
Data Studio 是 Google 推出的数据分析和可视化工具,它与 Google 的很多产品进行了整合,企业可以用它来制作互动性报告和图表。例如,用户可以综合利用来自谷歌的 Google Sheets、AdWords、 Google Analytics、BigQuery 和 YouTube 等产品的原始数据来制作个性化的报告。
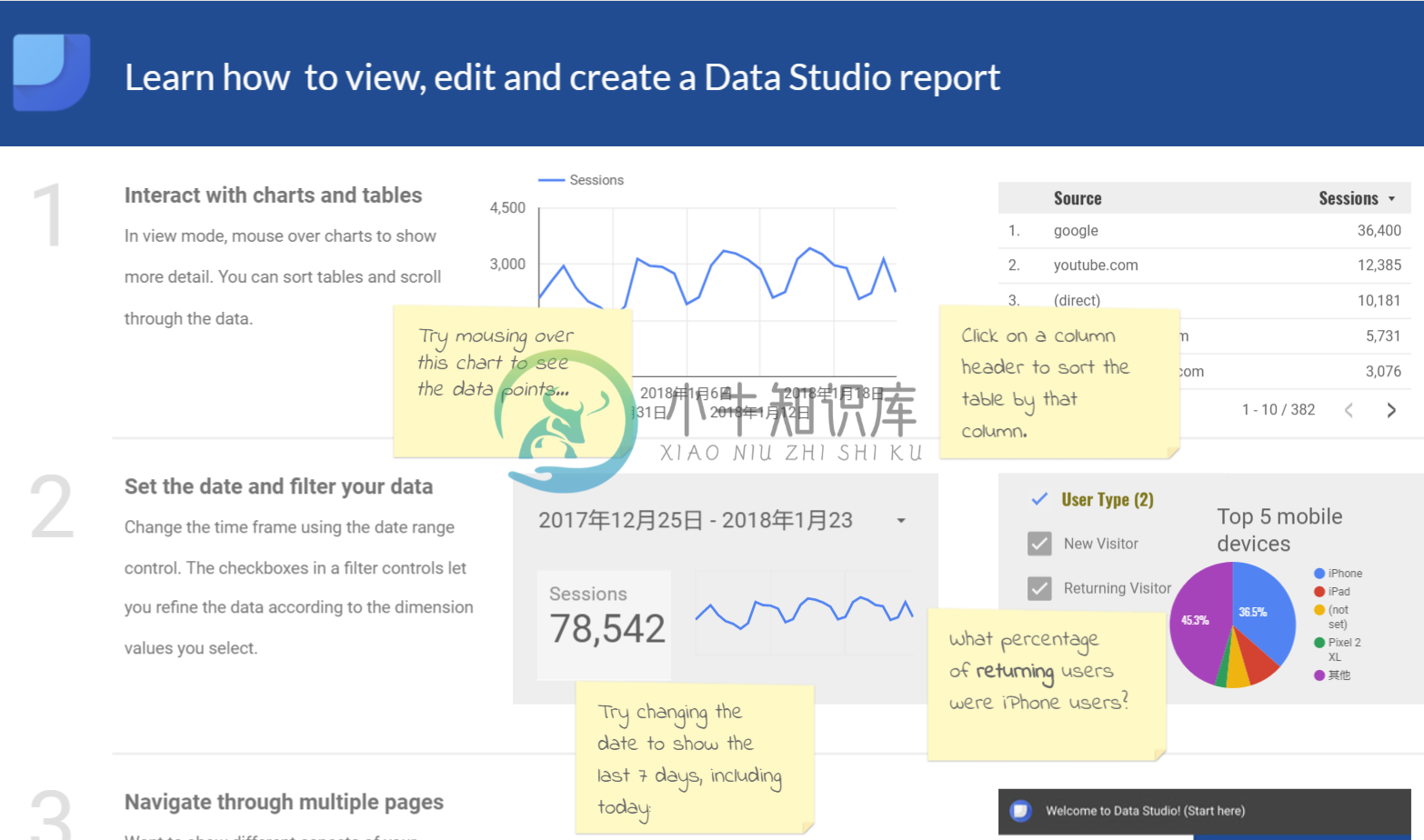
Data Studio 的开源存储库中目前主要包含的是社区连接器 (Community Connectors) ,它是 Data Studio 的一个新功能,借助这个功能,能可以使用 Apps Script 构建连接到任何可以通过互联网访问的数据源的连接器。能可与其他人分享社区连接器,让他们可以在 Data Studio 内获取自己的数据。
例如,如果能在向客户提供一种基于网络的服务,则可以创建一个带模板信息中心的社区连接器,从你的 API 提取数据。只需点击数下,你的客户便可登录你的网络应用,进行 Data Studio 身份验证,并在美观的交互式信息中心中查看他们的个性化数据。
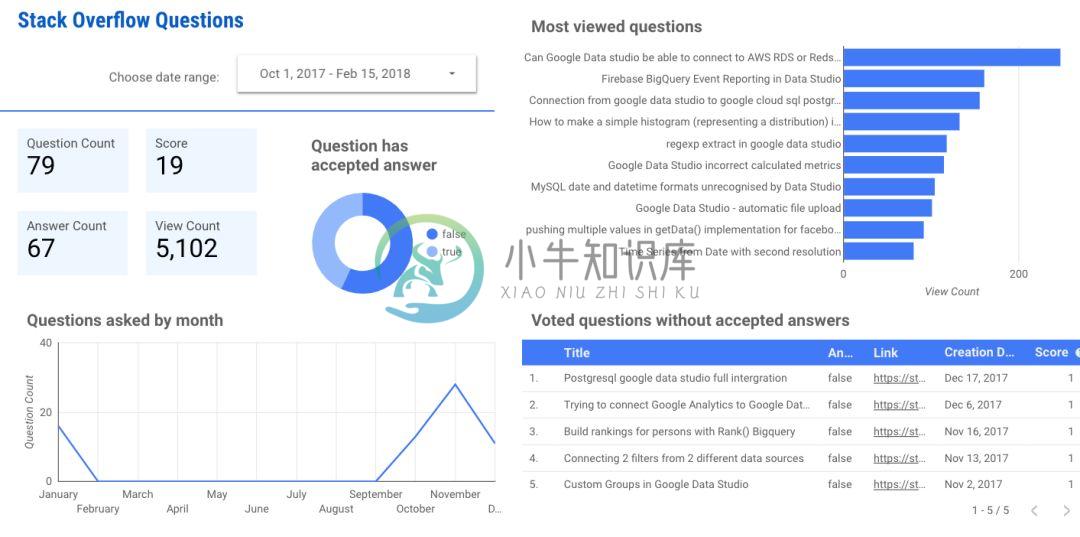
下面是一个示例 Data Studio 信息中心,它通过社区连接器显示使用 Stack Overflow API 的实时数据:
-
功能简介 GBaseDataStudio 管理工具是 GBase 提供的一种新的集成环境,用于访问、控制和 管理 GCluster 集群环境。GBaseDataStudio 管理工具将一组多样化的图形工具与多 种功能齐全的脚本编辑器组合在一起,可为各种技术级别的开发人员和管理员提供 对 GCluster 集群环境的访问功能。 GBaseDataStudio 管理工具通过 JDBC Driver 和
-
GBaseDataStudio 管理工具是 GBase 8a MPP 提供的一种跨平台(适用于 windows、linux 等)管理工具,将一组多样化的图形工具与多种功能齐全的 SQL 脚本编辑器组合在一起,用于对 GBase 8a MPP Cluster 的访问、控制和管理。 GBaseDataStudio 管理工具可以完成如下工作: 管理单个集群环境或多个集群环境。 管理单个集群环境中的单个或
-
aqua data studio 汉化方法 ***注: D:\Aqua Data Studio 19.0\lib 为我安装的路径 1、将D:\Aqua Data Studio 19.0\lib 下的两个jar包重命名(最好把后缀改掉) 2、将破解包的jar包复制到 D:\Aqua Data Studio 19.0\lib 下 3、用360压缩打开原始 ads.jar 包,把路径: com\aqua
-
在现实世界中,我们经常遇到大量原始数据,这些数据不适合机器学习算法。 我们需要在将原始数据输入各种机器学习算法之前对其进行预处理。 本章讨论在Python机器学习中预处理数据的各种技术。 数据预处理 在本节中,让我们了解如何在Python中预处理数据。 最初,在文本编辑器(如记事本)中打开扩展名为.py文件,例如prefoo.py文件。 然后,将以下代码添加到此文件中 - import numpy
