
Presto是Facebook最新研发的数据查询引擎,可对250PB以上的数据进行快速地交互式分析。据称该引擎的性能是 Hive 的 10 倍以上。
PrestoDB 是 Facebook 推出的一个大数据的分布式 SQL 查询引擎。可对从数 G 到数 P 的大数据进行交互式的查询,查询的速度达到商业数据仓库的级别。
Presto 可以查询包括 Hive、Cassandra 甚至是一些商业的数据存储产品。单个 Presto 查询可合并来自多个数据源的数据进行统一分析。
Presto 的目标是在可期望的响应时间内返回查询结果。Facebook 在内部多个数据存储中使用 Presto 交互式查询,包括 300PB 的数据仓库,超过 1000 个 Facebook 员工每天在使用 Presto 运行超过 3 万个查询,每天扫描超过 1PB 的数据。此外包括 Airbnb 和 Dropbox 也在使用 Presto 产品。
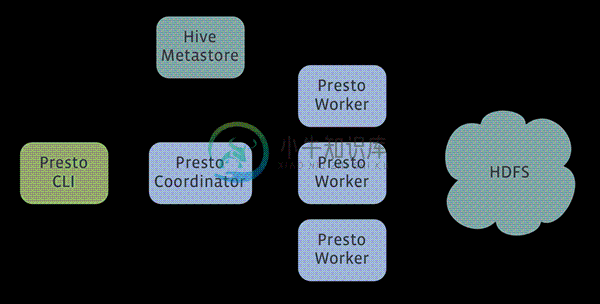
Presto 是一个分布式系统,运行在集群环境中,完整的安装包括一个协调器 (coordinator) 和多个 workers。查询通过例如 Presto CLI 的客户端提交到协调器,协调器负责解析、分析和安排查询到不同的 worker 上执行。
此外,Presto 需要一个数据源来运行查询。当前 Presto 包含一个插件用来查询 Hive 上的数据,要求:
-
Hadoop CDH4
-
远程 Hive metastore service
Presto 不使用 MapReduce ,只需要 HDFS

要求:
-
Mac OS X or Linux
-
Java 7, 64-bit
-
Maven 3 (for building)
-
Python 2.4+ (for running with the launcher script)
-
# prestodb安装配置 —参考prestodb官方文档配置 # by coco # 20160225 目前prestodb最新版本已经到了0.139,但是官方给出的配置文档还是0.100的,所以就选取了0.100版本的进行配置测试。 1. 安装环境 操作系统:CentOS release 6.2 (Final) hadoop集群:CDH-5.5.1-1 JDK版本:jdk1.8.0_73 注
-
1、准备一个5节点的cassandra集群 略 node1,node2,node3,node4,node5 2、在node1上下载presto wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.131/presto-server-0.131.tar.gz 3、解压缩 tar zxvf presto-ser
-
hive 优点 缺点 被广泛应用,经受时间的考验 既然是基于Mapreduce,也拥有MapReduce所有缺点,包含昂贵的Shuffle操作和磁盘IO操作 运行在Mapreduce框架之上 hive仍然不支持多个reduce操作group by和order by查询 非常好的支持用户自定义函数 和其他竞品相比,查询速度很慢 很友好的和hbase等系统结合 cloudera impala 优点 缺
-
presto-cli模块 概要 该模块主要负责查询SQL的客户端功能,利用RESTful请求发送给Coordinator实现SQL语句的查询。 PrestoDB可以通过presto-cli客户端和JDBC连接这两种方法实现SQL的查询。 presto-cli模块查询流程:通过用户输入SQL将语句组装成一个RESTful请求,发送给Coordinator执行该SQL,并启动查询方法,分批查询结果和用
-
安装条件 1.docker docker镜像下载 我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客: 下载地址: prestodb-sandbox 执行下载镜像命令: sudo docker pull ahanaio/prestodb-sandbox 查看镜像是否下载成功: sudo docker i
-
presto0.169版本对postgresql9.6.9支持还可以,高版本就不行了 1.建用户 [root@localhost ~]# useradd presto [root@localhost ~]# passwd presto 2.安装jdk8 [presto@localhost ~]$ cat .bash_profile 。。。。。。 export PATH=$PATH:$HOME/jd
-
PrestoDB首页、文档和下载 - 大数据查询引擎 - 开源中国社区 PrestoDB首页、文档和下载 - 大数据查询引擎 - 开源中国社区 posted on 2016-01-27 17:23 lexus 阅读( ...) 评论( ...) 编辑 收藏 转载于:https://www.cnblogs.com/lexus/p/5163986.html
-
问题内容: 我有几个查询,其中大多数是: 和 由于它们都是一个范围,因此在col和date上使用未聚类的b +树索引会是加快查询速度的一个好主意吗?还是哈希索引?还是没有索引会更好? 问题答案: 在 过滤谓词上 用作 日期范围条件 的列上创建 INDEX 应该很有用,因为它将执行 INDEX RANGE SCAN 。 这是有关如何在Oracle中创建,显示和阅读EXPLAIN PLAN 的演示。
-
概述 使用find()方法在MongoDB集合中查询数据。MongoDB所有的查询范围都是单个集合的。也就是说MongoDB不能跨集合查询数据。 查询可以返回集合中的所有文档,或者仅仅返回指定过滤条件的文档。你可以指定一个过滤条件或才一个判断条件作为参数传递给find()方法。 find()方法在一个游标中返回所有的结果集,通过游标的迭代可以输出所有文档。 查询集合中的所有文档 查询集合中的所有文
-
获取单个数据 获取单个数据的方法包括: 取出主键为1的数据 $user = UserModel::get(1); echo $user->user_nickname; // 使用数组查询 $user = UserModel::get(['user_nickname' => '老猫']); // 使用闭包查询 $user = UserModel::get(function($query){
-
数据库操作使用 Db类封装方法,请事先在引入 Db类 use think\Db; 以上可以引入 Db,后面的文档不再说明,直接使用; 查询一个数据使用: // table方法必须指定完整的数据表名 Db::name('user')->where('id',1)->find(); find 方法查询结果不存在,返回 null 查询数据集使用: Db::name('user')->where('s
-
获取单个数据 获取单个数据的方法包括: 取出主键为1的数据 $user = UserModel::find(1); echo $user->user_nickname; 如果你是在模型内部,请不要使用$this->user_nickname的方式来获取数据,请使用$this->getAttr('user_nickname') 替代。 或者在实例化模型后调用查询方法 $user = new Use
-
数据库操作使用 Db类封装方法,请事先在引入 Db类 use think\facade\Db; 以上可以引入 Db,后面的文档不再说明,直接使用; 查询一个数据使用: // table方法必须指定完整的数据表名 Db::name('user')->where('id',1)->find(); find 方法查询结果不存在,返回 null 查询数据集使用: Db::name('user')->w