
TSharding 是 应用于蘑菇街交易平台的一个简易 sharding 组件,也是一个 Mybatis 分库分表组件。
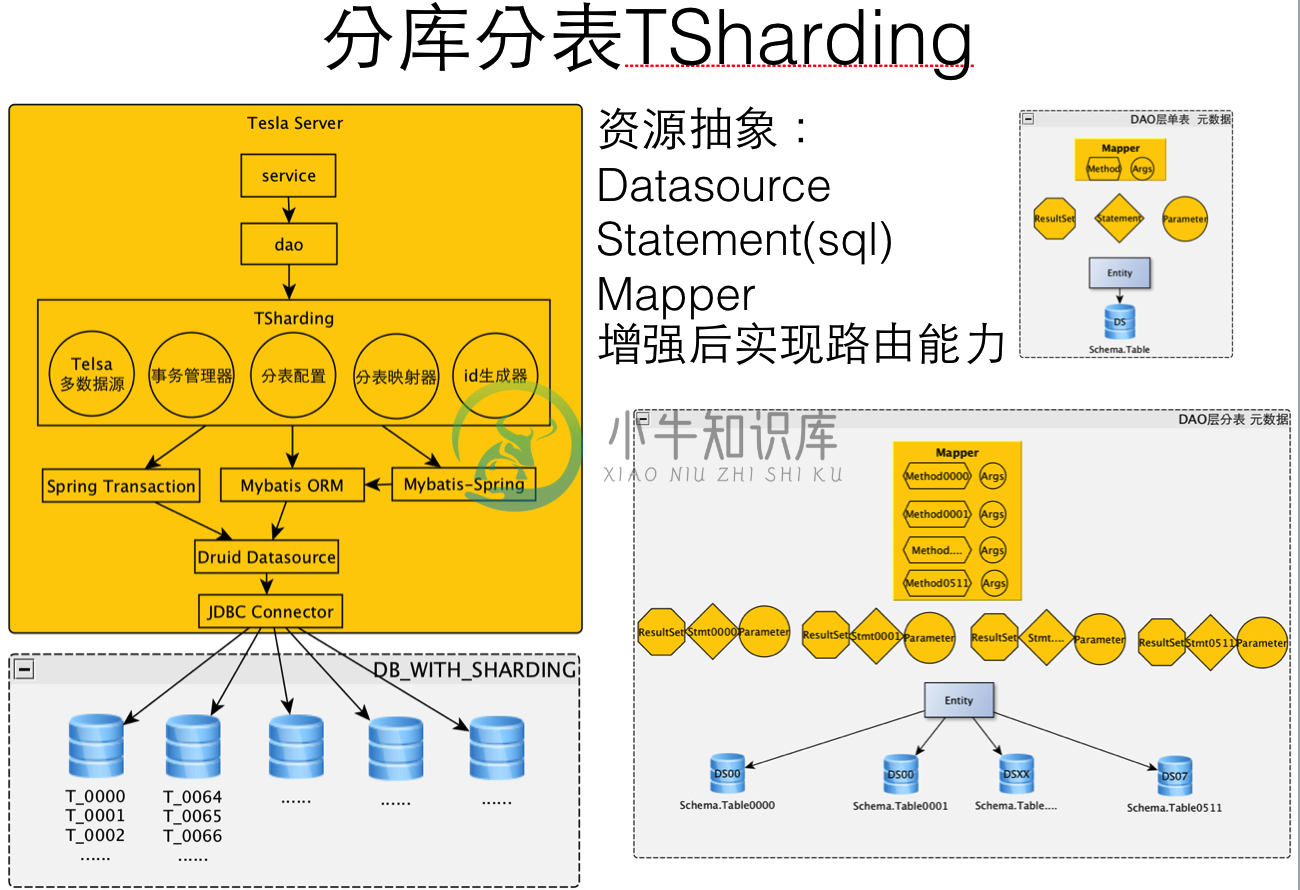
TSharding 组件目标:
很少的资源投入即可开发完成
支持交易订单表的Sharding需求,分库又分表
支持数据源路由
支持事务
支持结果集合并
支持读写分离
关键类:
测试用例入口 com.mogujie.service.tsharding.test#TShardingTest
默认走 Master 库的前缀命名 com.mogujie.trade.tsharding.route.orm.base.ReadWriteSplittingContextInitializer.DEFAULT_WRITE_METHOD_NAMES
SQL增强 com.mogujie.trade.tsharding.route.orm.MapperResourceEnhancer.enhancedShardingSQL
TSharding 组件接入过程:
引入TSharding JAR 包
配置所有分库的 JDBC 连接信息
Mybatis Mapper 方法参数增加 ShardingOrderPara/ShardingBuyerPara/ShardingSellerPara 注解
批量查询增加结果集合并逻辑
测试用例:
跑测试用例之前先建库建表结构;理论上是8个库,512张表,每个库64张表。如果仅仅是跑测试用例,执行下面的sql就可以跑通:
create database trade0000; create database trade0001; create database trade0002; create database trade0003; create database trade0004; create database trade0005; create database trade0006; create database trade0007; create database trade; use trade0001; CREATE TABLE `TradeOrder0064` ( `orderId` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '订单ID', `buyerUserId` bigint(20) unsigned NOT NULL COMMENT '买家的userId', `sellerUserId` bigint(20) unsigned NOT NULL COMMENT '卖家的userId', `shipTime` int(11) unsigned DEFAULT '0' COMMENT '发货时间', PRIMARY KEY (`orderId`) ) ENGINE=InnoDB AUTO_INCREMENT=10000 DEFAULT CHARSET=utf8mb4 COMMENT='订单信息表'; INSERT INTO `TradeOrder0064` (`orderId`, `buyerUserId`, `sellerUserId`, `shipTime`) VALUES (50000280834672, 1234567, 2345678, 12345678);
