级维护。
安装启动
方式一:
$ pip3 install spider-admin-pro $ python3 -m spider_admin_pro.run
方式二:
$ git clone https://github.com/mouday/spider-admin-pro.git $ python3 spider_admin_pro/run.py 或者 $ gunicorn spider_admin_pro.run:app
配置参数
在运行目录新建 .env 环境变量文件,默认参数如下
注意:为了与其他环境变量区分,使用SPIDER_ADMIN_PRO_作为变量前缀
# flask 服务配置 SPIDER_ADMIN_PRO_PORT = 5002 SPIDER_ADMIN_PRO_HOST = '127.0.0.1' # 登录账号密码 SPIDER_ADMIN_PRO_USERNAME = admin SPIDER_ADMIN_PRO_PASSWORD = "123456" SPIDER_ADMIN_PRO_JWT_KEY = FU0qnuV4t8rr1pvg93NZL3DLn6sHrR1sCQqRzachbo0= # token过期时间,单位天 SPIDER_ADMIN_PRO_EXPIRES = 7 # scrapyd地址, 结尾不要加斜杆 SPIDER_ADMIN_PRO_SCRAPYD_SERVER = 'http://127.0.0.1:6800' # 调度器 调度历史存储设置 # mysql or sqlite and other, any database for peewee support SPIDER_ADMIN_PRO_SCHEDULE_HISTORY_DATABASE_URL = 'sqlite:///dbs/schedule_history.db' # 调度器 定时任务存储地址 SPIDER_ADMIN_PRO_JOB_STORES_DATABASE_URL = 'sqlite:///dbs/apscheduler.db'
使用python3 -m 运行,需要将变量加入到环境变量中,运行目录下新建文件env.bash
注意,此时等号后面不可以用空格
# flask 服务配置 export SPIDER_ADMIN_PRO_PORT=5002 export SPIDER_ADMIN_PRO_HOST='127.0.0.1' # 登录账号密码 export SPIDER_ADMIN_PRO_USERNAME='admin' export SPIDER_ADMIN_PRO_PASSWORD='123456' export SPIDER_ADMIN_PRO_JWT_KEY='FU0qnuV4t8rr1pvg93NZL3DLn6sHrR1sCQqRzachbo0='
增加环境变量后运行
$ source env.bash
$ python3 -m spider_admin_pro.run
生成jwt key
$ python -c 'import base64;import os;print(base64.b64encode(os.urandom(32)).decode())'
使用扩展
收集运行日志:scrapy-util 可以帮助你手机到程序运行的统计数据
技术栈:
1、前端技术:
| 功能 | 第三方库及文档 |
|---|---|
| 基本框架 | vue |
| 仪表盘图表 | echarts |
| 网络请求 | axios |
2、后端技术
| 功能 | 第三方库及文档 |
|---|---|
| 接口服务 | Flask |
| 任务调度 | apscheduler |
| scrapyd接口 | scrapyd-api |
| 网络请求 | session-request |
| ORM | peewee |
| jwt | jwt |
| 系统信息 | psutil |
项目结构
【公开仓库】基于Flask的后端项目spider-admin-pro: https://github.com/mouday/spider-admin-pro
【私有仓库】基于Vue的前端项目spider-admin-pro-web: https://github.com/mouday/spider-admin-pro-web
spider-admin-pro项目结构:
.
