
Vearch 是一个分布式向量搜索系统,可以用来计算向量相似度,或用于机器学习领域,如:图像识别、视频识别或自然语言处理等各个领域。
本系统基于 Faiss 实现, 提供了快速的向量检索功能。
提供类似 Elasticsearch 的 Restful API 可以方便地对数据及表结构进行管理查询等工作。
架构
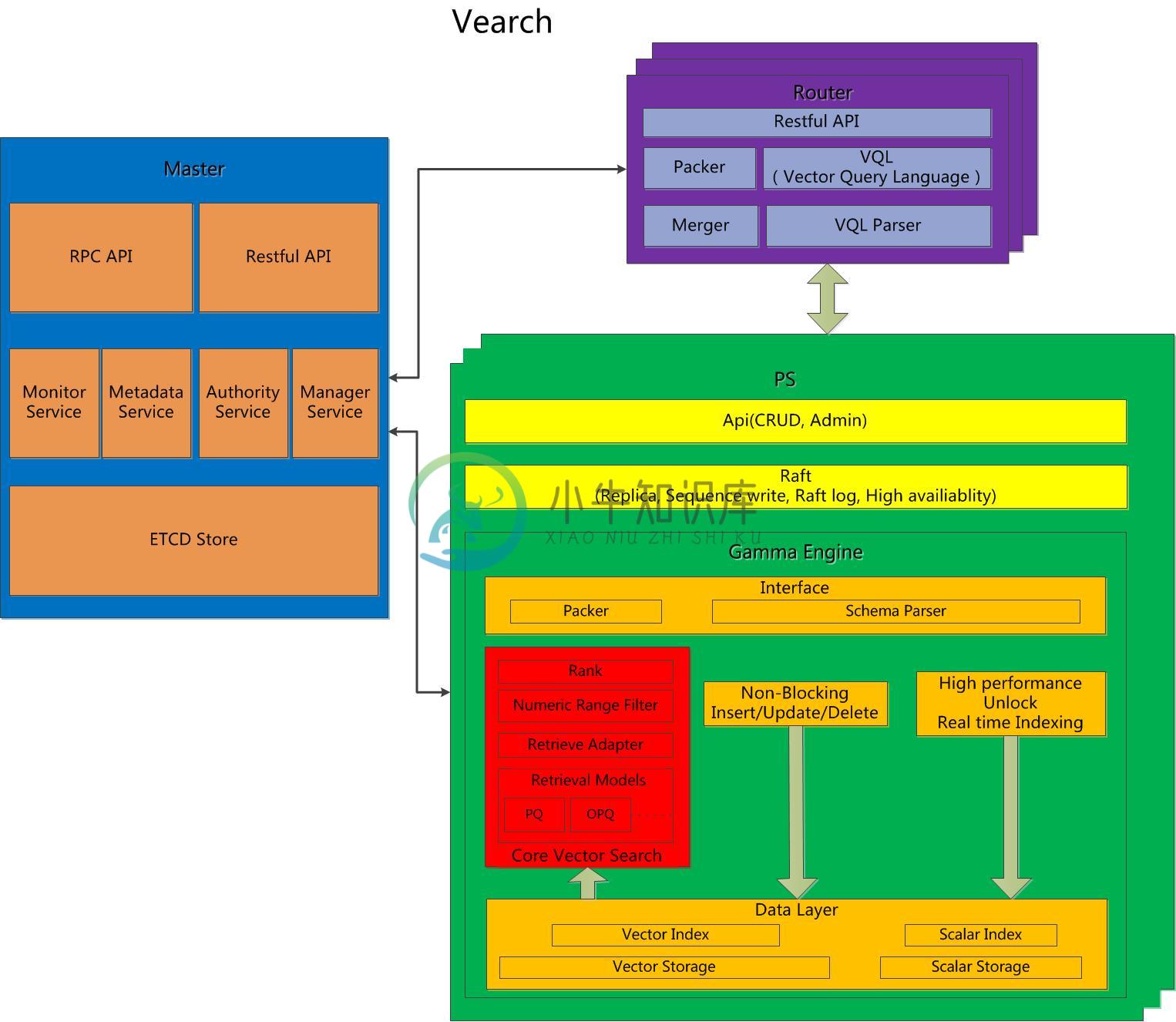
-
简介:Vearch 是一个分布式向量搜索系统,可用来存储、计算海量的特征向量,为 AI 领域的向量检索提供基础系统支撑与保障。该系统能够广泛地应用于图像, 音视频和自然语言处理等各个机器学习领域。 本篇文章主要是介绍Vearch v3.2.0版本的更新内容,如果你是第一次接触Vearch,可以在这里看到更多关于Vearch的介绍文档Wiki。另外提供Vearch一键式安装脚本百度网盘, 提取码:
-
源码编译安装vearch 官网的链接在这里,大部分是依据官网,只是加了说明,在centos7.9.2009系统下安装vearch-0.3.1(或3.1.0) 1 安装依赖包 vearch需要这些依赖(摘自github网站): CentOS, Ubuntu and Mac OS are all OK (recommend CentOS >= 7.2),cmake required Go >= 1
-
Vearch(https://github.com/vearch/vearch) 是一个可以在海量特征中快速检索出相似结果的弹性分布式系统。具体的介绍可以参考vearch的官方文档https://vearch.readthedocs.io/zh_CN/latest/overview.html 1、安装vearch的依赖 CentOS, Ubuntu and Mac OS are all OK (r
-
参考:《官方部署文档》https://github.com/vearch/vearch/blob/master/docs/Deploy.md 1 部署 1.1 安装 vearch 在24和107两台机器上分别 安装vearch 及其环境。 安装参考:《图像检索引擎vearch安装与测试使用 》:https://blog.csdn.net/u012052268/article/details/103
-
环境搭建和启动 sudo docker run -it -p 8817:8817 -p 9001:9001 -p 2378:2378 -p 2390:2390 -p 2370:2370 -p 6062:6062 -p 8818:8818 -p 6061:6061 -p 8081:8081 -p 8898:8898 -p 8899:8899 -p 6060:6060 -v $PWD/config.
