
Thanos 是一组可以组成具有长期存储期限的高可用指标系统的组件,可以将其无缝添加到现有 Prometheus 部署之上。
Thanos 利用 Prometheus 2.0 存储格式在任何对象存储中经济高效地存储历史指标数据,同时保留快速查询可能。另外,它提供了所有 Prometheus 的全局查询视图,并且可以即时合并 Prometheus HA 对中的数据。
该项目的具体目标是:
- 指标的全局查询视图。
- 指标的无限保留。
- 组件的高可用性,包括 Prometheus。
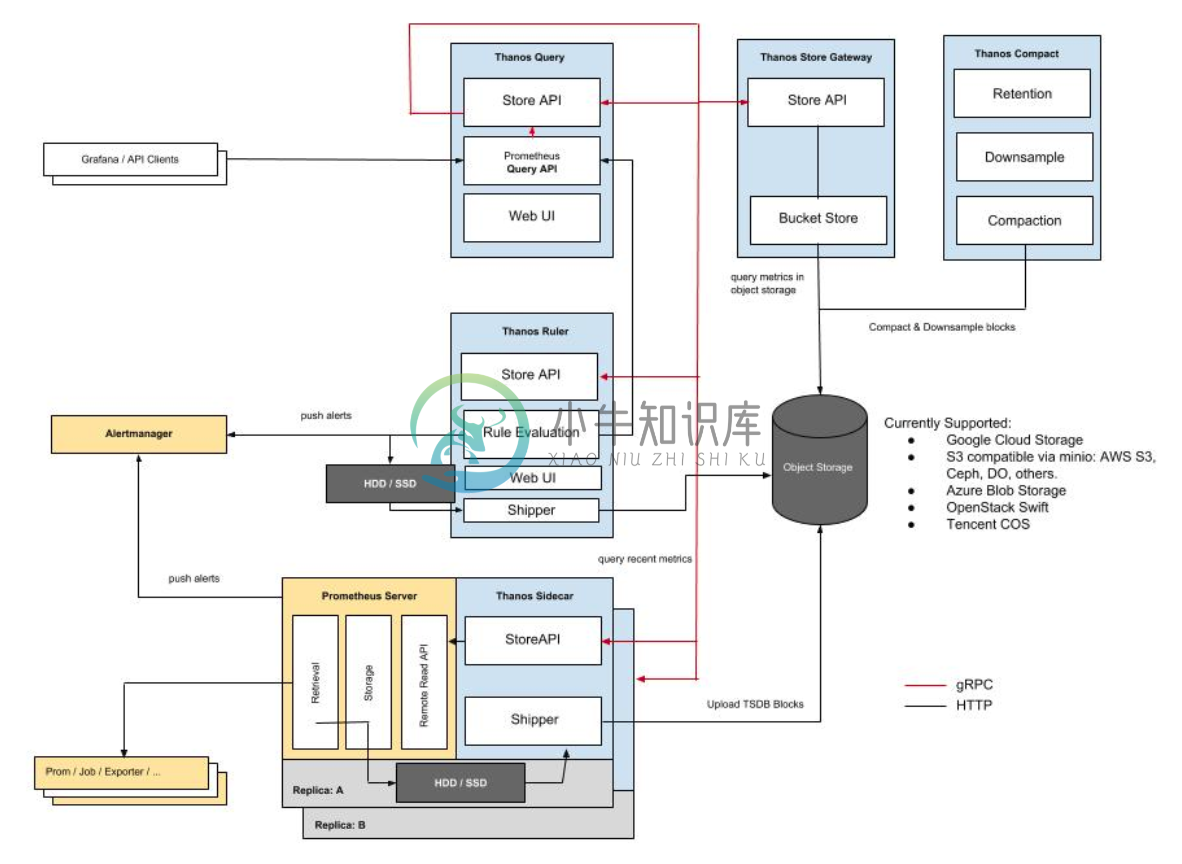
特性:
- 跨所有连接的 Prometheus 服务器的全局查询视图
- 重复数据删除和合并从 Prometheus HA 对中收集的指标
- 与现有 Prometheus 设置无缝集成
- 任何对象存储都是其唯一的、可选的依赖关系
- 对历史数据进行下采样以大幅提高查询速度
- 跨集群联合
- 容错查询路由
- 简单的 gRPC“Store API”,可跨所有指标数据进行统一数据访问
-
Kubernetes v1.9 单集群最大支持 5000 个节点,也就是说 Kubernetes 最新稳定版的单个集群支持 不超过 5000 个节点 不超过 150000 个 Pod 不超过 300000 个容器 每台 Node 上不超过 100 个 Pod 公有云配额 对于公有云上的 Kubernetes 集群,规模大了之后很容器碰到配额问题,需要提前在云平台上增大配额。这些需要增大的配额包括
-
本文向大家介绍redis集群规范详解,包括了redis集群规范详解的使用技巧和注意事项,需要的朋友参考一下 本文档翻译自 http://redis.io/topics/cluster-spec 。 引言 这个文档是正在开发中的 Redis 集群功能的规范(specification)文档, 文档分为两个部分: 第一部分介绍目前已经在 unstable 分支中实现了的那些功能。 第二部分介绍目前仍未
-
问题内容: 在启动时,我正在为我们的数据库考虑扩展解决方案。MySQL至少使我感到困惑(至少对我而言),MySQL具有MySQL群集,复制和MySQL群集复制(来自5.1.6版),它是MySQL群集的异步版本。MySQL手册解释了其集群FAQ中的一些差异,但是很难确定何时使用它们中的一个。 我将不胜感激那些熟悉这些解决方案之间的区别以及优点和缺点以及何时建议使用每种解决方案的人的任何建议。 问题答
-
我们使用 Giantswarm 开源的 kubernetes-promethues 来监控 kubernetes 集群,所有的 YAML 文件可以在 ../manifests/prometheus 目录下找到。 需要用到的镜像有: harbor-001.jimmysong.io/library/prometheus-alertmanager:v0.7.1 harbor-001.jimmysong.
-
本文向大家介绍socket.io与pm2(cluster)集群搭配的解决方案,包括了socket.io与pm2(cluster)集群搭配的解决方案的使用技巧和注意事项,需要的朋友参考一下 socket.io与cluster 在线上系统中,需要使用node的多进程模型,我们可以自己实现简易的基于cluster模式的socket分发模型,也可以使用比较稳定的pm2这样进程管理工具。在常规的http服务
-
问题内容: 在我们的开发人员和生产SQL Server之间,数据库,表和某些列的排序规则存在差异,这对开发造成了严重破坏。事情将在dev上运行,然后在升级时由于归类冲突而中断,数据和结构将从prod复制到dev,这又由于冲突而中断对dev的查询,等等。我们将通过明确定义有时会在查询中使用COLLATION选项,或者在有问题的表中设置每一列的排序规则来解决该问题。前者似乎在性能上受到打击,而后者是P