
Maxtable是一个高性能、可扩展的、PB级海量数据处理系统。
Maxtable的特点有:
- 可扩展 (在任何时候都可以添加服务节点)
- 强一致性(一条数据在插入/删除/更新后,只要客户端返回成功,该数据即可被后续操作访问,以及支持数据恢复,保证数据不丢失)
- 支持Secondary index(支持在任何column上创建索引)
Maxtable目前的应用领域主要包括:
- 内容管理,如大型云环境的元数据管理,或者大型key-value系统的key管理。
- 实时数据查询分析领域。目前maxtable支持range query,where等条件查询,以及sum, count等统计操作
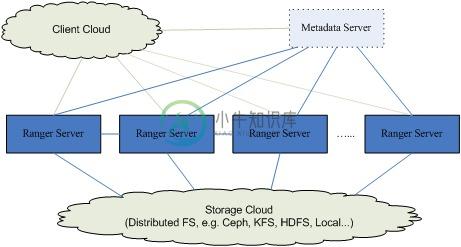
组件关系:
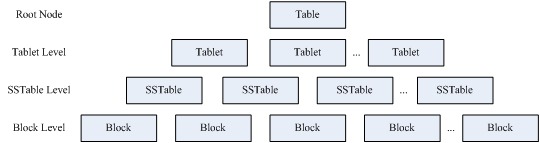
磁盘存储结构:
-
最近用maximo,感觉使用起来很不适应,分享点我常用的表 --MAXTABLE 系统表对象 select * from MAXTABLE where tablename like '你自己的表名%' --MAXDOMAIN 系统域登记 --MAXATTRIBUTE 系统对象各字段定义 select t.objectname,t.attributename , t.remarks ,
-
备忘 1 GB: 十亿个字节(Byte) 1(B) * 10*10^8 / 1024 / 1024 ≈ 953.67(MB) ≈ 1000(MB) ≈ 1(GB) 400 MB: 一亿个 4 字节(Byte) int 整型占用的内存 4(B) * 10^8 / 1024 / 1024 ≈ 381.57(MB) ≈ 382(MB) ≈ 400(MB) 10 亿个整型 -> 400(MB) * 10
-
所谓海量数据处理,无非就是基于海量数据上的存储、处理、操作。何谓海量,就是数据量太大,所以导致要么是无法在较短时间内迅速解决,要么是数据太大,导致无法一次性装入内存。 那解决办法呢? 针对时间,我们可以采用巧妙的算法搭配合适的数据结构,如Bloom filter/Hash/bit-map/堆/trie树。 针对空间,无非就一个办法:大而化小,分而治之(hash映射)。 二、算法/数据结构基础 1.
-
我的数据库中有大约1000万个blob格式的文件,我需要转换并以pdf格式保存它们。每个文件大小约为0.5-10mb,组合文件大小约为20 TB。我正在尝试使用spring批处理实现该功能。然而,我的问题是,当我运行批处理时,服务器内存是否可以容纳那么多的数据?我正在尝试使用基于块的处理和线程池任务执行器。请建议运行作业的最佳方法是否可以在更短的时间内处理如此多的数据
-
我正在实现spring批处理作业,用于使用分区方法处理一个DB表中的数百万条记录,如下所示- > 从分区器中的表中提取唯一的分区代码,并在执行上下文中设置相同的代码。 创建一个包含读取器、处理器和写入器的块步骤,以基于特定分区代码处理记录。 是否可以创建分区/线程来处理像thread1进程1-1000,thread2进程1001-2000等? 如何控制创建的线程数,因为分区代码可以是100个左右,
-
方法介绍 当遇到大数据量的增删改查时,一般把数据装进数据库中,从而利用数据的设计实现方法,对海量数据的增删改查进行处理。
-
方法介绍 什么是Bit-map 所谓的Bit-map就是用一个bit位来标记某个元素对应的Value, 而Key即是该元素。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。 来看一个具体的例子,假设我们要对0-7内的5个元素(4,7,2,5,3)排序(这里假设这些元素没有重复)。那么我们就可以采用Bit-map的方法来达到排序的目的。要表示8个数,我们就只需要8个Bit(1By
-
方法介绍 MapReduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。这样做的好处是可以在任务被分解后,可以通过大量机器进行并行计算,减少整个操作的时间。但如果你要我再通俗点介绍,那么,说白了,Mapreduce的原理就是一个归并排序。 适用范围:数据量大,但是数据种类小可以放入内存 基本原理及要点:将数据交给不同的机器去处理
-
方法介绍 1.1、什么是Trie树 Trie树,即字典树,又称单词查找树或键树,是一种树形结构。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是最大限度地减少无谓的字符串比较,查询效率比较高。 Trie的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。 它有3个基本性质: 根节点不包含字符,除根节点外每