-
主要内容:1.ShardingSphere概念,2.功能列表,3.项目状态,4.分库分表_结果归并1.ShardingSphere概念 ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由、和 这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务 和 数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。 Apache ShardingSphere 旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现
-
主要内容:1.数据库瓶颈,2.垂直切分,3.水平切分,4.数据分片规则,5.分库分表带来的问题1.数据库瓶颈 不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值。在业务Service来看就是,可用数据库连接少甚至无连接可用。 (并发量、吞吐量、崩溃)。 1.1 IO瓶颈 第一种:磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询时会产生大量的IO,降低查询速度 -> 分库和垂直分表。 第二种:网络IO瓶颈,请求的数据太多,
-
ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar(计划中)这 3 款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。 架构 Sharding-JDBC 定位为轻量级 J
-
该文档主要介绍Zebra分库分表ShardDataSource的接入和使用,主要包括分库分表的背景知识、ShardDataSource的配置、分库分表规则的配置等。 2 准备 2.1 背景介绍 在一个业务刚上线时,可能使用某个单表存储数据。随着时间的推移和用户的增加,单表内的数据量会不断变大,总有一天数据量会大到一个难以处理的地步。这时仅仅一张表的数据就可能过亿甚至更多,无论是查询还是修改,对于它
-
读写分离,主要是为了数据库读能力的水平扩展(参考:Zebra读写分离介绍) 一旦业务表中的数据量大了,从维护和性能角度来看,无论是任何的 CRUD 操作,对于数据库而言都是一件极其耗费资源的事情。即便设置了索引, 仍然无法掩盖因为数据量过大从而导致的数据库性能下降的事实 ,这个时候就该对数据库进行 水平分区 (sharding,即分库分表 ),将原本一张表维护的海量数据分配给 N 个子表进行存储和
-
本文介绍了 DM 提供的分库分表的合并迁移功能,此功能可用于将上游 MySQL/MariaDB 实例中结构相同/不同的表迁移到下游 TiDB 的同一个表中。DM 不仅支持迁移上游的 DML 数据,也支持协调迁移多个上游分表的 DDL 表结构变更。 简介 DM 支持对上游多个分表的数据合并迁移到 TiDB 的一个表中,在迁移过程中需要协调各个分表的 DDL,以及该 DDL 前后的 DML。针对用户的