
RepoStats 是一款用于统计开源代码仓库数据的工具,同时支持将数据可视化。
开源代码仓库的 star、fork、commit、pull request、issue 等相关数据,是分析和了解代码仓库的客观依据,这些数据在一定程度上反应了开源项目的受欢迎程度、活跃度、影响力等。
RepoStats 致力于解决的痛点问题是:
- 开源代码仓库的数据抓取、存储、分析及统计 (当前版本仅支持 Gitee 平台)
- 开源代码仓库的相关数据可视化展示
- 做到全平台打通,并支持分隔、组合展示
主要原理示意图如下:
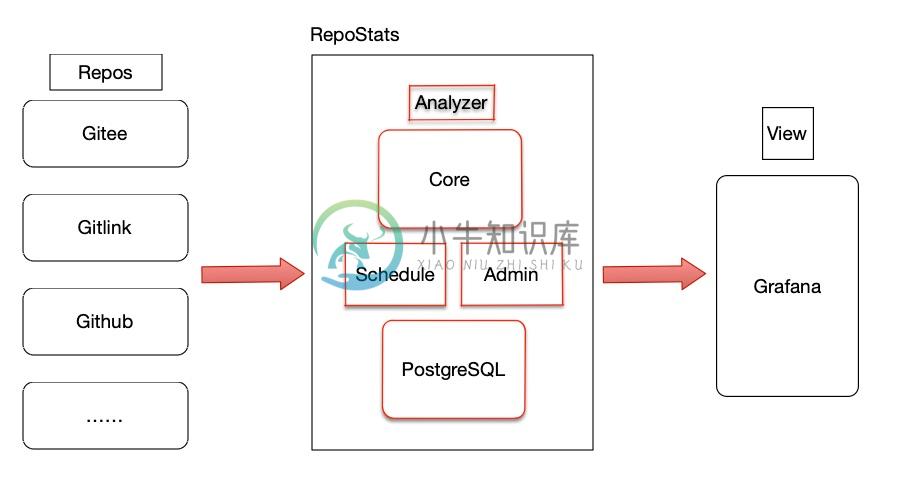
功能说明
- 当前版本的 RepoStats 仅支持 Gitee 平台相关数据获取 (后续会持续新增其他平台,国产平台优先考虑)
- 管理后台:支持界面化的 Gitee Oauth 配置、Grafana Token 获取配置
- 管理后台:支持添加单个仓库、支持批量添加个人帐号及组织帐号下的公开仓库
- 管理后台:支持禁用、启用 Gitee 数据抓取(启动抓取除外)
- 管理后台:支持 Commit 列表显示及查询、Issue 列表显示及查询、Pull Request 列表显示及查询
- Grafana 标签:每个面板均有附带仓库拥有者标签、仓库名称、平台名称等信息支持查询过滤
统计指标说明
RepoStats 当前版本支持3大类共计21项统计数据可视化结果展示,这些统计数据不能表示一个开源项目的好与坏,仅从数据层面对开源代码仓库进行一定的展示。这些数据指标分类以下三类:
1. 统计汇总
