
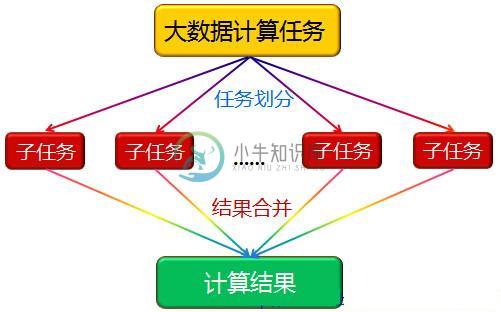
tinympi4j 是一款微型的 java 分布式离线计算框架, 实现原理如图:
特性
简单直观, 没有任何学习难度
slave支持多个任务并发/并行执行
使用HTTP协议通信
场景: 找素数/grep/wordcount/超大文件或大量小文件处理
不支持复杂数据类型
没有进度监控,健康监控,无容错功能
例子: 用两台服务器分布式计算找出10000以内的素数
public static void main(String[] args) {
//启动master上的tomcat
final int masterport = 8086;
final String masterurl = "http://192.168.1.100:" + masterport;
TomcatTool.startMasterTomcat(masterport);
//创建任务
final BigTask<Integer> bigtask = BigTask.create(masterurl);
//添加任务到两台计算节点, 请确保计算节点上的 tinympi4j-slave 已启动
//关于计算节点: https://github.com/binaryer/tinympi4j-slave
bigtask.addTask2Slave("http://192.168.1.101:1234", PrimeSplitedtask.class, new Integer[] { 2, 5000 });
bigtask.addTask2Slave("http://192.168.1.102:1234", PrimeSplitedtask.class, new Integer[] { 5001, 10000 });
//等待所有节点执行完毕
final Collection<Integer> resultset = bigtask.executeAndWait();
//打印结果
for (int n : resultset){
//System.out.println(n);
}
}-
会点java,做点web,基本也就是spring全家桶,所以打算自己折腾一个,实现最基本最常用的一些功能。断断续续地终于完成了大部分自己想要的功能。实际项目中使用或许还不太现实,不过也提供了一个去了解框架实现的一个简单的版本,也让大家有动力有思路自己去实现一个,源码请戳github。 IOC IOC很大程度借鉴了Spring,简单的使用 ApplicationContext application
-
一、MapReduce概述 Hadoop MapReduce 是一个分布式计算框架,用于编写批处理应用程序。编写好的程序可以提交到 Hadoop 集群上用于并行处理大规模的数据集。 MapReduce 作业通过将输入的数据集拆分为独立的块,这些块由 map 以并行的方式处理,框架对 map 的输出进行排序,然后输入到 reduce 中。MapReduce 框架专门用于 <key,value> 键值
-
类型 实现框架 应用场景 批处理 MapReduce 微批处理 Spark Streaming 实时流计算 Storm
-
其于职业介绍所、工头、工人、工作模型的分布式计算框架。 职业介绍所有两种,一种是本地职业介绍所,一种是远程职业介绍所。顾名思义,本地职业介绍所就是在当前计算机上的,远程职业介绍所用于连接到远程职业介绍所的。 工人、工头都可以加入到职业介绍所,所以加到本地或远程种业介绍所都是可以的。 在同一个职业介绍所中,具有同样类型的工人、工头和工作都存在的时候,工作就可以被安排下去执行。当然,有两种安排方式,一
-
本章将重点介绍如何开始使用分布式TensorFlow。目的是帮助开发人员了解重复出现的基本分布式TF概念,例如TF服务器。我们将使用Jupyter Notebook来评估分布式TensorFlow。使用TensorFlow实现分布式计算如下所述 - 第1步 - 为分布式计算导入必需的模块 - 第2步 - 使用一个节点创建TensorFlow集群。让这个节点负责一个名称为“worker”的作业,并在
-
在介绍GraphX之前,我们需要先了解分布式图计算框架。简言之,分布式图框架就是将大型图的各种操作封装成接口,让分布式存储、并行计算等复杂问题对上层透明,从而使工程师将焦点放在图相关的模型设计和使用上,而不用关心底层的实现细节。 分布式图框架的实现需要考虑两个问题,第一是怎样切分图以更好的计算和保存;第二是采用什么图计算模型。下面分别介绍这两个问题。 1 图切分方式 图的切分总体上说有点切分和边切
-
主要内容:1.RPC流水线工程,2.RPC 技术选型,3.如何设计 RPC1.RPC流水线工程 ① Client以本地调用的方式调用服务 ② Client Stub接收到调用后,把服务调用相关信息组装成需要网络传输的消息体,并找到服务地址(host:port),对消息进行编码后交给Connector进行发送 ③ Connector通过网络通道发送消息给Acceptor ④ Acceptor接收到消息后交给Server Stub ⑤ Server Stub对消息进行解码,
-
主要内容:一、从一个新闻门户网站案例引入,二、推算一下你需要分析多少条数据?,三、黄金搭档:分布式存储+分布式计算这篇文章聊一个话题:什么是分布式计算系统? 一、从一个新闻门户网站案例引入 现在很多同学经常会看到一些名词,比如分布式服务框架,分布式系统,分布式存储系统,分布式消息系统。 但是有些经验尚浅的同学,可能都很容易被这些名词给搞晕。所以这篇文章就对“分布式计算系统”这个概念做一个科普类的分析。 如果你要理解啥是分布式计算,就必须先得理解啥是分布式存储,现在我们从一个小例子来引入。 比如说
-
如何计算大的皮尔逊互相关矩阵( 更新:我读了阿帕奇火花的实现 但对我来说,看起来所有的计算都发生在一个节点上,而不是真正意义上的分布式。 请在这里放一些光。我还尝试在3节点火花群集上执行它,下面是屏幕截图: 正如您从第二张图中看到的,数据在一个节点上被拉起,然后进行计算。我在这里对吗?