├── __init__.py
├── run.py
├── main.py
├── config.py
├── version.py
├── flask_app.py
├── logger.py
├── api_result.py
├── api
│ ├── __init__.py
│ ├── auth_api.py
│ ├── schedule_api.py
│ ├── scrapyd_api.py
│ └── system_info_api.py
├── service
│ ├── __init__.py
│ ├── auth_service.py
│ ├── schedule_service.py
│ ├── scrapyd_service.py
│ └── system_data_service.py
├── model
│ ├── __init__.py
│ ├── base.py
│ └── history.py
├── exceptions
│ ├── __init__.py
│ ├── api_exception.py
│ └── constant.py
├── utils
│ ├── __init__.py
│ ├── jwt_util.py
│ ├── scheduler_util.py
│ ├── sqlite_util.py
│ └── system_info_util.py
└── web
├── __init__.py
├── main.py
└── public
├── index.html
└── static
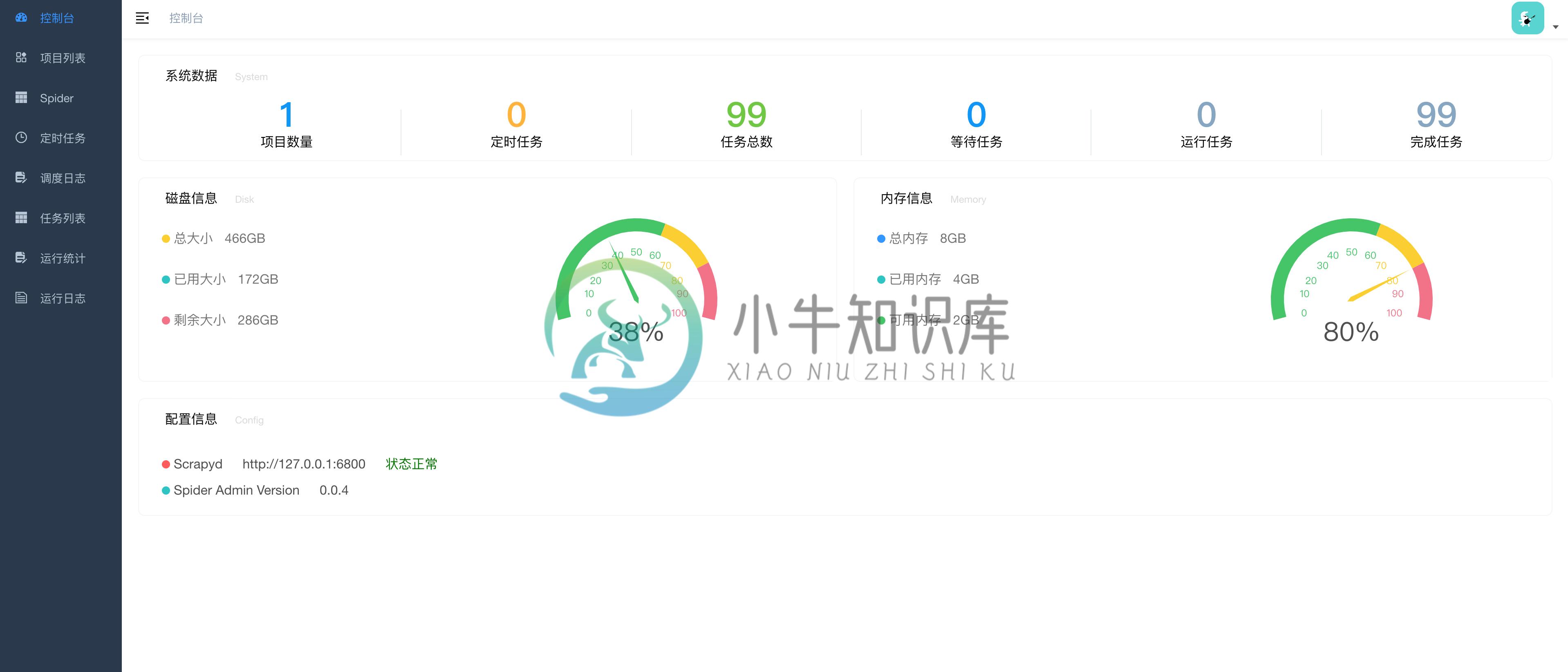
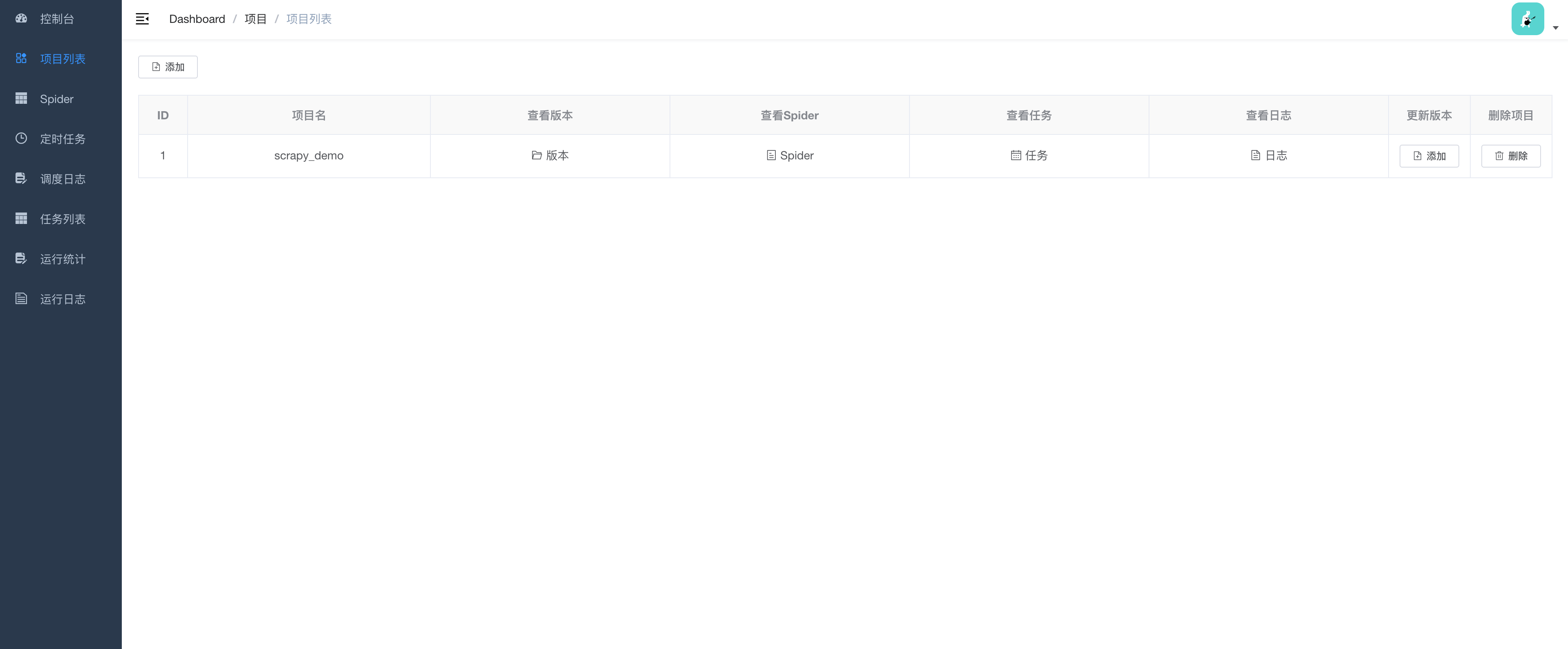
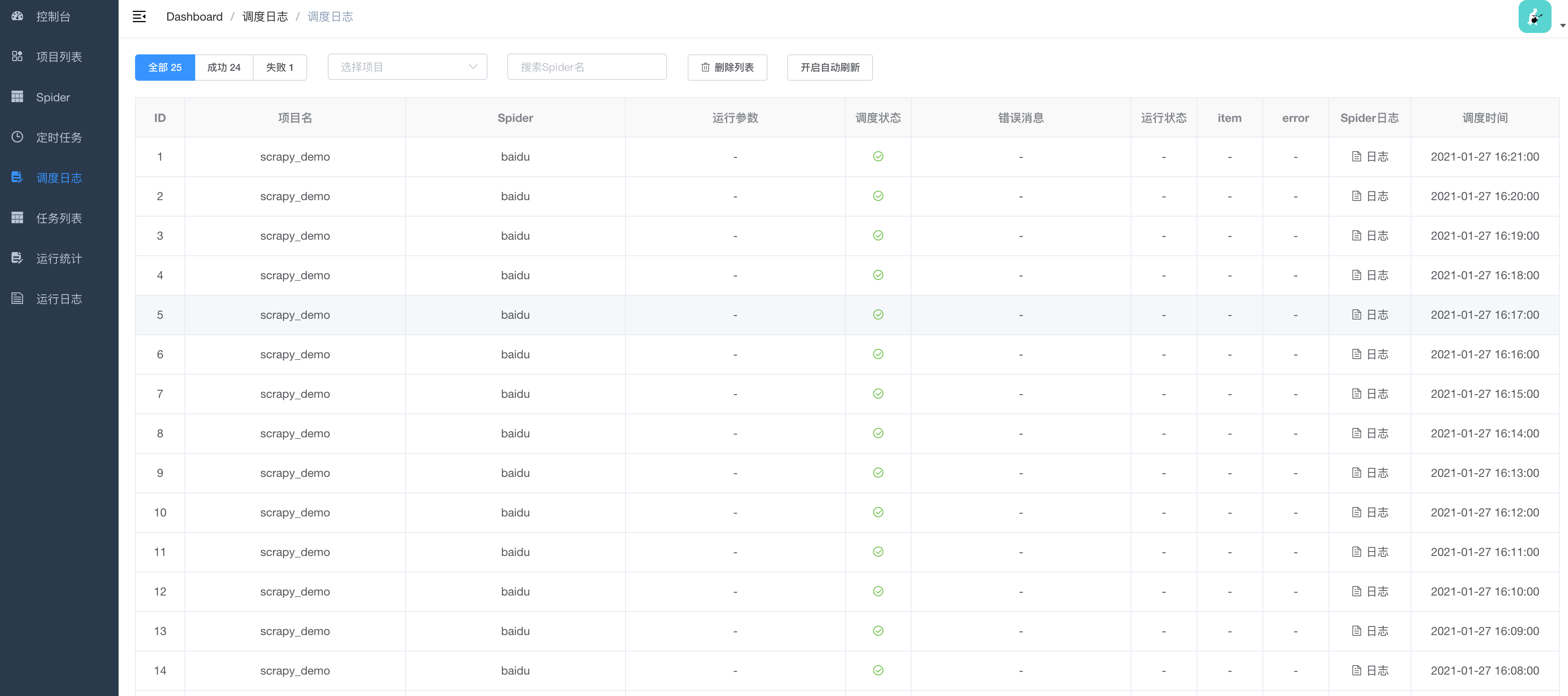
项目截图
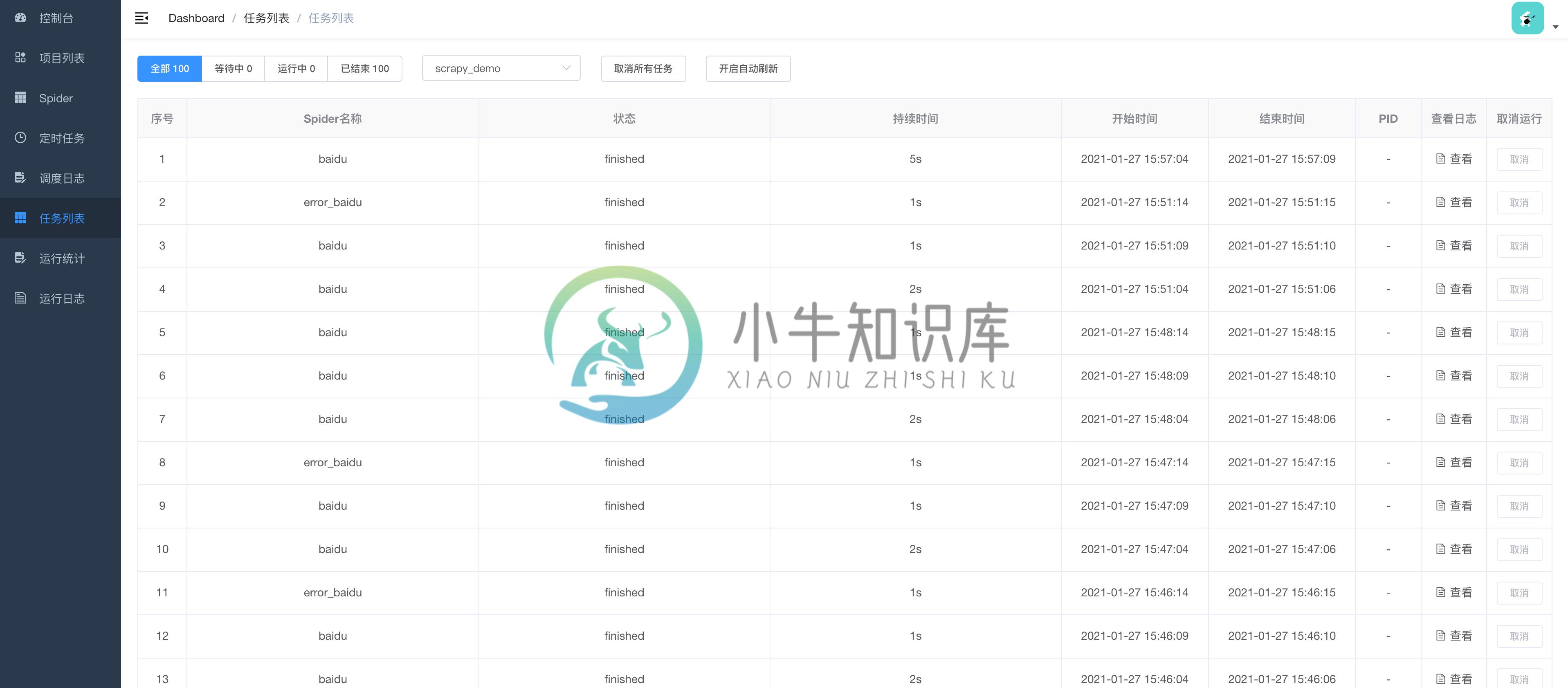
TODO
1. 补全开发文档
2. 支持命令行安装可用
3. 优化代码布局,提取公共库
4. 日志自动刷新
5. scrapy项目数据收集
-
鉴于 Qt6 已经选择了CMake作为基本的源码编译工具,看来我们不得不好好熟悉一下CMake的用法了。从网上和Qt新建工程的模板出发,花了3天时间,基本熟悉了CMake的语法和原理,并成功用笔者的一个OpenStreetMap客户端工程作为实验,为其添加了CMake支持。本文主要介绍一下迁移的基本过程,以及注意事项,最后,会进行一个小的总结。 该工程在我的博文中有详细描述,完成迁移的项目可以参考
-
运行多个爬虫 定义程序,集中启动 在项目路径下创建crawl.py文件,内容如下: from scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settings process = CrawlerProcess(get_project_settings()) # myspd1是爬虫
-