统计汇总 分类中展示的数据,与时间无关,它们代表的是所有项目(Gitee Overview)后者是某个指定的项目的汇总数据结果,其中包括:
-
仓库统计
当前抓取的仓库总数量、总 Star 人数、总 Fork 人数、总 Watch 人数 -
基本信息
当前仓库的 Star 人数、Fork 人数、Watch 人数 -
Commit 统计
Commit 总数、Commit Author 总数(去重)、Commit Committer 总数(去重) -
Issue 统计
Issue 综述、Issue 总人数、打开状态的 Issue 总数、已关闭状态的 Issue 总数、已拒绝状态的 Issue 总数、处理中的 Issue 总数 -
Issue 状态图
已关闭、已拒绝、打开、处理中 状态的 Issue 占比示意图 -
Pull Request 统计
Pull Request 总数、Pull Request 人数、打开状态的 Pull Request 总数、已合并状态的 Pull Request 总数、已关闭状态的 Pull Request 总数 -
Pull Request 状态图
已合并、打开、已关闭 的 Pull Reqeust 占比示意图 -
Issue 处理时间分析
所有 Issue 从created_at到finished_at的最小耗时、平均耗时、最大耗时,单位:小时 -
Pull Request 合并时间分析
所有可合并的Pull Request 从created_at到merged_at的最小耗时、平均耗时、最大耗时,单位:小时
2. 动态趋势