-
有一些工具可以帮助您在几分钟内可视化所有数据。这些工具已经存在多年并且已经很成熟; 只需按照您的要求选择正确的数据可视化工具即可。 数据可视化用于与数据交互。Google,Apple,Facebook和Twitter都更好地询问他们的数据更好的问题,并通过使用数据可视化做出更好的业务决策。 以下常见的十大数据可视化工具: 1. Tableau Tableau是一种数据可视化工具。可以创建图形,图表
-
在处理一组数据时,您通常想做的第一件事就是了解变量的分布情况。本教程的这一章将简要介绍seaborn中用于检查单变量和双变量分布的一些工具。 您可能还需要查看[categorical.html](categorical.html #categical-tutorial)章节中的函数示例,这些函数可以轻松地比较变量在其他变量级别上的分布。 import seaborn as sns import m
-
数据可视化工具 JS 库: d3 sigmajs **部件 & 组件:</h5> Chart.js C3.js Google Charts chartist-jsj amCharts [$] Highcharts [Non-commercial free to $] FusionCharts [$] ZingChart [free to $] Epoch 服务: Datawrapper infog
-
在侧边导航栏点击 Visualize 开始视化您的数据。 Visualize 工具能让您通过多种方式浏览您的数据。例如:我们使用饼图这个重要的可视化控件来查看银行账户样本数据中的账户余额。点击屏幕中间的 Create a visualization 蓝色按钮开始。 有很多种可视化控件可供选择。我们点击其中一个名为 Pie 的。 您可以为已保存的搜索建立可视化效果,或者输入新的搜索条件。使用后者时,
-
大数据面临数据规模大、数据变化快、数据类型多、价值密度低4个挑战,而传统的数据可视化工具难以应对。传统的数据可视化工具仅仅将数据加以组合,通过不同的展现方式提供给用户,用于发现数据之间的关联信息。近年来,随着云和大数据时代的来临,数据可视化产品已经不再满足于使用传统的数据可视化工具来对数据仓库中的数据抽取、归纳并简单的展现。新型的数据可视化产品必须满足互联网爆发的大数据需求,必须快速的收集、筛选、
-
机器学习关于将模型拟合到数据;出于这个原因,我们首先讨论如何表示数据以便计算机理解。 除此之外,我们将基于上一节中的matplotlib示例构建,并展示如何可视化数据的一些示例。 sklearn 中的数据 scikit-learn 中的数据(极少数例外)被假定存储为形状为[n_samples, n_features]的二维数组。许多算法也接受形状相同的scipy.sparse矩阵。 n_sampl
-
数据可视化主要旨在借助于图形化手段,清晰有效地传达与沟通信息。 热力图 散点图 动画要素图 高效率点图层 ECharts Mapv OSM Buildings