本章介绍 Linux 内核中定时器和时钟管理相关的观念。 简介 - 简单介绍 Linux 内核中的定时器。 时钟源框架简介 - this part describes clocksource framework in the Linux kernel. The tick broadcast framework and dyntick - 介绍 tick broadcast framework an
-
您可以在 设置 > 对象 中查看、编辑和删除保存的搜索、可视化组件以及仪表板。您也可以导入或者导出搜索、可视化组件和仪表板的集合。 保存的对象会显示在 发现 、可视化组件 或者 仪表板 页面的待选列表中。要查看保存的对象: 进入 设置 > 对象 。 选择您想要查看的对象。 点击 查看 按钮。 编辑一个保存的对象能够让您直接修改对象的定义。您可以改变对象的名称、添加说明并修改定义对象属性的 JSON
-
定时器管理接口 结构体 struct rt_timer 定时器控制块 更多... 宏定义 #define RT_TIMER_FLAG_DEACTIVATED 0x0 定时器未激活 #define RT_TIMER_FLAG_ACTIVATED 0x1 定时器已激活 #define RT_TIMER_FLAG_ONE_SHOT 0x0 一次性计时器
-
Python 中有很多库可以用来可视化数据,比如 Pandas、Matplotlib、Seaborn 等。 Matplotlib import matplotlib.pyplot as plt import numpy as np %matplotlib inline t = np.arange(0., 5., 0.2) plt.plot(t, t, "r--", t, t**2, "bs", t
