
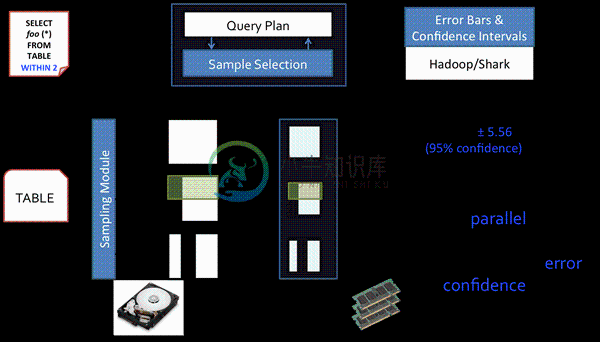
BlinkDB 是一个用于在海量数据上运行交互式 SQL 查询的大规模并行查询引擎。它允许用户通过权衡数据精度来提升查询响应时间,其数据的精度被控制在允许的误差范围内。
为了达到这个目标,BlinkDB 使用两个核心思想:
- 一个自适应优化框架,从原始数据随着时间的推移建立并维护一组多维样本;
- 一个动态样本选择策略,选择一个适当大小的示例基于查询的准确性和(或)响应时间需求。
我们已经使用了 TPC-H 基准测试来评估 BlinkDB 的性能,实际分析工作负载来自 Conviva Inc. 和在 Facebook Inc 的部署。
在 VLDB 2012 中,BlinkDB 演示了在 Amazon EC2 集群部署了 100 个节点,大约 17TB 的数据中查询不到 2 秒钟,比 Hive 快 200 倍,错误率在 2-10%。
-
BlinkDB是一个用于在海量数据上进行交互式SQL的近似查询引擎。 它允许用户通过在查询准确性和查询响应时间之间做出权衡,完成近似查询。 其数据的精度被控制在允许的误差范围内。 为了达到这个目标,BlinkDB的核心思想是:通过一个自适应优化框架,随着时间的推移,从原始数据建立并维护一组多维样本;通过一个动态样本选择策略,选择一个适当大小的示例,然后基于查询的准确性和响应时间满足用户查询需求。
-
在某些情况下,需要多次查询数据库,为了减少用户的等待时间,bugu-mongo提供了并行查询机制。 比如:一个网页上要展示3部分数据,需要查询3次数据库,假设每个查询所需要的时间分别是500ms、600ms、700ms,如果依次执行3个查询,总共需要1800ms时间;如果使用bugu-mongo的并行查询机制,3个查询同时执行,则只需要700ms就能返回全部数据。 要实现并行查询,需要使用Para
-
问题内容: 我有几个查询,其中大多数是: 和 由于它们都是一个范围,因此在col和date上使用未聚类的b +树索引会是加快查询速度的一个好主意吗?还是哈希索引?还是没有索引会更好? 问题答案: 在 过滤谓词上 用作 日期范围条件 的列上创建 INDEX 应该很有用,因为它将执行 INDEX RANGE SCAN 。 这是有关如何在Oracle中创建,显示和阅读EXPLAIN PLAN 的演示。
-
问题内容: 在大约2011年3月,我测试了GAE(Java版本)作为大规模并行计算的潜在平台。该日期很重要,因为GAE一直在发展。我发现该应用程序被有效地限制在大约43.2倍的计算吞吐量上。 是否有人成功使用GAE进行大规模并行计算或获得了更高的计算增益? 出于这个问题的目的,我将任意定义大规模并行计算,以表示大于1000倍的计算吞吐量。 我使用了一个桌面客户端,该客户端实例化了多个线程来访问UR
-
本文向大家介绍Oracle并行操作之并行查询实例解析,包括了Oracle并行操作之并行查询实例解析的使用技巧和注意事项,需要的朋友参考一下 Oracle数据库的并行操作特性,其本质上就是强行榨取除数据库服务器空闲资源(主要是CPU资源),对一些高负荷大数据量数据进行分治处理。并行操作是一种非确定性的优化策略,在选择的时候需要小心对待。目前,使用并行操作特性的主要有下面几个方面: Parallel
-
问题内容: 我有以下方法: 在这里,我依次调用三种方法,这依次命中数据库并获取我的结果,然后对从数据库命中获得的结果进行后处理。我知道如何通过使用并发调用这三种方法。但是我想用Java 8 来实现。有人可以指导我如何通过并行流实现相同目标吗? 编辑 我只想通过Stream并行调用方法。 问题答案: 您可以利用这种方式: