
SumatraPDF 是一种多格式(PDF、EPUB、MOBI、FB2、CHM、XPS、DjVu)阅读器,适用于 (A)GPLv3 许可的 Windows,部分代码符合 BSD 许可。
SumatraPDF 体积小、速度极快,且支持 PDF、电子书(epub、mobi)、漫画书(cbz/cbr)、DjVu、XPS、CHM、Windows 图像等各类格式,简单好用。
在此查看该项目的更多开发者信息。
-
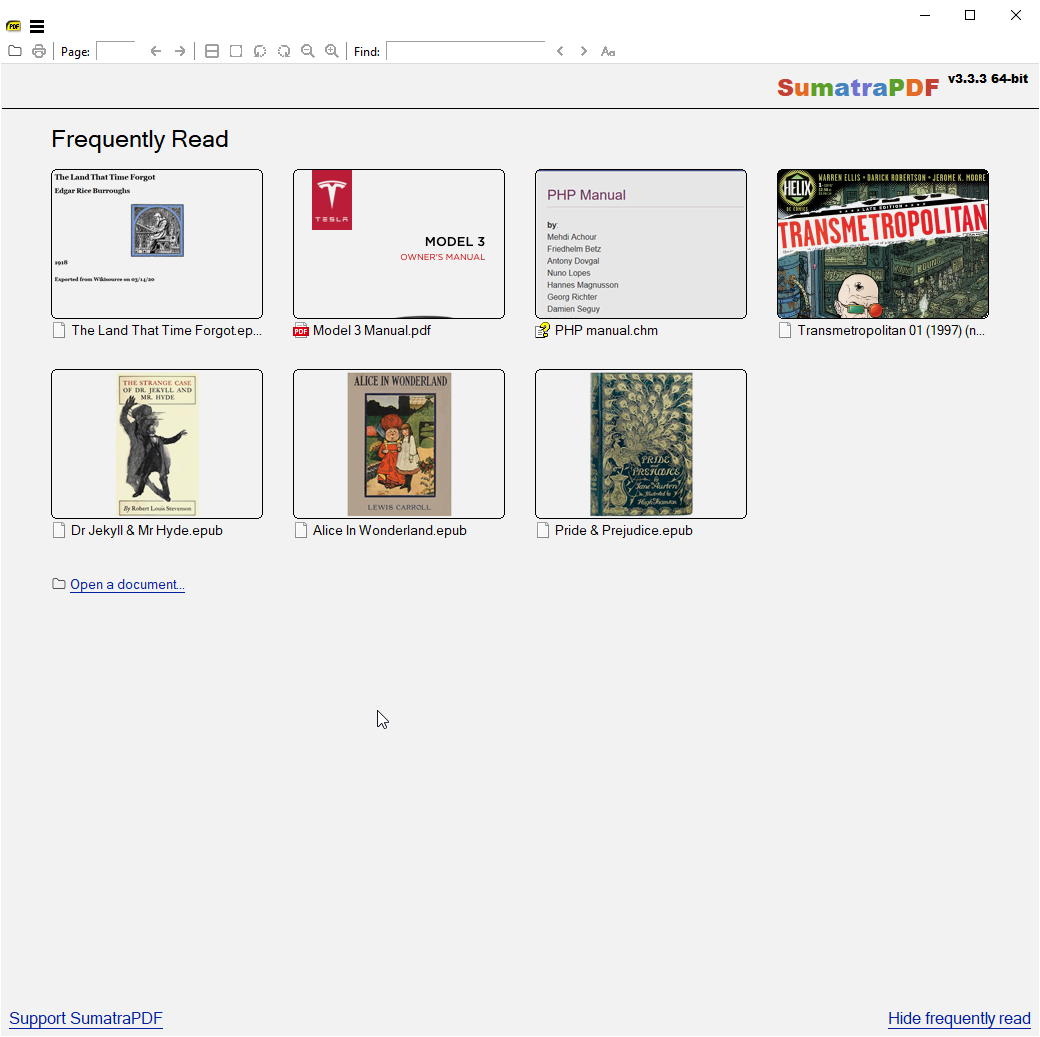
介绍 支持PDF, ePub, Mobi, XPS, DjVu, CHM, CBZ 和 CBR格式的电子文件 仅支持Windows,原因见官网论坛 绿色版,小巧,于此潮流而不失赤子之心者,唯 Sumatra PDF 而已矣 Sumatra PDF 的启动是异常迅速,几乎没有启动过程,程序界面直接呈现 图形化显示最近文档 打开历史文档后,直接跳转到上次查看的位置 这里介绍比官方文档还全 && 详细的
-
因为平时需要看的很多书都是PDF格式的,最开始都是用的adobe的PDF阅读器,打开速度慢,还不能随时保存阅读的进度,在网上看到网友推荐的一款开源的阅读器——SumatraPDF阅读器,自己下载用了一下,挺小巧的,能够自动保存阅读进度了,挺好用的。 官网地址:http://www.sumatrapdfreader.org/free-pdf-reader.html
-
# For documentation, see http://www.sumatrapdfreader.org/settings3.2.html MainWindowBackground = #467500 EscToExit = true ReuseInstance = false UseSysColors = false RestoreSession = true FixedPageUI [
-
https://blog.csdn.net/e15273/article/details/79639653 // 无文档时,窗口的背景色,默认为黄色 MainWindowBackground = #fff200 // 是否允许用 Esc 键退出 SumatraPDF EscToExit = false // 是否用现有窗口打开文档 ReuseInstance = false // 是否使用系
-
本章讲述:使用SumatraPDF.exe 查看pdf文档; 首先要下载 “SumatraPDF.exe” 程序,开源的 代码示例,调用“SumatraPDF.exe”查看pdf文档: string exePath = System.IO.Path.Combine(Environment.CurrentDirectory, "SumatraPDF.exe"); if (!System.IO.Fil
-
SumatraPDF安装包 因为外网下载速度很不稳定,自己又找了半天,现在分享下PDF的链接。 百度网盘 提取码:8888
-
