
为了帮助企业用户寻找更为有效、加快Hadoop数据查询的方法,Apache 软件基金会发起了一项名为“Drill”的开源项目。Apache Drill 实现了 Google's Dremel.
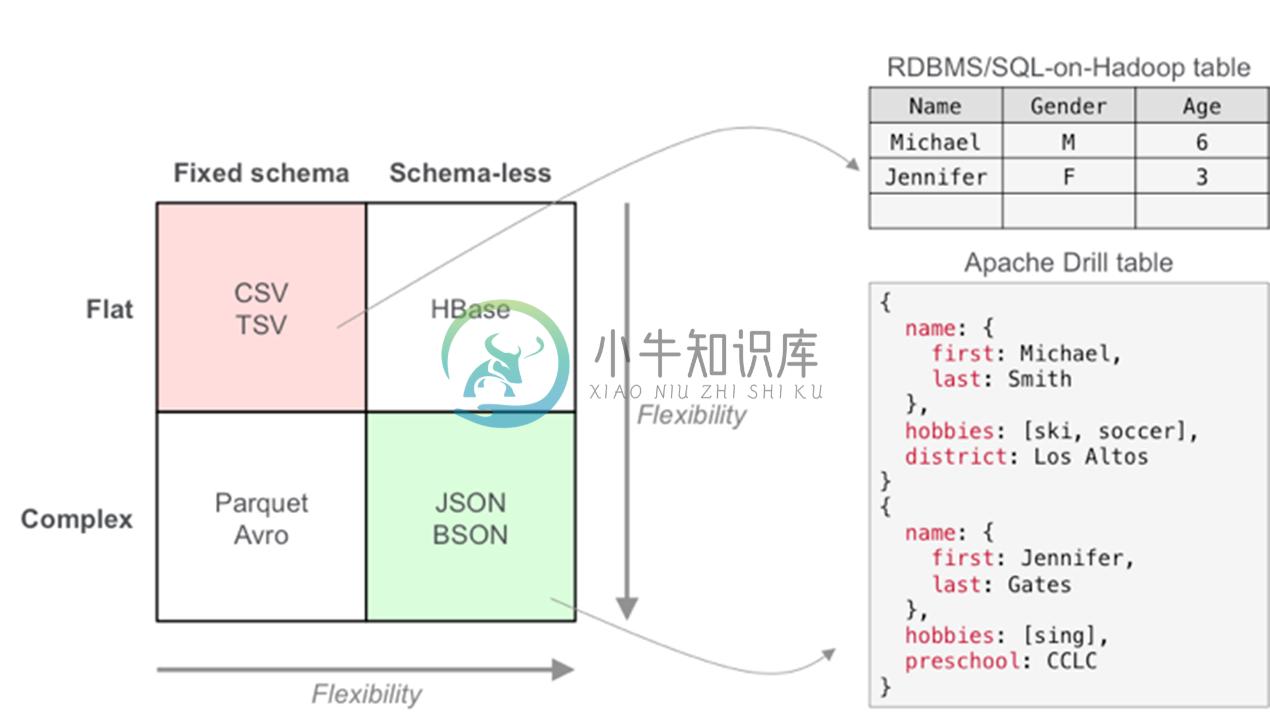
Apache Drill 在基于 SQL 的数据分析和商业智能(BI)上引入了 JSON 文件模型,这使得用户能查询固定架构,演化架构,以及各种格式和数据存储中的模式无关(schema-free)数据。该体系架构中关系查询引擎和数据库的构建是有先决条件的,即假设所有数据都有一个简单的静态架构。
Apache Drill 的架构师独一无二的。它是唯一一个支持复杂和无模式数据的柱状执行引擎(columnar execution engine),也是唯一一个能在查询执行期间进行数据驱动查询(和重新编译,也称之为 schema discovery)的执行引擎(execution engine)。这些独一无二的性能使得 Apache Drill 在 JSON 文件模式下能实现记录断点性能(record-breaking performance)。
该项目将会创建出开源版本的谷歌Dremel Hadoop工具(谷歌使用该工具来为Hadoop数据分析工具的互联网应用提速)。而“Drill”将有助于Hadoop用户实现更快查询海量数据集的目的。
数据结构:
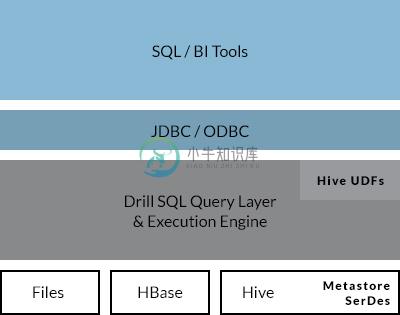
兼容已有的 SQL 环境和 Apache Hive:
“Drill”项目其实也是从谷歌的Dremel项目中获得灵感:该项目帮助谷歌实现海量数据集的分析处理,包括分析抓取Web文档、跟踪安装在Android Market上的应用程序数据、分析垃圾邮件、分析谷歌分布式构建系统上的测试结果等等。
