
1、HashDB是什么?
HashDB是一个简单的KeyValue存储系统原型,提供基本的<key, value>二元组的数据存储与读取功能,亦即当前被广为推崇的NoSQL存储系统。最初想到设计这个小系统,完全是出于偶然。本人维护着一个轻量级的开源重复数据删除小工具deduputil,它基于块级对文件目录进行数据去重并进行打包,支持定长和变长数据分块算法,并支持数据块压缩。deduputil使用hash数据指纹来区分和识别重复数据块,数据块指纹采用hashtable进行存储和查找,并完全置于内存中。假设,数据块平均大小为4KB,数据块对象属性描述约需40字节,则存储8TB数据的指纹大约需要80GB内存,如此庞大的内存需求使得deduputil很难工作于普通的PC或服务器。因此决定对deduputil进行重构,支持在内存有限的环境下进行大数据量的去重和打包,思想是让指纹数据在内存与磁盘之间进行交换。最初想直接采用类似Tokyo Cabinet的NoSQL系统,后来发现这些系统远远比deduputil复杂,使用它们真是大材小用,而且使得deduputil对第三方软件产生了依赖。于是产生了设计一个简单的KeyValue存储系统的念头,经过几个晚上的奋战,HashDB原型系统完成并成功应用于deduputil上,代码量不到1000行,非常非常轻量级。HashDB以较小的内存消耗达到支持超大hashtable,数据持久化存储于文件中,并在内存与文件之间进行交换。HashDB主要采用了hashtable, bloom filter, set-assocaite cache, file layout, btree等数据结构与算法,初步性能测试结果表明HashDB的性能基本还算不错,已经比较接近Tokyo Cabinet的性能。HashDB源码包含在deduputil中,可以从http://sourceforge.net/projects/deduputil/获得。
2、基本原理
HashDB采用哈稀表数据结构组织数据,以文件形式对数据进行持久化存储,文件数据布局如下图所示,由header, bloom filter, bucket array, hash entries四个部分组成。Header记录HashDB的一些全局信息,比如总的记录数、hash桶数、缓存记录数以及它们在文件中的偏移位置。Header持久化存储在HashDB文件头部,加载时需要首先读取它,然后据此加载其他组成部分数据。Bloom filter是一个空间效率很高的数据结构,它由一个位数组和一组hash映射函数组成。Bloom filter可以用于检索一个元素是否在一个集合中,它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。这里主要利用bloom filter来快速判断给定Key是否存在于HashDB中,如果不存在则直接返回,存在则再进行文件I/O读写和Key精确查找,从而节省大量的I/O和检索开销。bloom filter长度由最大支持记录数决定,在创建HashDB时指定并保存在header中,一旦创建不可修改,下次启动时从header中读取并加载。
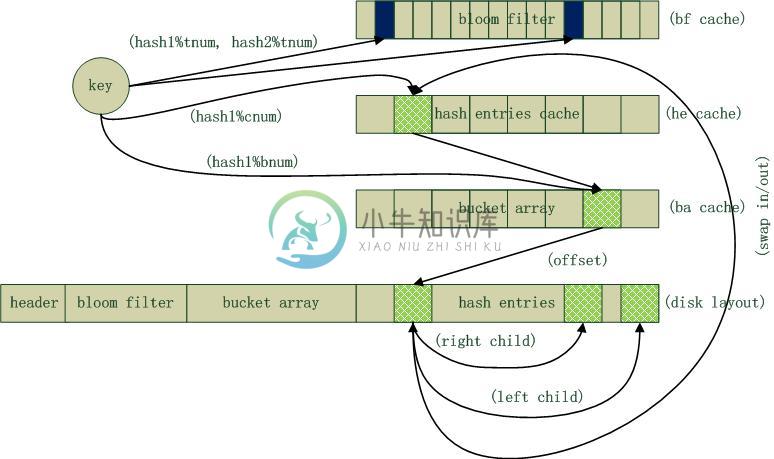
HashDB以hashtable方式组织数据,桶数组长度在创建时指定,同样以后不可修改。bucket array会远远小于记录总数,一般平均桶长在10以上。通常情况下,桶中以链表方式组织产生冲突的记录,查找时遍历链表,当桶较长时顺序查找效率较低。HashDB桶中的记录采用btree结合二次hash方法来组织,这点参考了Tokyo Cabinet。Btree实现简单,查找时间复杂度为log(h),但可能会发生二叉树极度为平衡的情况,而平衡树(如RB, B*, B-, B+树)实现则较为复杂。二次hash方法,先比较hash值再比较关键字key,从而获得较为平衡的btree。实践表明,btree结合二次hash的方法非常有效,可以大大提高检索效率。Bucket array中记录中对应桶的btree根结点偏移,以它为Root可以遍历搜索整个hash桶。
Hash entries区域部分存储了所有的KeyValue记录,出于简化设计实现考虑,每个记录的大小固定,Key和Value都有最大长度限制,记录以Append方式增加,支持修改Key对应的Value值,目前没有支持删除操作。同一个桶中的记录以btree方式组织,入口地址保存在bucket array中对应桶节点中。HashDB设计了Cache系统来提升性能,缓存的记录数量通常约为总记录数的10%,这也是采纳了热点数据的常见比率。Cache管理算法采用类似计算机高速Cache的组相联(Set-associative)算法,以hash为基础进行记录的换入和换出,即同一个桶中的记录会被cache到相同的cache项中。
HashDB中,header, bloom filter, bucket array, hash entries四个部分持久化存储于文件中,运行时header, bloom filter, bucket array完全缓存在内存中,cache则仅在运行时存在,这部分内存空间消耗是可以估算的。假设,总记录数tnum=1000万,hash桶数bnum=100万,缓存记录数量cnum=100万,每条记录固定大小为1KB,则内存消耗=1000万/8 + 100万*8 + 100万*1KB = 1.25MB + 8MB + 1GB。HashDB加载时,header, bloom filter, bucket array将从文件中读取并载入内存,并读取每个hash桶的第一个记录对cache进行预热。HashDB关闭时,内存中的所有脏数据将被写回文件,记录数庞大时,这个过程会比较耗时。
