
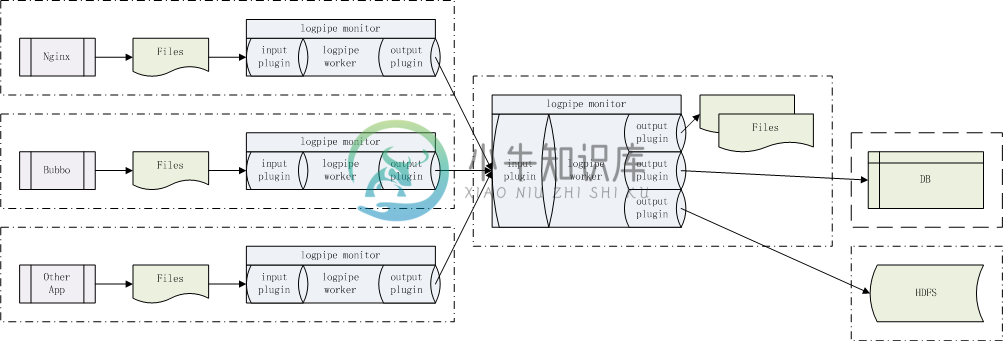
logpipe是一个分布式、高可用的用于采集、传输、对接落地的日志工具,采用了插件风格的框架结构设计,支持多输入多输出按需配置组件用于流式日志收集架构,无第三方依赖。
logpipe概念朴实、使用方便、配置简练,没有如sink等一大堆新名词。
logpipe由若干个input、事件总线和若干个output组成。启动logpipe管理进程(monitor),派生一个工作进程(worker),监控工作进程崩溃则重启工作进程。工作进程装载配置加载若干个input插件和若干个output插件,进入事件循环,任一input插件产生消息后输出给所有output插件。
logpipe自带了4个插件(今后将开发更多插件),分别是:
-
logpipe-input-file 用inotify异步实时监控日志目录,一旦有文件新建或文件增长事件发生(注意:不是周期性轮询文件修改时间和大小),立即捕获文件名和读取文件追加数据。该插件拥有文件大小转档功能,用以替代应用日志库对应功能,提高应用日志库写日志性能。该插件支持数据压缩。
-
logpipe-output-file 一旦输入插件有消息产生后用相同的文件名落地文件数据。该插件支持数据解压。
-
logpipe-input-tcp 创建TCP服务侦听端,接收客户端连接,一旦客户端连接上有新消息到来,立即读取。
-
logpipe-output-tcp 创建TCP客户端,连接服务端,一旦输入插件有消息产生后输出到该连接。
使用者可根据自身需求,按照插件开发规范,开发定制插件,如IBMMQ输入插件、HDFS输出插件等。
logpipe配置采用JSON格式,层次分明,编写简洁,如示例:
{
"log" :
{
"log_file" : "/tmp/logpipe_case1_collector.log" ,
"log_level" : "INFO"
} ,
"inputs" :
[
{ "plugin":"so/logpipe-input-file.so" , "path":"/home/calvin/log" , "compress_algorithm":"deflate" }
] ,
"outputs" :
[
{ "plugin":"so/logpipe-output-tcp.so" , "ip":"127.0.0.1" , "port":10101 }
]
}-
日志采集配置 在应用详情页中间有一个叫作“日志采集”的模块 点击右边的“添加”按钮,在弹出的对话框中选择日志的路径及正则规则 文件路径:你日志文件的位置 日志规则:如果没有特殊需求的话默认就好 提交后服务会自动重启动。 日志采集 如果配置了上面采集器,那么它会向服务所在的Pod注入一个Filebeat采集器对应用服务的业务日志进行采集。把采集到的日志入到kafka集群,然后logstash进行消息
-
题目描述: 日志采集是运维系统的的核心组件。日志是按行生成,每行记做一条,由采集系统分批上报。 如果上报太频繁,会对服务端造成压力;如果上报太晚,会降低用户的体验;如果一次上报的条数太多,会导致超时失败。 为此,项目组设计了如下的上报策略: 1、每成功上报一条日志,奖励1分 2、每条日志每延迟上报1秒,扣1分 3、积累日志达到100条,必须立即上报 给出日志序列,根据该规则,计算首次上报能获得的最
-
系统与程序的运行日志对排查问题以及实现一些自动化操作可能非常有用。本文将简要说明收集 TiDB 及相关组件日志的方法。 TiDB 与 Kubernetes 组件运行日志 通过 TiDB Operator 部署的 TiDB 各组件默认将日志输出在容器的 stdout 和 stderr 中。对于 Kubernetes 而言,这些日志会被存放在宿主机的 /var/log/containers 目录下,并
-
Soukey 采摘网站数据采集软件是一款基于.Net 平台的开源软件,也是网站数据采集软件类型中唯一一款开源软件。尽管 Soukey 采摘开源,但并不会影响软件功能的提供,甚至要比一些商用软件的功能还要丰富。Soukey 采摘当前提供的主要功能如下: 1. 多任务多线程数据采集,支持 POST 方式; 2. 可采集 Ajax 页面; 3. 支持 Cookie,支持手工登录采集数据
-
介绍 Hutool-log做为一个日志门面,为了兼容各大日志框架,一个用于自动创建日志对象的日志工厂类必不可少。 LogFactory类用于灵活的创建日志对象,通过static方法创建我们需要的日志,主要功能如下: LogFactory.get 自动识别引入的日志框架,从而创建对应日志框架的门面Log对象(此方法创建一次后,下次再次get会根据传入类名缓存Log对象,对于每个类,Log对象都是单例