动态趋势 分类中展示的数据,是 某个时间段内 数据量的动态变化过程,可以通过 Grafana 面板右上角的时间选项查看指定时间范围内的变化趋势,其中包括:
-
Star 趋势图
指定时间范围内,关注仓库的总人数变化趋势 -
Commit 趋势图
指定时间范围内,Commit 提交次数的变化趋势 -
Issue 趋势图
指定时间范围内,新增 Issue 数的变化趋势 -
Pull Request 趋势图 指定时间范围内,新增 Pull Request 数的变化趋势
-
Pull Request 合并时间分析 指定时间范围内,
可合并的Pull Request 从created_at到merged_at的最小耗时、平均耗时、最大耗时,单位:小时 -
Issue 处理时间分析
指定时间范围内,新增的 Issue 从created_at到finished_at的最小耗时、平均耗时、最大耗时,单位:小时
3. 数据列表
数据列表 分类中展示的数据,与时间无关,它们代表的是所有项目(Gitee Overview)后者是某个指定的项目的汇总数据结果,其中包括:
-
仓库列表
所有仓库的明细列表 -
Commit 列表
Commit 明细列表 -
Issue 列表 Issue 明细列表
-
Pull Request 列表
Pull Request 明细列表 -
Commit Author 排行
Commit Auhtor 次数排行 -
Commit Committer 排行 Commit Committer 次数排行
数据抓取策略
RepoStats 启动之后,默认情况下每隔 6小时 抓取一次数据并更新 Grafana 视图面板
Screenshots
-
所有仓库总视图