通过开发“Drill”Apache开源项目,组织机构将有望建立Drill所属的API接口和灵活强大的体系架构,从而帮助支持广泛的数据源、数据格式和查询语言。
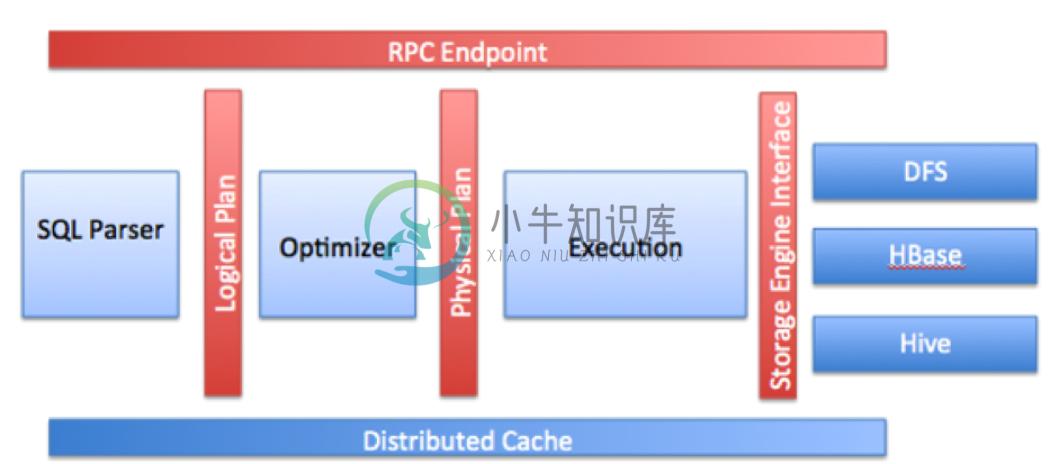
Drill 查询:
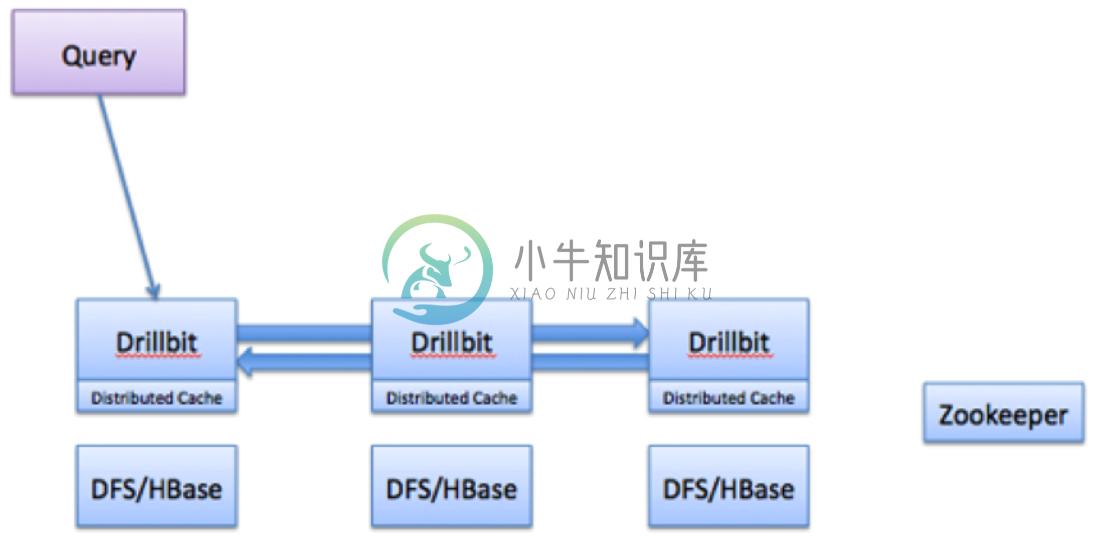
Drillbit 核心模型:
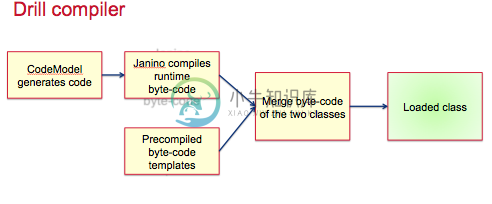
Drill 编译器:
-
drill apache 自2014年9月首次提供Beta版以来, Apache Drill一直在获得广泛的用户采用和社区动力。2015年5月发布了Drill的通用版本-Drill 1.0,此后大量客户在生产中部署和使用了Drill。 在这篇博客文章中,我将简要总结客户在Drill中发现非常宝贵的一些关键功能。 我还将介绍部署Drill的常见用例,以及Drill入门资源。 为什么Drill对客户具
-
问题内容: 我有以下查询: 目前,此查询大约需要93分钟才能完成。我想找到使它更快一点的方法。 该表大约有506,000行,其中大约490,000行包含的值,因此我怀疑我是否可以利用此处的任何索引。 该表(未压缩时)中包含约46 gigs的数据,但是该数据的大部分位于名为的文本字段中。我相信简单地加载和卸载许多页面会导致速度下降。一个想法是做一个新表 只是 在和现场,并保持尽可能小。但是,测试该理
-
我对工具包的结果计数有这样的输出格式: 我实现了一个循环来查询工具包,然后检查结果值中的相关性,如下所示: 不幸的是,这个解决方案非常缓慢。你对如何做到这一点有什么建议吗?多谢了。 编辑:因为项目太多,所以很慢。
-
本文向大家介绍django-rest-framework 加快序列化程序查询,包括了django-rest-framework 加快序列化程序查询的使用技巧和注意事项,需要的朋友参考一下 示例 假设我们有Travel很多相关领域的模型: 我们想/travels通过ViewViewSet构建CRUD 。 这是简单的视图集: 该ViewSet的问题在于我们的Travel模型中有许多相关字段,因此Dja
