
Ext2Read 它能查看 ext2/3/4 分区并从中拷贝文件和目录,支持 LVM2 和 EXT4 extent ,以及递归拷贝整个目录。
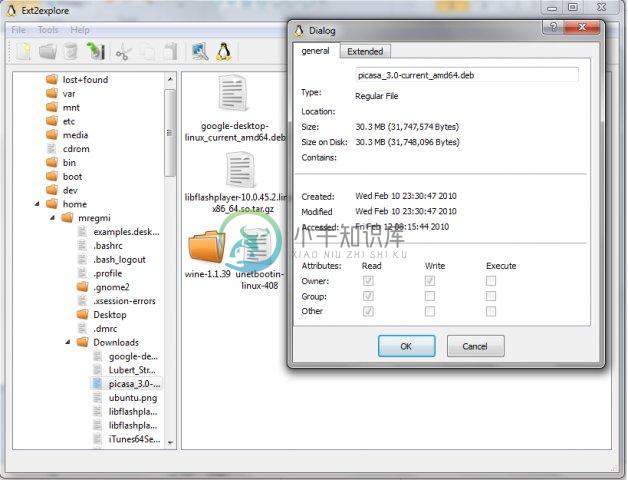
-
最近在采用ext2read读取读硬盘里ext2文件系统分区文件的数据,该开源库是读取MBR分区下的各分区数据,对ext2read库里面的主要接口大概整理下: 1.int Ext2Read::scan_partitions(char *path, int diskno) scanMBR分区分区头及4个分区表,获取各分区数据(分区起始扇区,分区总的扇区数,如果是GPT分区,需根
-
在进行分区时,每个分区就是一个文件系统,而每个文件系统开始位置的那个块就称为超级块。超级块的作用是存储文件系统的大小、空的和填满的块,以及它们各自的总数和其他诸如此类的信息。这也就是说,要使用这一个分区来进行数据访问时,第一个要经过的就是超级块,所以超级块坏了,这个磁盘也就回天乏术了。 super block的中文名称是超级块,它是硬盘分区开头——开头的第一个byte是byte 0,从 byte
-
一个硬盘可以有很多分区,但MBR分区表只有四项,怎么能突破这个限制呢?答案是扩展引导记录(EBR - Extended Boot Record),通过把MBR分区表中一项设为扩展分区(系统ID为0x05或0x0F),其分区表项指定扩展分区的起始位置和长度,在其中最开始扇区 (EBR)和MBR相同位置(0x1BE)放置另外一个分区表,一般称为扩展分区表。扩展分区表的第一项指定扩展分区目前的逻辑分区信
-
linux 将ext2变成ext4文件系统 ext2是非日志系统,断电很容易造成文件损坏。 1 卸载 sudo vim /etc/fstab /dev/mmcblk1p7 /data auto defaults 0 0 前面加一个#,改成如下 #/dev/mmcblk1p7 /data auto defaults 0 0 保存退出 (或 umount /dev/mmcblk1p7),重启reb
-
在ext2read中读取ext4文件系统的代码中,读取硬盘中的信息时,定义了以下的宏,那么这个宏是什么意思呢? #define DEVICE "\\\\.\\PhysicalDrive0"是什么意思? 由于"\"是C/C+中转义符, "\\\\.\\"就相当于\\.\,那么以上的宏定义中的“\\\.\\PhysicalDrive0”就等价于“\\.\PhysicalDrive0” 在Wind
-
Linux文件系统格式一般是Ext3,Ext4外加LVM,那么如何在Windows上读写这些分区呢? 推荐以下几款软件: 可以读写Ext2/Ext3文件系统,不支持Ext4文件系统和LVM。 在Windows7下,安装文件Ext2Fsd-0.51.exe需要设置为管理员运行和兼容WindowsXP SP3模式。 Ext2Fsd is an ext2 file system driver for W
-
问题发现 突然发现机器重启后很多服务都出现了问题,不仅如此,还无法对文件进行操作: >mkdir test mkdir: cannot create directory ‘test’: Read-only file system 排查问题 查看mount发现根目录被挂载为了read only: >mount ....... /dev/mapper/vg0-root on / type ext4 (
-
之前我们讲过vfs虚拟文件系统的lookup文件查找的实现,知道当内核的缓存没有找到的时候,就会调用到inode_operations结构体的lookup函数来实现,我们今天以ext2文件系统为例,来讲解一下对应文件系统的lookup函数的实现。 首先ext2的inode_operation结构体定义在ext2/namei.c,定义如下 const struct inode_operations
-
giis-ext4 (gET iT i sAY) 是一个 Ext4 文件系统的文件恢复工具,安装后当前文件和新创建的文件都可以恢复,可恢复删除的文件,恢复某个用户的文件和恢复指定类型文件。
-
当我使用Spark从S3读取多个文件时(例如,一个包含许多Parquet文件的目录)- 逻辑分区是在开始时发生,然后每个执行器直接下载数据(在worker节点上)吗?< br >还是驱动程序下载数据(部分或全部),然后进行分区并将数据发送给执行器? 此外,分区是否默认为用于写入的相同分区(即每个文件= 1个分区)?
-
如何读取带有条件作为数据帧的分区镶木地板, 这工作得很好, 分区存在的时间为< code>day=1到day=30是否可能读取类似于< code>(day = 5到6)或< code>day=5,day=6的内容, 如果我输入< code>*,它会给出所有30天的数据,而且太大了。
-
当使用Spark sql读取jdbc数据时,Spark默认只会启动1个分区。但是当表太大时,Spark读取速度会很慢。 我知道有两种方法可以制作分区: 1.在选项中设置分区列、lowerBound、upperBound和num分区; 2.在选项中设置偏移数组; 但我的情况是: 我的jdbc表没有INT列,或者列字符串可以很容易地用这两种方式的偏移量分隔。 这两种方法在我的情况下行不通,还有其他方法
-
我有一个带有2个分区的源主题,我正在用同一个应用程序启动2个kafka streams应用程序。id,但不同的接收器主题。 1) 这两个应用程序实例是否会从不同的分区接收数据? 2)如果其中一个应用程序被杀死,另一个实例会自动从两个实例中消耗吗? 3) 我如何证明上述情况?
-
我有一些数据存储在拼花格式的S3存储桶中,遵循类似蜂巢的分区风格,使用这些分区键:零售商-年-月-日。 如 我想在sagemaker笔记本中读取所有这些数据,我想将分区作为我的DynamicFrame的列,这样当我,包括它们。 如果我使用Glue建议的方法,分区就不会包含在我的模式中。下面是我使用的代码: 相反,通过使用普通的火花代码和DataFrame类,它可以工作,并且分区包含在我的架构中:
-
问题内容: 我是Jenkins和groovy脚本的新手,我想读取一个.txt文件,该文件位于其中一个作业的工作空间中。我正在尝试这样做: 但是会导致以下错误: groovy.lang.MissingMethodException:方法的无签名:hudson.FilePath.readFileFromWorkspace()适用于参数类型:(java.lang.String)值:[file.txt]
-
我遇到了一个问题,无法在Hive中读取由Spark生成的分区拼花文件。我可以在hive中创建外部表,但是当我尝试选择几行时,hive只返回一个“OK”消息,没有行。 我能够在Spark中正确读取分区的拼花文件,所以我假设它们是正确生成的。当我在hive中创建外部表而不进行分区时,我也能够读取这些文件。 null 我的Spark配置文件有以下参数(/etc/Spark/conf.dist/spark