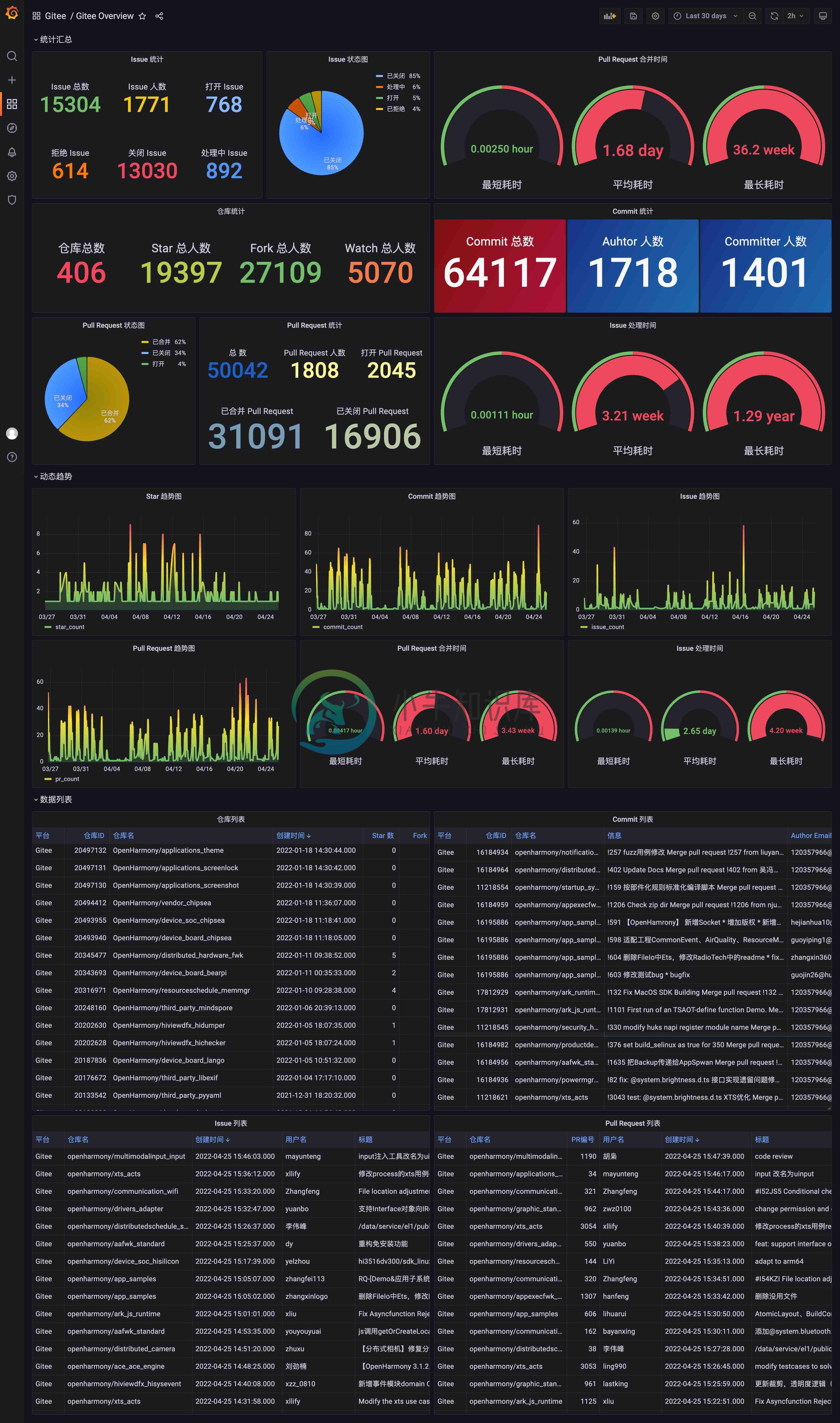
-
指定某个仓库的视图
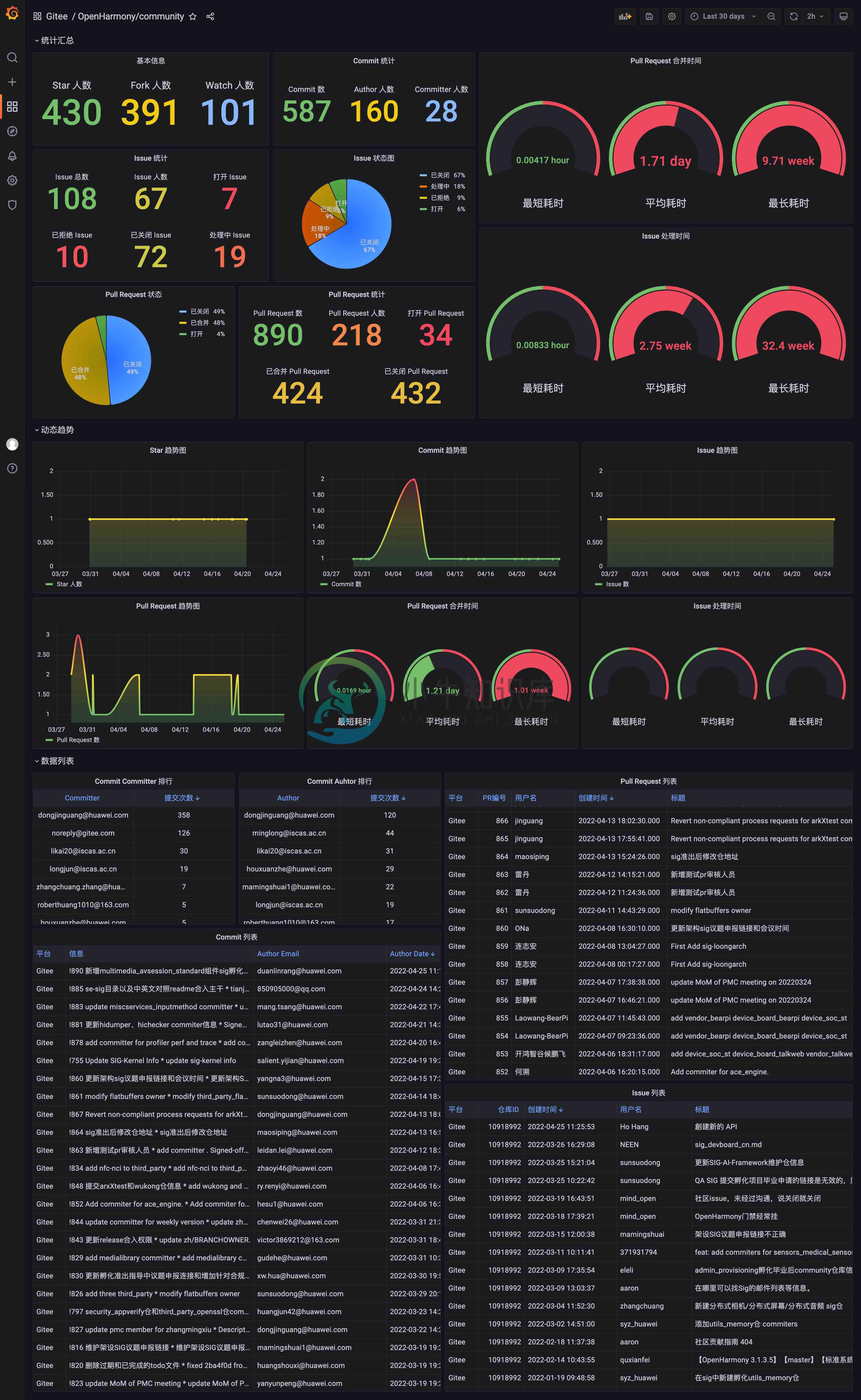
-
Admin 后端管理界面
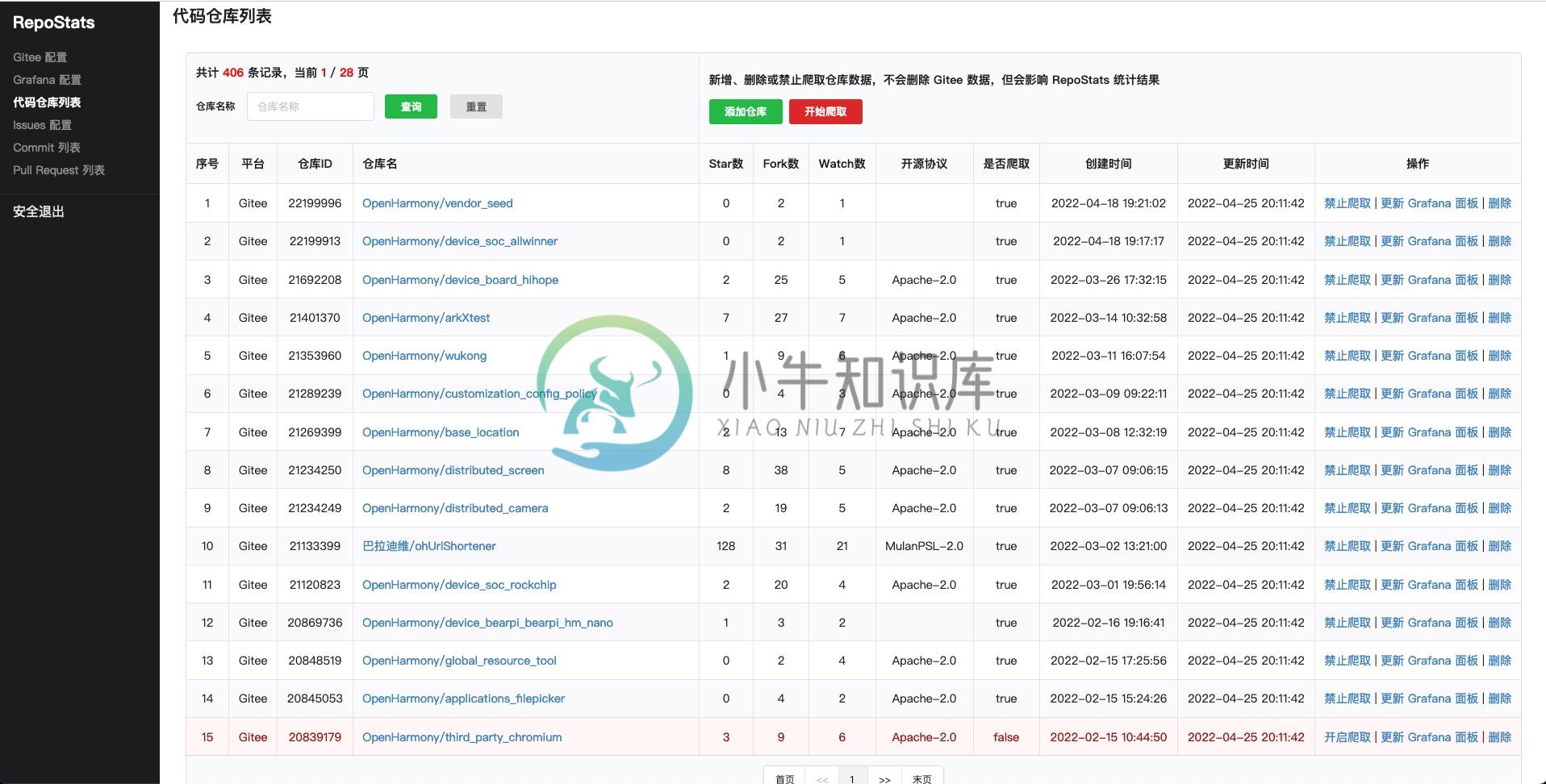
-
本文向大家介绍MongoDB开源数据库开发工具dbKoda,包括了MongoDB开源数据库开发工具dbKoda的使用技巧和注意事项,需要的朋友参考一下 Southbank Software公司最近发布了 dbKoda 0.6.0 ,这是该软件的 首个发布版 。dbKoda是一款开源的 MongoDB 开发工具,采用JavaScript、 React 和 Electron 开发。下图显示了dbKod
-
本文向大家介绍开源数据库,包括了开源数据库的使用技巧和注意事项,需要的朋友参考一下 开源数据库是具有开源代码的数据库,即任何人都可以查看,研究甚至修改代码。开源数据库可以是关系(SQL)或非关系(NoSQL)。 为什么要使用开源数据库? 为任何公司创建和维护数据库都非常昂贵。在软件总支出中,很大一部分用于处理数据库。因此,切换到低成本开源数据库是可行的。从长远来看,这可以为公司节省很多钱。 使用中
-
我正在努力让Spring JPA Data为我工作,但一直在努力。问题出在这里。 我有两个域类,它们之间有一个简单的一对多关系: 我已经为每个类设置了存储库接口:CardRepository,扩展JpaRepository的用户存储库,两个存储库都注入到服务中 非常基本的设置。someMethod() 出现问题,其中我用它的标识符查询了一个用户,然后尝试获取映射@OneToMany的列表,然后发生