-
是否有任何方法可以使用Cypher仅可视化Neo4j中特定类型的关系(实际图形)?例如,考虑数据模型,其中节点可以有三种类型的关系,即QR、QL和RL。 假设两个节点之间具有所有三种类型的关系,并说我只想突出显示整个图中的QR关系。现在如果我运行 “匹配p=(n)-[r:QR]- 它确实以表格形式给我所需的结果。但是,可视化部分不是必需的。它显示了A和B之间的所有关系(oi61.tinypic.c
-
我在FBO中从渲染缓冲区切换到深度纹理。但它似乎不包含任何深度数据。如果我把这个纹理渲染成全屏的四边形,所有的东西都是黑色的。我非常确定纹理和FBO设置是好的。FBO已经完成,如果我清除了深度,让我们对格雷说: glClearDepth(0.5f); 然后我看到了斑点通道中的颜色,但没有看到几何渲染中的数据。 总之,这就是我创建纹理的方式: 其中intFmt是GL_DEPTH_component
-
视频上传完毕后,后台会自动为您跳转到视频列表管理页面。 您也可以进入视频页面,点击管理视频按钮,可以编辑、查询、删除、编辑现有视频。 管理视频页面: 1)搜索视频: 在管理视频页面,我们为您提供5种方式检索已有视频,每种查询之间可以同时生效: ·按视频ID号码查询,注:ID号必须完全正确; ·按上传者账号查询; ·按上传时间查询; ·按视频分类查询; ·按视频状态查询。 2)视频列表: 用来显示所
-
null null 我怎样才能想象这些工作类型之间的关系?还有其他插件支持这些类型吗?