HashDB目前还是一个很简单的原型系统,没有提供锁机制,只能应用于单进程/线程模式。HashDB也没有提供常驻系统服务(Daemon),仅提供如下几个API进行访问。详细信息请参考hashdb.h & hashdb.c,简单描述如下:
HASHDB *hashdb_new(uint64_t tnum, uint32_t bnum, uint32_t cnum, hashfunc_t hash_func1, hashfunc_t hash_func2);
创建一个新的HashDB对象,参数分别为总记录数、hash桶数、缓存记录数、两个hash函数。
int hashdb_open(HASHDB *db, const char *path);
使用HashDB对象打开文件,路径由path指定。如果HashDB文件已经存在,则将header, bloom filter, bucket array载入内存,然后预读记录进行cache预热;如果是新建HashDB,则根据hashdb_new输入参数计算header结构各项参数值,然后在文件中为header, bloom filter, bucket array预分配空间。
int hashdb_close(HASHDB *db, int flash);
关闭HashDB,将缓存数据中的所有脏数据与加文件,并释放内存空间。
int hashdb_set(HASHDB *db, char *key, void *value, int vsize);
设置(写入或更新)KeyValue记录,参数分别为关键字、值以及value长度。pos = hash_func1(key) % cnum,计算出key对应的cache位置,如果该位置已经缓存记录但不是当前记录,则将该记录换出内存(缓存状态设置为未缓存);如果没有缓存并bloom filter判断记录存在,则查找记录并换入内存。然后,设置缓存记录结构各项数据,对于新记录需要设置bloom filter位状态和缓存状态。
int hashdb_get(HASHDB *db, char *key, void *value, int *vsize);
读取KeyValue记录,参数分别为关键字、值缓冲区和值长度。pos = hash_func1(key) % cnum,计算出key对应的cache位置,如果bloom filter判断该记录不存在,则直接返回。如果该位置缓存记录但不是当前记录,则将该记录换出内存;如果没有缓存,则查找记录并换入内存,然后复制key对应的记录值和值长度。
-
在按照Wiki的指示安装时报错fatal error: 'openssl/evp.h' file not found,按照wiki的解决方案执行 brew link openssl --force 但是brew却拒绝链接,即使加了--force仍然失败,推测是新版brew针对ssl进行了保护,以免强制链接后其他程序出错。 于是只好另辟蹊径,手动对头文件建立链接如下 sudo mkdir /usr
-
谢了。
-
我正在学习C#并尝试用数据库做一个简单的登录系统,我遇到了一个System.TypeInitializationException错误:“'mysql.data.mysqlClient.mysqlConnectattrs'的类型初始化器引发了一个异常。 }
-
简介 Lumen 有很棒的文件系统抽象层,是基于 Frank de Jonge 的 Flysystem 扩展包。 Lumen 集成的 Flysystem 提供了简单的接口,可以操作本地端空间、 Amazon S3 、 Rackspace Cloud Storage 。更好的是,它可以非常简单的切换不同保存方式,但仍使用相同的 API 操作! 配置文件 文件系统的配置文件放在 config/file
-
本文向大家介绍原生JS实现-星级评分系统的简单实例,包括了原生JS实现-星级评分系统的简单实例的使用技巧和注意事项,需要的朋友参考一下 今天我又写了个很酷的实例:星级评分系统(可自定义星星个数、显示信息) sufuStar.star(); 使用默认值5个星星,默认信息 var msg = [........]; sufuStar.star(10,msg); 自定义星星个数为10、显示信息msg格式
-
问题内容: 我正在研究一个小型Java游戏,其中可能发生各种事件。至少有几十个基本事件,各种事件处理程序可能会对这些事件感兴趣。代码中还有几个地方可能会触发这些事件。我不是要让事件侦听器知道他们需要向哪个类注册,而是想创建某种集中式的消息调度系统,某些类会将事件提交到该系统中,而感兴趣的类可以加入以侦听某些种类的事件。事件。 但是我有一些疑问。首先,这似乎是一个显而易见的普遍问题。是否有简单的VM
-
本文向大家介绍简单的Python人脸识别系统,包括了简单的Python人脸识别系统的使用技巧和注意事项,需要的朋友参考一下 案例一 导入图片 思路: 1.导入库 2.加载图片 3.创建窗口 4.显示图片 5.暂停窗口 6.关闭窗口 案例二 在图片上添加人脸识别 思路: 1.导入库 2.加载图片 3.加载人脸模型 4.调整图片灰度 5.检查人脸 6.标记人脸 7.创建窗口 8.显示图片 9.暂停窗口