
ProxyIpPool 是一个爬虫代理 ip 池,主要用途爬取代理 ip ,然后将这些代理 ip 放入池子里(池子是某个数据结构的概念,比如我用的是队列)进行维护。
为什么需要维护呢?因为大多数代理 ip 都不太问题稳定,需要我们用程序自行去评测它的一个稳定性和可靠性,从而筛选出可用的代理 ip 持久化到我们的磁盘里。
系统原理图:
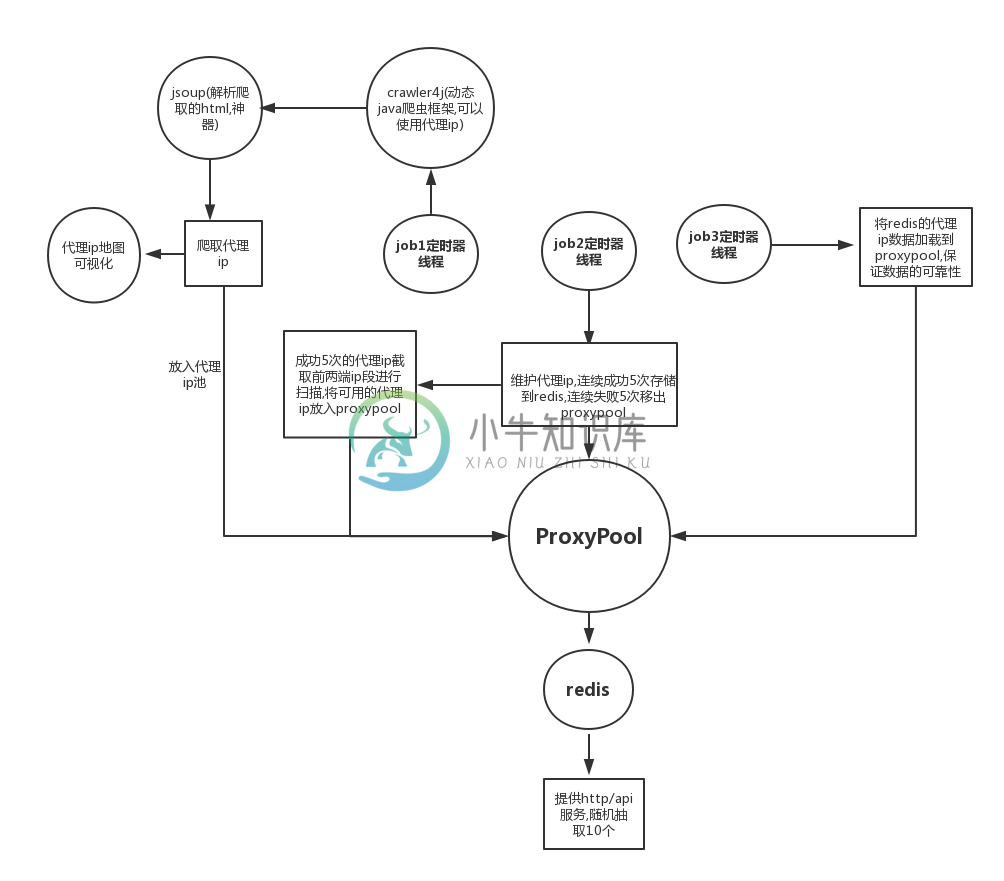
-
本文向大家介绍Python代理IP爬虫的新手使用教程,包括了Python代理IP爬虫的新手使用教程的使用技巧和注意事项,需要的朋友参考一下 前言 Python爬虫要经历爬虫、爬虫被限制、爬虫反限制的过程。当然后续还要网页爬虫限制优化,爬虫再反限制的一系列道高一尺魔高一丈的过程。爬虫的初级阶段,添加headers和ip代理可以解决很多问题。 本人自己在爬取豆瓣读书的时候,就以为爬取次数过多,直接被封
-
本文向大家介绍python3 Scrapy爬虫框架ip代理配置的方法,包括了python3 Scrapy爬虫框架ip代理配置的方法的使用技巧和注意事项,需要的朋友参考一下 什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍。所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板。
-
本文向大家介绍Python实现的异步代理爬虫及代理池,包括了Python实现的异步代理爬虫及代理池的使用技巧和注意事项,需要的朋友参考一下 使用python asyncio实现了一个异步代理池,根据规则爬取代理网站上的免费代理,在验证其有效后存入redis中,定期扩展代理的数量并检验池中代理的有效性,移除失效的代理。同时用aiohttp实现了一个server,其他的程序可以通过访问相应的url来从
-
本文向大家介绍Python爬虫抓取代理IP并检验可用性的实例,包括了Python爬虫抓取代理IP并检验可用性的实例的使用技巧和注意事项,需要的朋友参考一下 经常写爬虫,难免会遇到ip被目标网站屏蔽的情况,银次一个ip肯定不够用,作为节约的程序猿,能不花钱就不花钱,那就自己去找吧,这次就写了下抓取 西刺代理上的ip,但是这个网站也反爬!!! 至于如何应对,我觉得可以通过增加延时试试,可能是我抓取的太
-
有的时候,当我们的爬虫程序完成了,并且在本地测试也没有问题,爬取了一段时间之后突然就发现报错无法抓取页面内容了。这个时候,我们很有可能是遇到了网站的反爬虫拦截。 我们知道,网站一方面想要爬虫爬取网站,比如让搜索引擎爬虫去爬取网站的内容,来增加网站的搜索排名。另一方面,由于网站的服务器资源有限,过多的非真实的用户对网站的大量访问,会增加运营成本和服务器负担。 因此,有些网站会设置一些反爬虫的措施。我
-
本文向大家介绍Python3网络爬虫之使用User Agent和代理IP隐藏身份,包括了Python3网络爬虫之使用User Agent和代理IP隐藏身份的使用技巧和注意事项,需要的朋友参考一下 本文介绍了Python3网络爬虫之使用User Agent和代理IP隐藏身份,分享给大家,具体如下: 运行平台:Windows Python版本:Python3.x IDE:Sublime text3 一
-
本文向大家介绍java代理实现爬取代理IP的示例,包括了java代理实现爬取代理IP的示例的使用技巧和注意事项,需要的朋友参考一下 仅仅使用了一个java文件,运行main方法即可,需要依赖的jar包是com.alibaba.fastjson(版本1.2.28)和Jsoup(版本1.10.2) 如果用了pom,那么就是以下两个: 完整的代码如下: 以上这篇java代理实现爬取代理IP的示例就是小编
-
这一章将会介绍使用一些新的模块(optparse,spider)去完成一个爬虫的web应用。爬虫其实就是一个枚举出一个网站上面的所有链接,以帮助你创建一个网站地图的web应用程序。而使用Python则可以很快的帮助你开发出一个爬虫脚本. 你可以创建一个爬虫脚本通过href标签对请求的响应内容进行解析,并且可以在解析的同时创建一个新的请求,你还可以直接调用spider模块来实现,这样就不需要自己去写