
扒网站工具,看好哪个网站,指定好URL,自动扒下来做成模版。所见网站,皆可为我所用!扒下来的网站,会自动变成html模版。js、css、图片等自动分好类,变为标准的模版文件。可以供网市场云建站、帝国CMS、织梦CMS等各大建站系统使用
软件界面
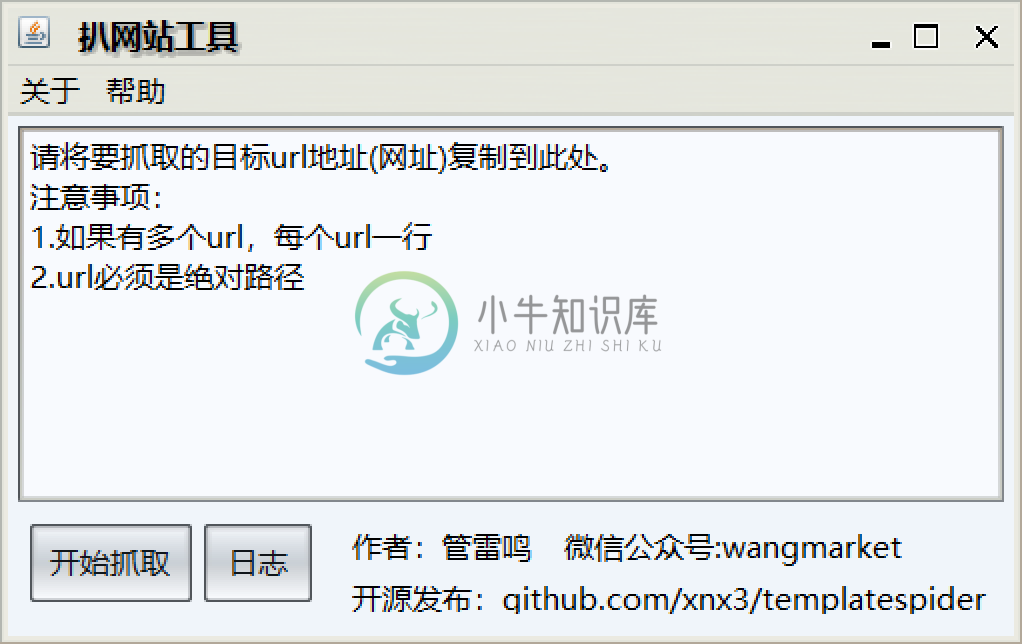
使用步骤
将要扒取的网站页面的网址粘贴进去
点击左下方"开始抓取"按钮
等待抓取完毕,自动打开下载好的文件夹
使用示例
例如,我要拔取 qiye1.wscso.com 这个网站中的首页、关于我们、新闻列表三个页面,拔取下来做成模板,扒网站工具中可以这么设置URL:
http://qiye1.wscso.com http://qiye1.wscso.com/gongsijieshao.html http://qiye1.wscso.com/xinwenzixun.html
设置如下图所示
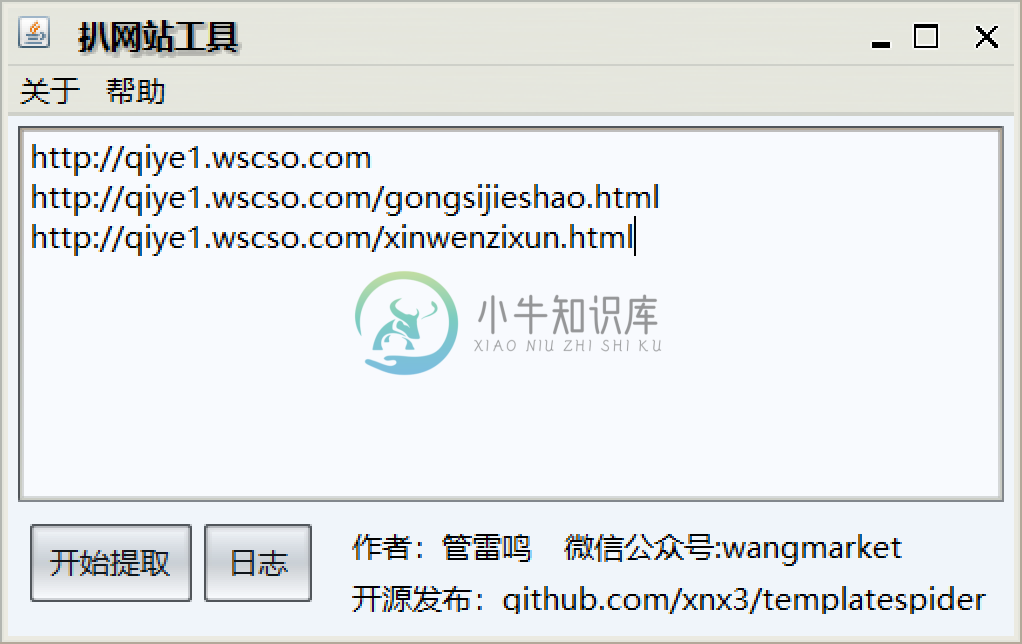
设置好后,点击左下角的"开始提取"按钮,便开始了自动扒这几个设置好的页面。
扒完后,会自动打开下载好的文件夹。例如,上面拔取的结果:
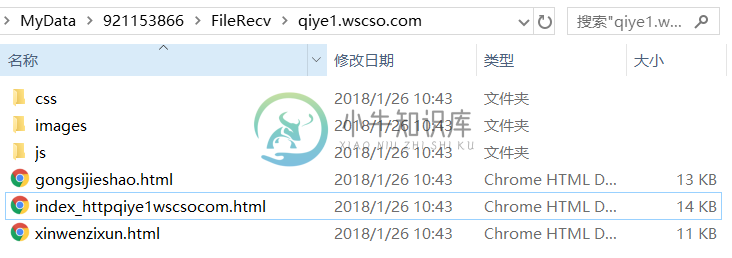
可以看到,扒取下来的网页算是很规范的模板页。可以直接打开模板页进行浏览查看。
-
完全新的Java和J汤。我试图创建一个简单的程序,刮网络,给我Java股市的数据。我想从道琼斯股票开始,让它打印出52周的区间数据。它转到http://finance.yahoo.com/quote/AAPL?ltr=1,查看左下表(从上一次收盘价开始),然后下到第5个索引,从那里获取文本值。我得到的错误: 线程“main”组织中出现异常。jsoup。选择选择器$SelectorParseExce
-
问题内容: 我需要抓取一个网站,其内容由Angular“插入”。它需要用java完成。 我已经尝试过Selenium Webdriver(因为我之前曾使用Selenium来抓取较少动态的网页)。但是我不知道如何处理Angular部分。除了页面顶部的script标签之外,网站中只有一个地方具有Angular属性: 我在这里找到了这篇文章,但是说实话…我不知道。看来作者正在选择(这样称呼他们)’ng-
-
