
Pinot 是一个实时分布式的 OLAP 数据存储和分析系统。LinkedIn 使用它实现低延迟可伸缩的实时分析。Pinot 从离线数据源(包括 Hadoop 和各类文件)和在线数据源(如 Kafka)中攫取数据进行分析。Pinot 被设计是可以进行水平扩展的。
Pinot 特别适合这样的数据分析场景:分析模型固定,数据只追加以及低延迟,以及分析结果可查询。
关键特性:
面向列的数据库,提供多种压缩模式,如运行长度、固定比特长度
可插入式的索引技术,包括可排序索引、Bitmap 索引和反向索引
可根据查询和段元数据对查询和执行进行优化
近乎实时的从 Kafka 获取数据,以及批量从 Hadoop 获取数据
类 SQL 的语言支持查询、聚合、过滤、分组、排序和去重
支持多值字段
水平伸缩以及容错
Pinot 非常使用用来查询时许数据以及大维度的数组。
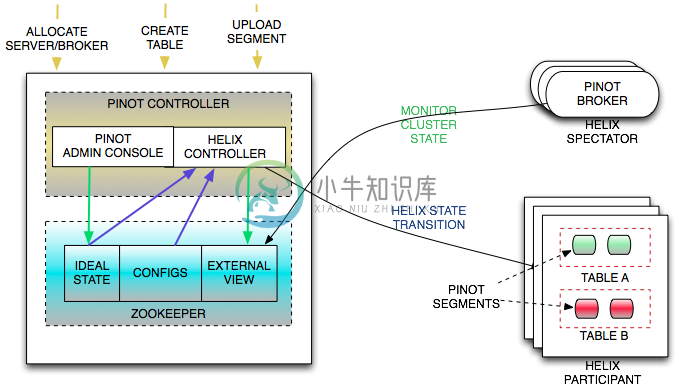
Pinot 的组件架构:
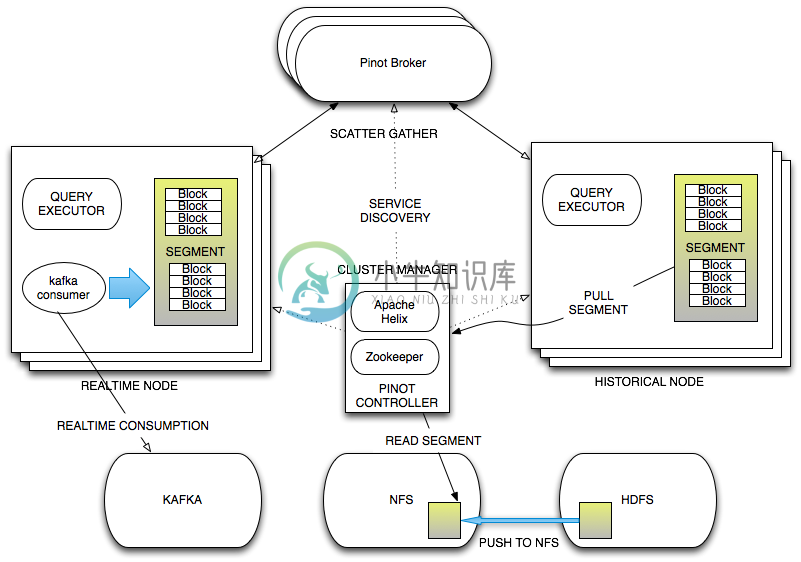
Pinot 核心概念:
示例查询:
/*Total number of documents in the table*/
select count(*) from baseballStats limit 0
/*Top 5 run scorers of all time*/
select sum('runs') from baseballStats group by playerName top 5 limit 0
/*Top 5 run scorers of the year 2000*/
select sum('runs') from baseballStats where yearID=2000 group by playerName top 5 limit 0
/*Top 10 run scorers after 2000*/
select sum('runs') from baseballStats where yearID>=2000 group by playerName limit 0
/*Select playerName,runs,homeRuns for 10 records from the table and order them by yearID*/
select playerName,runs,homeRuns from baseballStats order by yearID limit 1-
一、编译代码 git clone git@github.com:apache/incubator-pinot.git cd incubator-pinot mvn install package -DskipTests -Pbin-dist -DdownloadSources -DdownloadJavadocs -Drat.numUnapprovedLi
-
1、安装docker(分步执行,有些命令需要确认) apt-get remove docker docker-engine docker.io containerd runc apt-get update apt-get install ca-certificates curl gnupg lsb-release
-
1. Introduction to Pinot Pinot 是一个实时分布式的 OLAP 数据存储和分析系统。LinkedIn 使用它实现低延迟可伸缩的实时分析。Pinot 从离线数据源(包括 Hadoop 和各类文件)和在线数据源(如 Kafka)中攫取数据进行分析。Pinot 被设计是可以进行水平扩展的。 2. What is it for (and not)? 2.1 Pinot 适用于这
-