-
知乎:https://zhuanlan.zhihu.com/p/364923722 CSDN:https://blog.csdn.net/haima1998/article/details/119781638?ops_request_misc=&request_id=&biz_id=102&utm_term=%E5%90%91%E9%87%8F%E6%A3%80%E7%B4%A2%E5%B7%A5
-
图像检索引擎vearch安装与测试使用 https://blog.csdn.net/u012052268/article/details/103264626 京东分布式向量检索系统 vearch 如何一招搞定海量特征存储与计算? https://www.infoq.cn/article/gxYOJ0m5rpMpIEwvz9GR 分布式向量搜索系统Vearch的GPU版使用方法 https://zh
-
为提高可伸缩性,Sphnix提供了分布式检索能力。分布式检索可以改善查询延迟问题(即缩短查询时间)和提高多服务器、多CPU或多核环境下的吞吐率(即每秒可以完成的查询数)。这对于大量数据(即十亿级的记录数和TB级的文本量)上的搜索应用来说是很关键的。 其关键思想是对数据进行水平分区(HP,Horizontally partition),然后并行处理。 分区不能自动完成,您需要 在不同服务器上设置Sp
-
在Web一章中,我们提到MySQL很脆弱。数据库系统本身要保证实时和强一致性,所以其功能设计上都是为了满足这种一致性需求。比如write ahead log的设计,基于B+树实现的索引和数据组织,以及基于MVCC实现的事务等等。 关系型数据库一般被用于实现OLTP系统,所谓OLTP,援引wikipedia: 在线交易处理(OLTP, Online transaction processing)是指
-
主要内容:一、从一个新闻门户网站案例引入,二、推算一下你需要分析多少条数据?,三、黄金搭档:分布式存储+分布式计算这篇文章聊一个话题:什么是分布式计算系统? 一、从一个新闻门户网站案例引入 现在很多同学经常会看到一些名词,比如分布式服务框架,分布式系统,分布式存储系统,分布式消息系统。 但是有些经验尚浅的同学,可能都很容易被这些名词给搞晕。所以这篇文章就对“分布式计算系统”这个概念做一个科普类的分析。 如果你要理解啥是分布式计算,就必须先得理解啥是分布式存储,现在我们从一个小例子来引入。 比如说
-
被别人指出问题时,别管别人能不能做到,看别人说的对不对,然后完善自己。别人能不能做到是别人的事情,自己能不能做到关系到自己能否发展的更好。——hustlihaifeng Go语言号称是互联网时代的C语言。现在的互联网系统已经不是以前的一个主机搞定一切的时代,互联网时代的后台服务由大量的分布式系统构成,任何单一后台服务器节点的故障并不会导致整个系统的停机。同时以阿里云、腾讯云为代表的云厂商崛起标志着
-
数据存储容量的问题。 数据读写速度的问题。 数据可靠性的问题。 几种常见 RAID 的对比|名称|优点|缺点| |------|------|------| |RAID 0|使用 N 块磁盘的 RAID 0,将数据从内存写入磁盘时,将数据分成 N 块,并发写入,读取同理。所以,读写速度是单盘的 N 倍。|任何一块盘损坏,数据完整性破坏,数据不可用。| |RAID 1|数据写入磁盘时,将一份数据同时
-
本文向大家介绍solr 布尔搜索,包括了solr 布尔搜索的使用技巧和注意事项,需要的朋友参考一下 示例 +firstname:john +surname:doe 匹配名字为john且姓氏为doe的文档。+前缀表示搜索词必须出现(AND)。 +firstname:john -surname:doe 匹配名字为john而名字不是doe的文档。-前缀表示不得出现搜索词(否)。 +firstname:j