SumatraPDF 设置 - 高级选项 可以通过文档任意调整设置 Customizing SumatraPDF 3.3.1 (sumatrapdfreader.org) 其中 EbookUI [ FontName = Georgia FontSize = 18 TextColor = #5f4b32 BackgroundColor = #fbf0d9 U
-
Android PDF Viewer 是Android平台下的PDF阅读器。
-
我在试图打开pdf文件以读取其内容并将数据映射回pdf时收到错误。错误是:com。itextpdf。文本例外。InvalidPDException:com上未知的加密类型R=6。itextpdf。文本pdf。PdfReader。readPdf(PdfReader.java:631) 我使用的是java 1.6、Itext 5.4.1和bouncycastle 1.48。pdf创建为1.7版,加密为
-
问题内容: 我有一个很大的PDF文件,它是建筑物的平面图。它具有用于所有办公家具的图层,包括座位位置的文本框。 我的目标是使用PHP读取此文件,在文档中搜索文本层,获取其内容和文件中的坐标。这样,我可以绘制出座位位置-> x / y坐标。 有没有办法通过PHP做到这一点?(如果需要的话,甚至可以是Ruby或Python) 问题答案: 签出FPDF(使用FPDI): http://www.fpdf.
-
从BigQuery读取和过滤数据,我有两种方法 > 从 Dataflow 中的 BigQuery 读取(使用 BigqueryIO.readTableRow.from(ValueProvider)))整个数据,然后根据条件(如最大日期)进行筛选 使用NestedValueProvider通过生成仅获取所需数据的查询从数据流中的BigQuery读取要慢得多。 因为如果我读取整个数据并且我的表处于追加
-
我试图添加阅读更多的功能,以一些文本,其中包括标题和段落。但它在一行中显示所有文本。我希望在单击“阅读更多”时将文本格式化。 以下是我正在使用的代码: 有没有可能得到的文本格式,因为我不能删除标题,并希望显示,因为它是。 下面是我的文本的样子 什么是Lorem Ipsum? Lorem Ipsum只是印刷和排版行业的虚拟文本。 自16世纪以来,Lorem Ipsum一直是行业标准的虚拟文本,当时一
-
我在使用pdfbox阅读pdf时遇到了一个问题。我的实际pdf部分不可读,所以当我在编辑器中复制和粘贴不可读的部分时,它会显示小方框符号,但当我试图通过pdfbox读取同一文件时,这些字符不会被读取(我也不希望它们被读取)。我希望我至少能得到一些符号或随机字符,而不是实际的字符。有没有办法做到这一点。该行已被选中,因此它不是图像。有人找到解决办法了吗? 有一个pdfbox示例,我们在pdfText
-
我想读取word/docx文件的数据并保存到我的数据库中,需要时我可以从数据库中获取数据并在我的html页面上显示我使用ApachePOI读取docx文件中的数据,但它无法获取公式,请帮助我!
-
如何用Python阅读pdf?我知道一种将其转换为文本的方法,但我想直接从PDF阅读内容。 谁能解释一下python中的哪个模块最适合pdf提取