下面的配置由官网说明翻译过来: Table Config 示例表配置和描述 下面显示了一个示例表配置,其中的子节被重新排序。这些小节将在下面的小节中分别进行描述。功能特定文档的进一步链接到可用的地方。 tableName : 应该只包含字母数字字符、连字符(' - ')或下划线(' _ ')。虽然使用双下划线(' __ ')是不允许的,并保留在Pinot的其他功能。 tableType : 指示表
-
本文中的伪分布式指的是pinot架构中每个组件controller、server、broker分别启动组成集群 1、进入linux 的pinot目录的bin文件夹下 2、pinot启动controller,使用自己的zookeeper集群非pinot中的zookeeper nohup ./start-controller.sh -clusterName PinotCluster -control
-
本文向大家介绍Django文件存储 自己定制存储系统解析,包括了Django文件存储 自己定制存储系统解析的使用技巧和注意事项,需要的朋友参考一下 要自己写一个存储系统,可以依照以下步骤: 1.写一个继承自django.core.files.storage.Storage的子类。 2.Django必须可以在无任何参数的情况下实例化MyStorage,所以任何环境设置必须来自django.conf.
-
我正在尝试执行下面的distcp命令,但是它抛出了异常: 抛出的异常如下: 我正在尝试执行下面的distcp命令,但是它抛出了异常: Hadoop distcp date _ load = 201901 * wasb://de v3-spark @ cluster dev . blob . core . windows . net/Luiz/producao/performance/perform
-
一、介绍 HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。 二、HDFS 设计原理 2.1 HDFS 架构 HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成: NameNode : 负责执行有关 文件系统命名空间 的操作,例如打开,
-
Gradle如何在本地文件系统上存储下载的jar文件?Maven将它们存储在下的目录中,但Gradle将它们存储在哪里?我检查了那里的文件夹,但只看到编译过的脚本。
-
本文向大家介绍深入分析SQL Server 存储过程,包括了深入分析SQL Server 存储过程的使用技巧和注意事项,需要的朋友参考一下 Transact-SQL中的存储过程,非常类似于Java语言中的方法,它可以重复调用。当存储过程执行一次后,可以将语句缓存中,这样下次执行的时候直接使用缓存中的语句。这样就可以提高存储过程的性能。 Ø 存储过程的概念 存储过程Procedure是一组为
-
FILESYSTEM AND STORAGE DEVICE MANAGEMENT 如果您来自 Windows 环境,那么 Linux 表示和管理存储设备的方式在您看来将非常不同。您已经看到,文件系统没有驱动器的物理表示形式,就像 Windows 中的 C:、D:或 E:系统一样,而是有一个文件树结构,其顶部或根目录是/。本章将介绍 Linux 如何表示存储设备,如硬盘驱动器、闪存驱动器和其他存储设
-
谢了。
-
SOP基于spring cloud,因此会涉及到网关路由。但是开发者不用去配置文件定义路由的隐射关系,SOP帮你解决了这个问题。 获取路由信息 网关启动成后会触发一个事件,代码见:com.gitee.sop.gatewaycommon.config.AbstractConfiguration.listenEvent 这个事件会取拉取微服务中提供的路由信息 下面以nacos为例,介绍拉取路由过程 1