在我的硕士论文中,我正在探索通过web自动化从网站中提取数据的可能性。步骤如下: 登录网站(https://www.metal.com/Copper/201102250376) 输入用户名和密码 单击登录 将日期更改为2020年1月1日 刮取生成的表格数据,然后将其保存到csv文件中 用我电脑上的特定名称保存到特定文件夹 运行相同的序列,在同一浏览器窗口的新选项卡中下载其他材料的其他历史价格数据
-
我正试图浏览一个网站。我尝试过使用两种方法,但都没有提供完整的网站源代码,我正在寻找。我正试图从下面提供的网站URL中获取新闻标题。 URL:"https://www.todayonline.com/" 这是我尝试过但失败的两种方法。 请帮忙。我试着抓取其他新闻网站,这要容易得多。谢谢你。
-
问题内容: 我需要从此网站Link中抓取新闻公告。公告似乎是动态生成的。它们不会出现在源代码中。我通常使用机械化,但是我认为它不会起作用。我该怎么办?我可以使用python或perl。 问题答案: 礼貌的选择是询问网站所有者是否具有允许您访问其新闻报道的API。 不太礼貌的选择是跟踪页面加载时发生的HTTP事务,并确定哪一个是AJAX调用,该调用会提取数据。 看起来就是这个。但是看起来它可能包含会
-
本文向大家介绍对python抓取需要登录网站数据的方法详解,包括了对python抓取需要登录网站数据的方法详解的使用技巧和注意事项,需要的朋友参考一下 scrapy.FormRequest login.py selenium登录获取cookie get_cookie_by_selenium.py 获取浏览器cookie(以Ubuntu的Firefox为例) get_cookie_by_firefo
-
问题内容: 我的问题是:如何从网抓取数据,但是直到您单击例如“ Danhsáchchậm”,该数据才显示。我已经非常认真地尝试,当您单击“ Danhsáchchậm”时,这是onclick事件,它触发了一些javascript函数js函数之一是从服务器获取数据并将其插入到标签/占位符中,并在这时,您可以使用firefox之类的方法检查数据,是的,数据会在网页上显示给用户/查看者。因此,我们又该如何
-
问题内容: 所以,我的问题相对简单。我有一只蜘蛛在多个站点上爬行,我需要它按照我在代码中写入的顺序返回数据。它发布在下面。 结果以随机顺序返回,例如,返回29,然后28,然后30。我已经尝试将调度程序的顺序从DFO更改为BFO,以防万一这是问题所在,但这并没有改变。 问题答案: 定义在方法中使用的URL 。下载页面时,将为你的方法调用每个起始URL的响应。但是你无法控制加载时间-第一个起始URL可