-
在Hadoop2 namenode上的Spark(0.9.1)shell中运行此示例 为什么我会得到这个?
-
问题内容: 这是我的问题,我正在选择并执行多个联接以获取正确的项目…它吸引了相当多的行,超过100,000。当日期范围设置为1年时,此查询将花费5分钟以上的时间。 我不知道是否可能,但恐怕用户会将日期范围扩展到10年左右并使其崩溃。 有人知道我可以如何加快速度吗?这是查询。 我不是MySQL方面的佼佼者,因此不胜感激! 提前致谢! 更新 这是您要求的解释 我还为table5行和table4行添加了
-
免责声明:我对Hadoop和Apache Ignite都不熟悉。抱歉冗长的背景信息。 设置:我已经安装并配置了Apache Ignite Hadoop加速器。全部启动。sh提供以下服务。我可以提交Hadoop作业。他们完成了,我可以看到预期的结果。start all使用传统的core站点、hdfs站点、mapred站点和Thread站点配置文件。 我还安装了Apache Ignite 2.6.0。
-
问题内容: 我有一个MySQL表,对此查询非常频繁。任何索引都可以帮助加快速度吗? 表中有几百万条记录。如果有什么方法可以加快搜索速度,是否会严重影响数据库文件对磁盘的使用以及and 语句的速度?(从未执行过) 更新 :发布后,我很快就看到了很多有关查询中使用方法的信息和讨论;我想指出,该解决方案 必须 使用(也就是说,我要查找的文本在前面加上%通配符)。由于多种原因,包括安全性,数据库也必须是本
-
然而,我们在hibernate日志中非常清楚地看到,它进行了100k次迭代。Hibernate有可能在你的关系中陷入循环吗? 或者也许这应该作为一个新的问题来问?