-
在使用Spring数据存储库时发现一些奇怪的行为。 我写了这些类和接口: 当我尝试测试UserRepositoryImpl时,java。lang.StackOverflowerr被抛出 我发现save()方法存在一些问题。此外,delete()方法会引发stackoverflow。 我已经找到了解决办法。当我更改将存储库接口扩展为(例如)JpaUserRepository的接口的名称时,我的问题就
-
主要内容:1.离线数仓,2.Lambda架构,3.Kappa架构,4.Smack架构,5.湖仓一体传统数仓 离线数仓 实时数仓 Lambda架构 Kappa架构 Smack架构 数据湖架构 仓湖一体架构 1.离线数仓 2.Lambda架构 Lambda架构是大数据平台里最成熟、最稳定的架构,它的核心思想是:将批处理作业和实时流处理作业分离,各自独立运行,资源互相隔离。 (1)Batch Laye:主要负责所有的批处理操作,支撑该层的技术以Hive、Spark-SQL或MapReduce这类批处
-
火车票业务 有点久远一直忘了写,就记得这么多 一面: 1、自我介绍 2、聊实习,扣细节 3、聊实习项目技术难点,聊到了我用later view遇到的坑,面试官直接激动,并表示他前几天也碰到了这个坑,两边都很惊喜,直接惺惺相惜 4、聊竞赛经历,内容以及遇到的难点 5、开始八股,写吐了,这里就省略了,要看的看我之前的帖子 6、sql题,是啥忘了,难度中等吧 7、反问 二面 主管面: 1、自我介绍 2、